-
- 1.1. Convolution Neural Networks
- 1.2. Sparsity
- 1.3. Transformers
- 1.4. Attribute Recognition
- 1.5. Classification
- 1.6. Object Detection
- 1.7. Knowledge Distillation
- 1.8. Network Communication
- 1.8.1. Gradient Compression
- 1.9. OPs in Network
- 1.9.1. Batch Normalization
- 1.9.2. Group Normalization
- 1.10. Compute Efficiency
- 1.11. Memory Efficiency
- 1.12. Compression
- 1.13. Parallelism
- 1.13.1. Data Parallel
- 1.13.2. Pipeline Parallelism
- 1.13.3. Parallelization Strategies
- 1.14. Quantization
- 1.15. Network
- 1.16. Resource Management
- 1.17. Parameter Server
-
- 3.1. [CS179: GPU Programming](#CS179:GPUProgramminghttp:courses.cms.caltech.educs179)
- 3.2. [ CS231n: Convolutional Neural Networks for Visual Recognition](#CS231n:ConvolutionalNeuralNetworksforVisualRecognitionhttp:cs231n.stanford.edu)
- 3.3. [CSE 599W: Systems for ML](#CSE599W:SystemsforMLhttp:dlsys.cs.washington.eduschedule)
- 3.3.1. [Introduction to Deep Learning](#IntroductiontoDeepLearninghttp:dlsys.cs.washington.edupdflecture1.pdf)
- 3.3.2. [Lecture 1:Distributed Training and Communication Protocols](#Lecture1DistributedTrainingandCommunicationProtocolshttp:dlsys.cs.washington.edupdflecture11.pdf)
- 3.3.3. [Lecture 3: Overview of Deep Learning System](#Lecture3:OverviewofDeepLearningSystemhttp:dlsys.cs.washington.edupdflecture3.pdf)
- 3.3.4. [Lecture 5: GPU Programming](#Lecture5:GPUProgramminghttp:dlsys.cs.washington.edupdflecture5.pdf)
- 3.4. https://ucbrise.github.io/cs294-ai-sys-sp19/
-
- 4.1. Deep Learning
- 4.1.1. Backpropation
- 4.1. Deep Learning
-
- 5.1. TIMM
- 5.2. [Tensor Comprehensions 2018.2.13 Facebook AI Research Technical Report](#TensorComprehensions2018.2.13FacebookAIResearchTechnicalReport)
- 5.3. TensorFlow RunTime (TFRT)
- 5.4. OneFlow
- 5.5. [Pytorch](#Pytorch)
- 5.5.1. JIT
- 5.6. [Tensorflow](#Tensorflow)
- 5.7. [Acme: A Research Framework for Distributed Reinforcement Learning(arXiv: June 1 2020)](#Acme:AResearchFrameworkforDistributedReinforcementLearninghttps:arxiv.orgpdf2006.00979.pdfarXiv:June12020)
- 5.8. [Launchpad](#Launchpad)
- 5.9. Reverb(2020)
- 5.10. [Weld(Standford)](#Weldhttps:www.weld.rsStandford)
- 5.11. Table Data Storage
-
- 11.1. Memory Profiling
- 11.2. Communication Profiling
-
- 13.1. CUDA
ML Papers:
CNN Concepts Gradient-Based Learning Applied to Document Recognition(1996?) : Notes, 在 OCR 领域里,用不需要像之前的方法一样,需要很多人工介入/设计/处理。对字母的大小,变体等有鲁棒性。更多依赖于从数据里自动学习,而非手工针对任务做的启发式设计。这样一个统一结构的模型可以代替过去好几个独自设计的模块
ImageNet Classification with Deep Convolutional Neural Networks(2010) :用 deep convolutional neural network 在 2010 年的 ImageNet LSVRC 比赛上分类 1200百万高清(当时的)图片。使用的网络有6000万参数和65万神经元,引入了 dropout 来防止过拟合。 Notes
Going Deeper with Convolutions (ILSVRC 14) Notes
Rich feature hierarchies for accurate object detection (2014) Notes
Deformable Convolutional Networks (ICCV 2017) Notes
Accelerating Sparse Approximate Matrix Multiplication on GPUs, Notes
Attention is All you need (Google Brain 2017) My Notes
ViT: Vision Transformer: An Image is worth 16x16 Words: Transformers for Image Recognition at Scale (2021.6.3) My Notes。影响力巨大,可以看到后续 CV,多模态都用 ViT 了,非常好的挖坑之作
ViT FRCNN(2021.12): 运用到检测上
SETR(2021.12): 运用到分割上
DETR: ViT 在目标检测上的应用
Scaling Vision Transformer: 把 ViT 的参数量搞大
SwinTransformer:多尺度的 transformer,更适合做视觉领域
lightseq: Accelerated Training for Transformer-based Models on GPUs(2021.10): 从工程角度出发实现 transformer 的训练和推理加速。My Notes 源码阅读分析
Masked Autoencoders Are Scalable Vision Learners [My Notes](./papers/transformer/Masked-AutoEncoders-Are-Scalable Vision Learners.md):第一次在分类任务上,让生成式模型比判别式模型要好。
Self-Attention Does Not Need O(n^2) Memory(2021.12) My Notes
Deforma2ble DETR: Deformable Transformers for End to End Object Detections(ICLR 2021)
Competition-Level Code Generation with AlphaCode. My Notes
FLASHATTENTION: Fast and Memory-Efficient Exact Attention with IO-Awareness. (2022) My Notes
SimA: Simple Softmax-free Attention for Vision Transoformers:
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning My Notes
FlashDecoding for long-context inference (2023.10) My Notes
FlashDecoding++(2023.11) My Notes
Blockwise Parallel Transformer for Large Context Models My Notes
Hierarchical Feature Embedding for Attribute Recognition (2020.5.23) My Notes
Deep Unsupervised Learning using Noneequilibrium Thermodynamics (2015) : 最早提出
Denoising Diffusion Probabilistic Models(DDPM) (2020): 新高度
InstructPix2Pix(2022): 给定输入图像和告诉模型需要做什么的文本描述,模型就能遵循描述指令来编辑图像
OpenAI DALLE2 和Google Imagen 都是半开源
High-Resolution Image Synthesis with Latent Diffusion Models(CVPR 2022, Stable Diffusion模型的论文, v1.4) runwayml 是背后参与的一家公司。可以做Erase and replace 的视频公司,AIGC 只是他们能力链条里的一部分. My Notes
Stable Diffusion 代码:https://huggingface.co/CompVis/stable-diffusion 高质量数据集 LAION 的加持。 支持:txt2image, image+txt2image, erase and replace
LAION-5B: A New Era of Open Large-Scale Multi-Modal Datasets(2022.5) My Notes
What are Diffusion Models? My Notes
HuggingFace上对于Stable Diffusion 的介绍。 My Notes
Imagen: Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding(2022.5). DrawBench 上对 VG-GAN+CLIP, Latent Diffusion Models, DALL-E-2 等做了评价
Prompt-to-Prompt Image Editing with Cross-Attention Control
Classifier-Free Diffusion Guidance(2022.7.26)
Imagic: Text-Based Real Image Editing with Diffusion Models
Character-Aware Models Improve Visual Text Rendering(2022.12.20): 主要解决视觉拼写方面的问题,提高图像生成模型渲染高质量视觉文本的能力
Muse: Text-To-Image Generation via Masked Generative Transformers: FID(quality/diversity) 和 CLIP(text-image alignment) 的分数很高;比其他模型快;一个模型支持 inpainting、outpainting [My Notes](papers/AIGC/muse.md
CLIP(Constrative Language-Image Pretraining), DALLE, Diffusion Model 之间的异同点?
CLIP: Constrative Language-Image Pretraining(2021.1.5): My Notes, Intro : Leanrning Transferable Visual Models From Natural Language Supervision
EVA-CLIP: Improved Training Techniques for CLIP at Scale(2023.3.27)
Speed Is All You Need: On-Device Acceleration of Large DIffusion Models via GPU-Aware Optimizations: My Notes (Google 2023 4.21)
ImageBind: One Embedding Space To Bind Them All(2023.5.9) My Notes
Q-Diffusion: Quantizing Diffusion Models (2023.2.10) My Notes
Decompose and Realign: Tackling Condition Misaglignment in Text-to-Image Diffusion Models(6.26 2023)
Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation (2023.3.17) My Notes
RAPHAEL: Text-to-Image Generation via Large Mixture of Diffusion Paths(2023.5.29) My Notes
ControlNet 1.1 My Notes
TryOnDiffusion: A Tale of Two UNets() My Notes
苹果的 Stable Diffusion with Core ML: https://github.com/apple/ml-stable-diffusion My Notes
mlc-llm: Enable everyone to develop, optimize and deploy AI models natively on everyone's devices.
DALL*E3 Intro
Fast R-CNN: (2015) 提出用一个统一的网络来训练 R-CNN,而不是之前的三个阶段,不同的网络. My Notes
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (2016):提出了 Region Proposal Network (RPN),和检测网络共享图片卷积特征,因此 region proposal 的代价非常小。 My Notes
End-to-End Object Detection with Transformers : (2020 FaceBook Research) My Notes
Focal Loss for Dense Object Detection:(2017): My Notes, 第一次解决了一阶段检测的精度问题,为了使用这个loss算法,自己构造了 RetinaNet,精度超越了faster rcnn
DETR(DEtection TRansformer): End to end object detection with transformers (2020) My Notes
Model compression(2006):ensemble 模式下的多个模型的知识,可以压缩到一个模型里
蒸馏算是从上述模型压缩进一步发展而来的
Contrastive Representation Distillation (2020) My Notes
Search to Distill: Pearls are Everywhere but not the Eyes(2020) 除了参数外,还考虑了网络结构的蒸馏,结果发现好的老师无法教出在各方面都很优秀的学生 My Notes
A Gift from Knowledge Distillation: Fast optimization, Network Minimization and Transfer Learning (2017 韩国): My Notes
Distilling the Knowledge in a Neural Network Geoffrey Hinto 和 Jeff Dean(2015): 第一次提出模型蒸馏的概念及方法, 可以通过蒸馏让小模型能力提升很高(是语音场景)。提出了一种新的 ensemble 方法 My Notes
Flare: Flexible In-Network Allreduce 2021-6-29: SwitchML 不灵活,他们设计了一个交换机:by using as a building block PsPIN, a RISC-V architecture implementing the sPIN programming model.
In-Network Aggregation,slides, Video 笔记 18 年的
paper: Scaling Distributed Machine Learning with In-Network Aggregation
NVIDIA SHARP: 看起来跟上述开源方案的非常相似,对比见这里. 16 年就发论文了
NetReduce: RDMA-Compatible In-Network Reduction for Distributed DNN Training Acceleration : 华为做的,需要硬件实现,好处是不需要修改网卡或交换机。
MPI: 并行编程中的一种编程模型, Message Passing Interface
PMI: 并行编程中的Process Management System
InfiniBand, Remote Direct Memory Access(RDMA), Socket, Ethernet
GRACE: A Compressed Communication Framework for Distributed Machine Learning (2021) : s. We instantiate GRACE on TensorFlow and PyTorch, and implement 16 such methods. Finally, we present a thorough quantitative evaluation with a variety of DNNs (convolutional and recurrent), datasets and system configurations. We show that the DNN architecture affects the relative performance among methods. Interestingly, depending on the underlying communication library and computational cost of compression / decompression, we demonstrate that some methods may be impractical. GRACE and the entire benchmarking suite are available as open-source.
Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training(2017.12,2020-6-23 modify) : In this paper, we find 99.9% of the gradient exchange in distributed SGD is redundant . 它就是在 GRACE 框架基础上开发的一类算法
Code: GRACE: A Compressed Communication Framework for Distributed Machine Learning: is an unified framework for all sorts of compressed distributed training algorithms
GC3: An Optimizing Compiler for GPU Collective Communication(ASPLOS 23)My Notes . 对应的库叫 msccl, My Notes
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift(2015): 用了 BN 后学习率可以调大,初始化过程更鲁棒。也有 regularization 作用,可以一定程度代替 drop out。 faster training and high performance. My Notes
Layer Normalization (2016.7) : My Notes : 想在 RNN 里引入类似 BN 的方法,来让训练速度提升,收敛的更快
Norm matters: efficient and accurate normalization schemes in deep networks(2019 ): suggest several alternatives to the widely used L2 batch-norm, using normalization in L1 and L∞ space
Sync Batch Normalization(syncbn): Source Code Notes
Sys Papers:
AdderNet: Do We Really Need Multiplications in Deep Learning
1 Bit Adam () My Notes: 实现了 GPU 上的 error compensated Adam preconditioned momentum SGD。减少了 GPU 和 CPU间通信,还加速了优化器的计算
Backprop with approximate activations for memory-efficient network training (arXiv 2019)
Don't waste your bits! squeeze activations and gradients for deep neural networks via tinyscript (ICML, 2020)
上面这俩都是对所有元素采用同样的量化方法
Gist: Efficient data encoding for deep neural network training 2018
ZeRO:大模型训练的标配,把 DDP 模式下冗余的显存都给分片了,需要时从别人那里要过来 My Notes。里面建模了参数量为t下,adam这类优化器需要 12(4*3)t 的显存。激活值计算可以参考 megatron v3。
FSDP in fairscale: lightning used this
ZeRO-offload 2021.1.18 My Notes : 基于 ZeRO-2,把 NLP中 Adam 优化器实现在了 CPU 上,这样能 offload 优化器的内存和计算,这个是大头
Capuchin: Tensor-based GPU Memory Management for Deep Learning(2020 ASPLOS) , My notes: 目标是为了节省内存,能训更大的 batchsize。内存管理到了 tensor 级别,而且是模型/计算图无关。在运行时 profile 出来是 swap 合适还是 recompute 合适。有 prefetch / evict 机制。但是不支持动态图(dynamic model)和 dynamic shape
Dynamic tensor rematerializatio(2020): 是 Checkpoint 核心是发明的这个线上算法不需要提前知道模型信息,就能实时产出一个特别好的 checkpointing scheme。这种在线方法能处理静态和动态图。算是陈天奇提供的方法的checkpoint 方法的后续:动态做,更优。My Notes, Source Code Notes
Pushing deep learning beyond the gpu memory limit via smart swapping. (2020)
Tensor-based gpu memory management for deep learning. (2020)
ActNN: Reducing Training Memory Footprint via 2-Bit Activation Compressed Training (2021-7-6) My notes, source code notes
Low-Memory Neural Network Training: A Technical Report(2019-4-24)
Gradient/Activation Checkpointing
Visual Gifs to show gradient checkpointing
Binaryconnect: Training deep neural networks with binary weights during propagations. (2015)
ZeRO Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning(2021.4.16), My Notes : 在 ZeRO 基础上,把显存交换扩展到了 NVMe 硬盘上。ZeRO 系列的好处是不需要改用户的代码。ZeRO 系列主要解决内存问题(Memory wall)
PatrickStar: Parallel Training of Pre-trained Models via Chunk-based Memory Management: 实现基于 Transformer 的 NLP 里预训练场景下,高效的 swap 实现机制,让模型训练更高效,能够最大程度复用不会同时存在的 chunks My Notes, Source Code Notes
ZeRO++: Extremely Efficient Collective Communication for Giant Model Training(2023.6.16)My Notes
Fast, Flexible Allocation for NVIDIA CUDA with RAPIDS Memory Manager(2020.12.8) My Notes
Deep compression: Compressing deep nerual networks with pruning, trained quantization and huffman coding. (ICLR, 2016 Song Han)
Deep gradient compression: Reducing the communication bandwidth for distributed training. (ICLR, 2018 Songhan)
MONet: Memory optimization for deep networks(ICLR 2021): 与DTR几乎同期,优势在于大部分逻辑python实现,但是因为要直接用scheduler生成fwd和bwd的python调用代码来串联各个op,而里面没完全支持所有的pytorch python语法,所以用起来麻烦
MONeT: Memory optimization for deep networks(ICLR 2021) : 发在了 Learning Representation 上,说明不是系统的改进,是算法的改进。My Notes
- MONeT: Memory Optimization for Deep Networks:https://github.com/utsaslab/MONeT
Elan: Towards Generic and Efficient Elastic Training for Deep Learning(2020) My Notes
TRANSFORM: An Efficient Fault-Tolerant System for Training LLMs(2023.10) My Notes
LLM Powered Autonomous Agents My Notes
MemGPT(Berkeley):
Generative Agents: Interactive Simulacra of Human Behavior(2023.4.7) My Notes
Language Model beats Diffusion -- Tokenizer is Key to Visual Generation(MAGVIT-v2)(2023.10.9 Google) My Notes: 是一个共用图片视频和文本 vocabulary 的 tokenizer 。第一次让 LLM 在 video generation 也能打了
Sora(2024.2.15) My Notes
ALBEF(ALign the image and text representations BEfore Fusing): Align before Fuse: Vision and Language Representation Learning with Momentum Distillation(Salesforce Research)2021.10) My Notes
Flamingo: a Visual Language Model for Few-Shot Learning(2022.4): 类似多模态领域的 GPT3 时刻,结合预训练好的视觉和语言两个模型,使用文本数据训练后,就可以有 few shot 能力。有开源的版本。DeepMind 博客里介绍的标题是:Tackling multiple tasks with a single visual language model
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models My Notes: 在 Flaminggo 基础上,
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models(KAUST)
InstructBLIP(Salesforce)
VisualGLM(智谱 AI)
相关库: LAVIS(BLIP, Salesforcee): A Python deep learning library for LAnguage-and-VISion intelligence research and applications
Visual Instruction Tuning(2023.4 Wisconsin-Madison & Microsoft)My Notes. 模型叫:LLaVA(火山、岩浆):Large Language and Vision Assistant. Visual Instruction tuning towards large language and vision models with GPT-4 level capabilities(微软和 Wisconsin-Madison)。在 github 首页上有很多相关的论文和 notes 可以看。
Improved Baselines with Visual Instruction Tuning (2023 10.5): LLaVA 1.5 My Notes。 在一的基础上做了简单修改,使用公开数据集,在一台A100机器上训练一天就能达到很好的效果
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond(2023.9.14 Alibaba)
Kosmos-2:(Microsoft 2023): 主要是支持了 boudning box 和 grounding text
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic(sensetime 2023, 7): 非常简单,没有加额外的词表,位置编码前后检测模块。所有输入输出都是自研语言的格式。比较好奇里面的位置是如何训练和计算的。数据集里有带了 box 的数据 My Notes
NExt-GPT: Any-to-Any Multimodal LLM(2023.9.11) My Notes
Gemini: A Family of Highly Capable Multimodal Models(2023.12.11) My Notes
DISTMM: Accelerating Distributed Multimodal Model Training(2024) My Notes
InternVL: Sclaing up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks My Notes
webdataset My Notes
Megatron-LM: Training Multi-Bilion Parameter Language Models Using Model Parallelism (2020.3): My Notes:megatron v1, 引入了 tensor 切分(Attention 里的 Proj 和 MLP 里的两个 Linear)
Efficient Large-Scale Language Model Training on GPU Clusters (2021.4 NVIDIA, Standford, Microsoft): megatron v2, 引入了 pp 切分。里面探讨了 tp、pp、ddp 的各自特点。如何结合 tp、pp 多种并行方式,让特定 batchsize 的大transformer 模型,高通吐地运行起来。阅读笔记
Reducing Activation Recompution in Large Transformer Models(Megatron v3: 2022.5.10) My Notes: 里面有详细的各种并行情况下激活值的计算,介绍了 sp 和 selective recomputation, 核心目的是进一步减少 Transformer 里的激活值内存
LightSeq: Sequence Level Parallelism for Districuted Training of Long Context Transformers(2023.10.5) My Notes
Ring Attention with Blockwise Transformers for Near-Infinite Context (2023.11.27)(Hao Liu, berkeley) My Notes
DeepSpeed Ulysses: System Optimizations for Enabling Training of Extreme Long Sequence Transformer Models (2023.10) My Notes
PyTorch Distributed: Experiences on Accelerating Data Parallel Training(2020.6.28) My Notes
Automatic Cross-Replica Sharding of Weight Update in Data-Parallel Training(2020-4-28) : 提出了 weights 的自动切分方法,通过高效的通信原语来同步,使用静态分析计算图的方法,应用于 ADAM 或 SGD
GSPMD: General and Scalable Parallelization for ML Graphs(2021-5-10) (for transformers) :是基于XLA上的扩展,针对 transformer来做的
首先是模型并行(Model Parallel),然后为了提高模型并行里的效率,就有了流水并行
PipeDream: Generalized Pipeline Parallelism for DNN Training(SOSP'19)
GPipe: Efficient training of giant neural networks using pipeline parallelism(NIPS 2019):
Memory Efficient Pipeline-Parallel DNN Training(ICML 2021): 主要是提出了 PipeDream-2BW: 自动切分模型,double buffering of weights。算是在 PipeDream基础上进行提高
fairscale pipeline parallelism source code
Zero Bubble Pipeline Parallelism (2023.11.30) My Notes
Beyond Data and Model Parallelism for Deep Neural Networks(2018)
Defined a more comprehensive search space of parallelization strategies for DNNs called SOAP, which includes strategies to parallelize a DNN in the Sample, Operation, Attribute, and Parameter dimesions. Proposed FlexFlow, a deep learning framework that uses guided randomized search of the SOAP spaceto find a fast parallelization strategy for a specific parallel machine. To accelerate this search, FlexFlow introduces a novel execution simulator that can accurately predict a parallelizaiton strategy's performance.
jiazhihao的,里面有一个模拟器,能预测出速度
The Internal State of an LLM Knows When It's Lying (2023.10) My Notes : 读取模型内部的激活值,然后根据分类器来分类,方法叫 Statement Accuracy Prediction, based on Language Model Activations(SAPLMA)
Representation Engineering: A Top-Down Approach to AI Transparency(2023.10.10) My Notes: 开源了 Linear artificial Tomography(线性人工断层摄影术)。可以监控、控制最后行为
Language Models(Mostly) Know What They Know(2022.11.21 Anthropic): 开放问题任务上让模型自我评估,根据模型的 Loss 或者 Entropy 来判断模型知道什么,通过模型答案的分布来判断是否有幻觉(不确定,
Studying Large Language Model Generalization with Influence Funtions(Anthropic)
The Platonic Representation Hypothesis My Notes
Mapping the Mind of a Large Language Model (Anthropic 2024.5.21)
8-bit inference with tensorrt(2017.5.8)
And the bit goes down: Revisiting the quantization of neural networks. (ICLR 2020)
MQBench Towards Reproducible and Deployable Model Quantization Benchmark (NIPS 2021 workshop) 提出了一套验证量化算法在推理上可复现性和可部署性的Benchmark集合,指出了当前学术界和工业界之间的 Gap。My Notes
Google. Gemmlowp: building a quantization paradigm from first principles 里面提到了量化感知训练的方法
GradientFlow: Optimizing Network Performance for Distributed DNN Training on GPU Clusters(cs.DC 2019)
Proposed a communication backend named GradientFlow for distributed DNN training. First we integrate ring-based all-reduce, mixed-precision training, and computation/communication overlap. Second, we propose lazy allreduce to improve network throughput by fusing multiple communication operations into a singe one, and design coarse-grained sparse communication to reduce network traffic by transmitting important gradient chunks.
Scaling Distributed Machine Learning with the Parameter Server(2013?)
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks(ICLR 最佳论文 2019): 著名的彩票假设,指出了新的 pruning 方法,让pruning之后的网络能从头训练,不掉点 My Notes
Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers Notes
Few-Shot Learning: Query samples are never seen before. Query samples are from unknown classes.
(GPT-1(Improving Language Understanding by Generative Pre-Training))(2018.6): 0.117B, 5GB data,Generative 这种有用 [./papers/NLP/gpt1.md]:子任务上提供了一些少数样本,发现能极大提升性能
(GPT-2(Language Models are Unsupervised Multitask Learners))(2019.2): 1.5B, 40GB data,泛化性不错 => 不需要下游标签,直接在子任务上做预训练模型的预测
Language Models are Few-Shot Learners(GPT-3(Generative Pretrained Transformer))(2020.5): 175B, 45TB data
(GPT 3(Generative Pretrained Transformer))(2020)
GPT 4 (2023) My Notes
Evaluating Large Language Models Trained on Code(Codex: openai 的 )(2021.7.14)
Competition-Level Code Generation with AlphaCode(2022.2.19):生成更长的代码和文档
Language Models are unsupervised Multitask Learners(2018)
Language Models are Few-Shot Learners(2020.7.22) My Notes
InstructGPT(2022.1): 有论文
LaMBDA(DeepMind 2022):
ChatGPT: Optimizing Language Models for Dialogue(OpenAI 2022.11.30). 无论文。My Notes
LLaMA: Open and Efficient Foundation Language Models: 无须私有的数据集,用开源的就可以训出 13B 上比 175B 好的效果。My Notes
下面都是基于 LLaMA,在 chatgpt 标注出的语言指令追随数据上 Finetune 的:
Vicuna: An open-source chatbot impressing gpt-4 with 90% chatgpt quality
Stanford alpaca: An instruction-following llama model
通向 AGI 之路:大型语言模型(LLM)技术精要 My Notes
MetaGPT: Multi-Agent Meta Programming Framework(Assign different roles to GPTs to form a collaborative software entity for complex tasks.)
Auto-GPT: An experimental open-source attempt to make GPT-4 fully autonomous.
QLoRA: Efficient Finetuning of Quantized LLMs(2023 5.23): 是一个高效的 finetuning 方法,显著减少了显存的使用:可以在一个 48G 的 GPU 上微调一个 65B 参数的模型,同时保留了 16-bit 的微调任务性能。
LMQL: is a programming language for language model interaction: My Notes
Guidance(Microsoft): constrained prompting, 让模型更稳定地按照特定的格式进行输出
Numbers every LLM Developer should known My Notes
Llama 2: Open Foundation and Fine-Tuned Chat Models(2023.7.18) My Notes
An Initial Exploration of Theoretical Support for Language Model Data Engineering Part1 My Notes
PyTorch Accelerating Generative AI with PyTorch II: GPT, Fast (2023.11.30) My Notes
Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?(2024.5.13) My Notes
LIMA: aligment tuning 只是简单教会了 base LLM 选择了一个跟用户交互的子分布。千个高质量的例子就足够了 My Notes
The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context-Learning 提出了简单的、不需要训练的 alignment 方法:Untuned LLMs with Restyled In-Context ALignment.
Understanding data influence on context scaling: a close look at baseline solution(fuyao, 2023.12): 主要探讨的最基础的扩大上下文的方案里,数据相关的东西对语言模型上下文 scaling 的影响。 My Notes
How Long Can Open-Source LLMs Truly Promise on Context Length?: 里面有一些方法
Extending Context is Hard...,but not Impossible(一篇非常好的博客, 2023 6.29)
Extending Context Window of Large Language Models via Positional Interpolation(Meta Yuandong Tian 6.28)
DeepSpeed Ulysses: System Optimizations for Enabling Training of Extreme Long Sequence Transformer Models(2023.8) My Notes
Inverse scaling can become U-shaped: 逆扩展可以在模型参数更大,耗费算力更大后性能变好
Efficient and Effective Text Encoding for Chinese LLAMA and Alpaca My notes
Universal and Transferable Adversarial Attacks on Aligned Language Models My Notes: 需要开源模型的checkpoint
Representation Engineering: A Top-Down Approach to AI Transparency
llama.cpp: 把 Facebook 的 LLaMA 模型使用 C/C++ 进行移植:My Notes
vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention My Notes
vLLM 里 debug 的相关 Tips My Notes
How continuous batching enables 23x throughput in LLM inference while reducing p50 latency(2023 6.23) My Notes
Hugging Face Text Generation Inference My Notes
Fast Distributed Inference Serving for Large Language Models(2023.5.10): 不是 FCFS 的调度,而是可以在 token 级别上抢占的
SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills(2023.8.31) My Notes
MEDUSA: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads (2024.6.14) My Notes
SGLang: (2023.6.6) My Notes
NanoFlow: (2024.8.22) My Notes
推理在采样阶段使用的方法说明 My Notes
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration(Han Song 2023.6)
INT8 SmoothQuant(W8A8)(Accurate and Efficient Post-Training Quantization for Large Language Models)(Song Han 2022.11):需要提前对权重做预处理。TensorRT-LLM 里包含了脚本来做上述处理
INT4 and INT8 Weight-Only(W4A16 and W8A16)
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers (Han Song 2021.10)
Microsoft CheckFreq : My Notes
ByteCheckpoint: A Unified Checkpointing System for LLM Development: My Notes. 即能加速 save 和 load,又能解决不同框架之间的转换以及 tp 的变化
PERSIA: An Open, Hybrid System Scaling Deep Learning-based Recommenders up to 100 Trillion Parameters(2021) Notes, Siyu Wang's Notes
MMIC: 医疗影像的数据集 Bamboo: Notes
LayerNorm(2016.7)
CS294-AI-Sys(UC Berkely)
Week 4 Lec 10: cuBLAS Intro. My Notes
里面提到的一些经典论文,找到人讨论效果更佳
This course is a deep dive into the details of deep learning architectures with a focus on learning end-to-end models for these tasks, particularly image classification. During the 10-week course, students will learn to implement and train their own neural networks and gain a detailed understanding of cutting-edge research in computer vision. Additionally, the final assignment will give them the opportunity to train and apply multi-million parameter networks on real-world vision problems of their choice. Through multiple hands-on assignments and the final course project, students will acquire the toolset for setting up deep learning tasks and practical engineering tricks for training and fine-tuning deep neural networks.
(Vector, Matrix, and Tensor Derivatives(Erik Learned-Miller))[http://cs231n.stanford.edu/vecDerivs.pdf] My Notes
System aspect of deep learning: faster training, efficient serving, lower memory consumption
有不少结合TVM的部分,比如 Memory Optimization, Parallel Scheduing, 其中我感兴趣的部分:
LeNet(1998) Alexnet(2012) GoogleLeNet(2014): Multi-indepent pass way (Sparse weight matrix)
Inception BN (2015): Batch normalization
Residual Net(2015): Residual pass way
Convolution = Spatial Locality + Sharing
ReLU: y = max(x, 0).
Why ReLU?
- Cheap to compute
- It is roughly linear
Dropout Regularization: Randomly zero out neurons with probability 0.5
Why Dropout? Overfitting prevention.
Batch Normalization: Stabilize the Magnitude.
- Subtract mean
- Divide by standard deviation
- Output is invariant to input scale!
- Scale input by a constant
- Output of BN remains the same
Impact:
- Easy to tune learning rate . ?
- Less sensitive initialization. ?
Computational Graph Optimization and Execution
Runtime Parallel Scheduing / Networks
3.3.4. Lecture 5: GPU Programming
AI-Sys Spring 2019(UC Berkeley)
Neural Networks and Deep Learning
Deep Learning: Ian Goodfellow and Yoshua Bengio and Aron Courville
intended to help students and practitioners enter the field of machine learning in general and deep learning in particular. The online version of the book is now complete and will remain available online for free.
How the backpropagation algorithms works
Customize backward function in pytorch
PyTorch Image Models (TIMM) is a library for state-of-the-art image classification. With this library you can:
- Choose from 300+ pre-trained state-of-art image classification models.
- Train models afresh on research datasets such as ImageNet using provided scripts
- Finetune pre-trained modes on your own datasets, including the latest cutting edge models.
Pytorch Image Models
5.2. Tensor Comprehensions 2018.2.13 Facebook AI Research Technical Report
aims to provide a unified, extensble infrastructure layer with best-in-class performance across a wide variety of domain specific hardware.
目前还在比较早期阶段,还无法做到通用
OneFlow: Redesign the Distributed Deep Learning Framework from Scratch。主要是想让算子在分布式和单机下实现是一致的,解放研究员,然后能做自动并行。提出的完整管理依赖,actor 方式来流水和背压机制值得学习。 My Notes
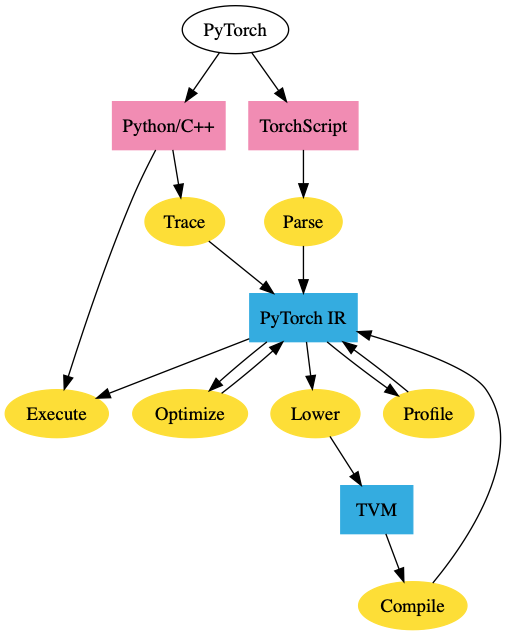
5.5. Pytorch
Pytorch CUDA Memory Caching Allocator
5.6. Tensorflow
Tensorflow: a system for large-scale machine learning(OSDI 2016)
Automatic differetiation in Pytorch(2017)
Mesh-tensorflow: Deep learning for supercomputers(NIPS 2018)
5.7. Acme: A Research Framework for Distributed Reinforcement Learning(arXiv: June 1 2020)
Agents are different scales of both complexity and computation -- including distributed versions.
让 RL 从单机版原型可以无痛扩展到多机分布式。
5.8. Launchpad
From Acme Paper:
Roughly speaking, Launchpad provides a mechanism for creating a distributed program as a graph cnosisting of nodes and edges. Nodes exactly correspond to the modules -- represented as class instances as described above -- whereas the edges represent a client/server channel allowing communication between two modules. The key innovation of Launchpad is that it handles the creating of these edges in such a way that from perspective of any module there is no ditinction between a local and remote communication, e.g. for an actor retrieving parameters from a learner in both instances this just looks like a method call.
直观感觉是这些领域里需要一些基础的框架和库,去解决分布式通信,把问题抽象,和具体场景解耦出来,这样研究人员复用这些轮子。跟当年互联网领域 rpc 通信框架、最近几年的微服务里服务中心、服务主键等功能类似。

The dataset in RL can be backed by a low-level data storaeg system.
It enables efficient insertion and routing of items and a flexible sampling mechanism that allows:FIFO, LIFO, unifrom, and weighted sampling schemes.
5.10. Weld(Standford)
Fast rust parallel code generation for data analytics frameworks. Developed at Standford University.
Weld is a language and runtime for improving the performance of data-intensive applications. It optimizes across libraries and functions by expressing the core computations in libraries using a common intermediate repersentation, and optimizing across each framwork. Modern analytics applications combine multiple functions from different libraries and frameworks to build complex workflows. Weld's take on solving this problem is to lazily build up a computation for the entire workflow, and then optimizingn and evaluating it only when a result is needed.
看起来就是解决掉用不同的库和框架来构建复杂工作流时的效率问题。通过引入一层中间表达,然后再实现到不同的框架里来做联合优化。
Paper: Weld: Rethinking the Interface Between Data-Intensive Applications.
To address this problem, we propose Weld, a new interface between data-intensive libraries that can optimize across disjoint libraries and functions. Weld can be integrated into existing frameworks such as Spark, TensorFlow, Pandas and NumPy without chaning their user-facing APIs.
Related research papers: PipeDream: General Pipeline Parallelism for DNN Training (SOSP'19)
Reverb is an efficient and easy-to-use data storage and trasport system designed for machine learning research(DeepMind, 2021-4-22)
Used an an experience replay system for distributed reinforcement learning algorithms
Pathways: Aschronous Distributed Dataflow for ML(MLSys 2022)
Analyzing and Mitigating Data Stalls in DNN Training(2021.1.19) My Notes
The NumPy array: a structure for efficient numerical computation(IEEE Computing in Science and Engineering, 2011) My Notes
Characterizing Deep Learning Training Workloads on Alibaba-PAI(2019-10-14): 主要看看他们是用什么方法来profile的,是否有借鉴意义
ImageNet-21K Pretraining for the Masses (2021.8.5) My Notes
tf.data: A Machine Learning Data Processing Framework: (2021) My Notes
Faster Neural Network Training with Data Echoing(2020) 如果数据这块 I/O 时间过长,可以对数据进行重用
Scaling Laws and Interpretability of Learning from Repeated Data (2022.5 Anthropic): 重复数据会导致 test loss 在训练中途增加。推测是发生了记忆,泛化性降低
Scaling Laws 笔记 Data Selection for Language Modes via Importance Resampling(49 引用,2023.2)
The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only(391 引用,2023.6): release 了一个 600B tokens 的数据集,在上面训了一个 1/7B 系列的模型,可以作为高质量数据集的 baseline
RedPajama Data V2 (2023.10): 100T 上去重后得到的 30T 的数据(有40多个预先计算好的数据质量的标注,可以用来做过滤和权重)。所有数据处理的脚本都开源了,数据也开源了
Flexible systems are the next frontier of machine learning Stanford 邀请 Jeff Dean 和 Chris Re 探讨最新的进展(2019) My Notes
The Deep Learning Revolution and Its Implications for Computer Architecture and Chip Design(Jeff Dean): 里面介绍了很多 ML 在各领域的应用,也介绍了为啥做专用硬件
Let's build GPT: from scratch, in code, spelled out (2023.1.18) My Notes
Let's build the GPT Tokenizer (2023.2.21) My Notes
[1hr Talk] Intro to Large Language Models(Andrej Karpthy)
State of GPT(Andrej Karpathy)
Stanford CS25: V4 I Hyung Won Chung of OpenAI My Notes
Stanford CS25: V4 I Jason Wei & Hyung Won Chung of OpenAI My Notes
In-Datacenter Performance Analysis of a Tensor Processing Unit
Tensorflow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
Tensorflow: A system for large-scale machine learning
Implementation of Control Flow In TensorFlow
Dynamic Control Flow in Large-Scale Machine Learning
NVLink vs PCiE
Mixed Precision Training (2018 ICLR) My Notes
Training Deep Neural Networks with 8-bit Floating Point Numbers(2018 NeurIPS) My Notes
NVIDIA Automatic Mixed Precision training My Notes
What Every Programmer Should Know About Floating-Point Arithmetic My Notes
int8: A100 里带的 fp8: Hopper 里带的 FP8论文:FP8 Formats for Deep Learning My Notes
Fractional GPUs: Software-based Compute and Memory Bandwidth Reservation for GPUs: 实现了比 NV 自己的 MPS 更好的划分GPU ,跑多个 程序的方式。 之前腾讯的Gaia Stack 里实现有一些限制,本质是限制了调用次数,比如 kernel 得发射很多,才比较有效,而且多个程序之间没有物理隔离。开源了实现. My Notes
Optimizing Convolutitonal Layers: NV 官网的优化卷积运算的指南。Notes
NV官网 GPU Performance Background. My Notes
DL Performance: Matrix Multiplication
PyTorch Lightning Profiler. My Notes
PyTorch 里的几种 Profiler 方式:My Notes
Hotline Profiler(2023): Automatic Annotation and A Multi-Scale Timeline for Visualizing Time-Use in DNN Training. My Notes
The FLOPs Calculus of Language Model Training. My Notes cuBLAS: My Notes
CUDA API: My Notes
CUDA Graphs: 可以用来节省传统 stream 方式下 cudaLaunchKernel 的时间,适合小的静态 kernel
Tensor Cores: 它是什么,如何用,如何确定使用到了 TensorCore,启用 TC 的前提条件
CUDA Scalable Parallel Programming(John Nickolls 2008)
Google FastSocket & Reduction Server : My Notes
python_backend My Notes
Segment Anything Model(2023.4) My Notes
DINOv2: State-of-the-art computer vision models with self-supervised learning(2023.4.17)My Notes
JAX: Compiling machine learning programs via high-level tracing(2011?), My Notes. JAX 相当于可以用非常易用的 Python 来连接了研究员和 XLA 的加速能力
It's an MLIR-based end-to-end compiler and runtime that lowers ML modeles to a unified IR that scales up to meet the needs of the datacenter and down to satisfy the constraints and special considerations of mobile and edge deployments. 目前支持 TensorFlow, JAX
下面这几篇都是做 inference 的: 推理和训练时的差异
IOS: Inter-Operator Scheduler For CNN Acceleration(MLSys 2021): 开源了。主要用 dp 来做推理时算子间的调度。因为 multi branch下conv算子更小了,而新的GPU上 SM 越来越多
Automatic Horizontal Fusion for GPU Kernels
ROLLER(OSDI 22)
TensorRT Performance Best Practices
DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale(2022.6) My Notes
TensorRT-LLM 系列:
TensorRT-LLM Architecture My Notes
训练相关的:
Nimble: Lightweight and Parallel GPU task Scheduling for Deep Learning(NeurIPS 2020), My Notes 主要是通过 CUDA graph 抹掉调度开销,然后通过多 stream 来尽量并发。但是论文和开源代码只能用于 static graph和static input,据说闭源版本支持动态
PyTorch NVFuser vs NNC vs TorchInductor
Alpa: Automating Inter and Intra-Operator Parallelism for Distributed Deep Learning(OSDI 2022), My Notes, 源码阅读
Unity: Accelerating DNN Training Through Joint Optimization of Algebraic Transformations and Parallelization(OSDI 2022). My Notes。是基于 flex flow 来做的 作者斯坦福的 jiazhihao,FlexFlow, TASO 等都是他写的。unity是在之前dp+pp的基础上,加入了代数转换和op内并行策略. flexflow 是类似pytorch一样的一个新框架,它支持tf和pytorch的前端
pytorch/tau(PiPPy): My Notes
[Triton: An Intermediate Language and Compiler for Tiled Neurual Network Computations](2019 Machine Learning And Programming Languages) My Notes Introducting Triton
TensorIR: An Abstraction for Automatic Tensorized Program Optimization My Notes
Capuchin: Tensor-based GPU Memory Management for Deep Learning(2020 ASPLOS) , My notes
Designing-a-profiling-and-visualization-tool-for-scalable-and-in-depth-analysis-of-high-performance-gpu-clusters(2019 HiPC), My notes
Bagua(Kuaishou): 类似 Hordvod 一样 Pytorch 里的插件,支持 Decentralized/Centralized, Quantized(or 1 bit), Sync/Async的优化器和通信过程, 主要在一些特定场景下做了优化:Gradient AllReduce Overlaping with communicaiton, Hierarch TCP Communication Acceleration(多主机间通信), Generic Fused Optimizer(优化很多小tensor的场景). NLP 里的 Load Balanced Data Loader。My Notes. 阅读源码收获
BytePS: A Unified Architecture for Accelerating Distributed DNN Training in Heterogeneous GPU/CPU Clusters(OSDI 2020) My Notes
Persistent threads style gpu programming for gpgpu workloads (2012 IEEE) My Notes
除了上面的 persistent threads block,还有 SM-Centric 的方式:
Enabling and Exploiting Flexible Task Assignment on GPU through SM-Centric Program Transformations(2015): 遗憾的是没开源
无论是 persisten threads block,还是 sm-centric,还是 elasticsearch,都是为了细粒度控制GPU上资源使用的
Pollux: Co-adaptive Cluster Scheduling for Goodput-Optimized-Deep-Learning My notes
AntMan
Bamboo: (2022): A system for running large pipeline-parallel DNNs affordably, reliably, and efficiently using spot instances. My Notes
Sparsely-gated Mixture of Experts Model (Shazeer 2017): 能千倍增加网络参数,但是计算量不增大:稀疏激活,这个领域里的种子文章 My notes
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity My notes
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding(ICLR 2021) My Notes
FasterMoE: Modeling and Optimizing Training of Large-Scale Dynamic Pre-Trained Models My Notes
Scalable and Efficient MoE Training for Multitask Multilingual Models(papers/moe/scalable-and-efficient-moe-training.md),有对 expert parallism 的解释
DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale(2022.7)
TUTEL: Adaptive Mixture-of-Experts at Scale(2022.6)My Notes
SE-MoE: A Scalable And Efficient Mixture-of-Experts Distributed Training and Inference System(2022.5 Paddle) My Notes
MegaBlocks: Efficient Sparse Training with Mixture of Experts(2022.11) My Notes, Code
Mixture-of-Experts Meets Instruction Tuning: A Winning Combination for Large Language Models(2023.7) My Notes
A Hybrid Tensor-Expert-Data Parallelism Approach to Optimize Mixture-of-Experts Training(2023.5.14) My Notes
ST-MoE: Designing Stable And Transferable Sparse Expert Models My Notes
MINEDOJO: Building Open-Ended Embodied Agents with Internet-Scale Knowledge(NeurIPS 2022)
DreamerV3: Mastering Diverse Domains through World Models
NeMo-Aligner (2024.5.4) Notes
ReaLHF: Optimized RLHF Training for Large Language Models through Parameter Reallocation (2024.6) Notes
OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework(2024) My Notes
An Adaptive Placement and Parallelism Framework for Accelerating RLHF Training My Notes
The Deep Learning Revolution and Its Implications for Computer Architecture and Chip Design. My Notes
希望在注解最少量样本的情况下,获得模型最大性能
A Survey of Deep Active Learning
Active Learning for Convolutional Neural Networks: A Core-Set Approach (ICLR 2018)
BMInf: An Efficient Toolkit for Big Model Inference and Tuning My Notes
ModelMesh and KServe Bring extreme scale standized model inferencing on Kubernetes
Conan: 主要是给C和 C++ 项目加速开发和持续集成来设计并优化的。有二进制包的管理能力. My Notes
Python Developing with asyncio
Conda
httpx
Asynchronous vs Synchronus programming
The Modern Histry of Object Recognition -- Infographic
HPC-oriented Latency Numbers Every Programmer Should Know
Curriculum Learning for Natural Language Understanding()
On The Power of Curriculum Learning in Training Deep Networks (2019) : 传统的要求batch 的训练数据是均匀分布,而这个是模拟了人的学习过程:从简单的任务开始,逐步增加难度。解决了两个问题:1)根据训练难度排序数据集 2)计算逐步增加了难度的 一系列 mini-batches
What every computer scientist should know about floating-point arithmetric
AMD 2nd Gen EPYC CPU Tuning Guide for InfiniBand HPC. My Notes
Mother Board Architecture. My Notes
StegaStamp: Invisible Hyperlinks in Physical Photographs(2019 Berkeley) My notes
Circuit Training: An open-source framework for generating chip floor plans with distributed deep reinforcement learning.
A Graph Placement Methoodology for Fast Chip Design. Peer Review File
Stronger Baselines for Evaluating Deep Reinforcement Learning in Chip Placement
ISPD(International Symposium on Physical Design) 2022 TOC
空前的照相现实主义和深度语言理解 Introduction, My Notes