LangChain is a framework designed to enable interaction with data using language models (LLMs). It leverages techniques such as Retrieval Augmented Generation (RAG) for efficient data integration.
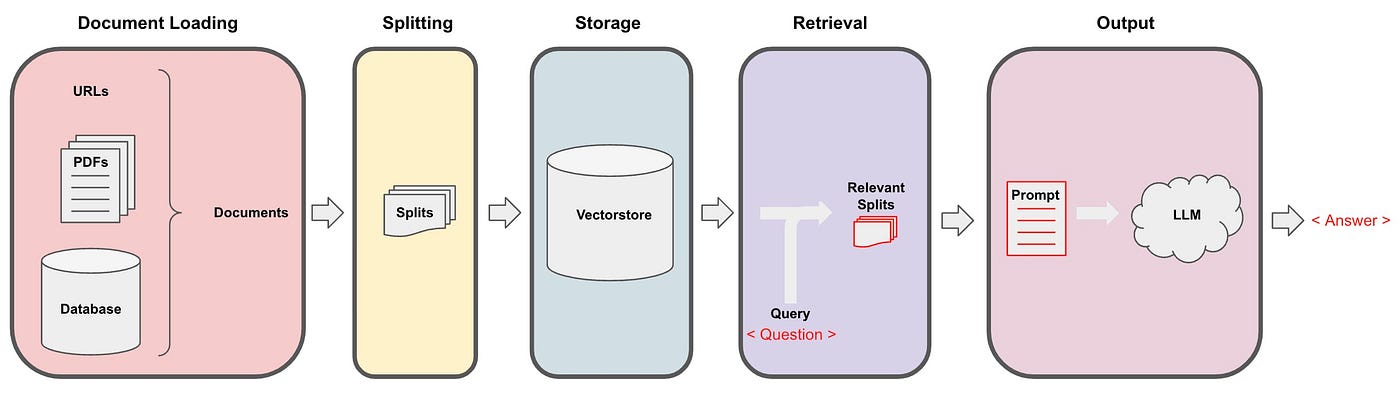
RAG is a paradigm to enhance data utilization:
- Steps:
- Retrieve relevant documents.
- Load them into the context window or "working memory."
- Supported Data Sources:
- PDFs
- URLs
- Databases
- Notion
Loaders handle data access and format conversion:
- Supported Sources:
- Websites
- Databases
- YouTube
- arXiv
- Supported Data Formats:
- HTML
- JSON
- Word
- PowerPoint
- Output: Returns a list of
Documentobjects.
Documents are split into smaller, meaningful chunks while retaining context.
from langchain.text_splitter import CharacterTextSplitter
splitter = CharacterTextSplitter(
separator="\n\n",
chunk_size=4000,
chunk_overlap=200
)- CharacterTextSplitter: Splits text by characters.
- MarkdownHeaderTextSplitter: Splits based on markdown headers.
- TokenTextSplitter: Splits text based on tokens.
- NLTKTextSplitter: Uses NLTK to split text into sentences.
- SpacyTextSplitter: Uses Spacy for sentence splitting.
- RecursiveCharacterTextSplitter: Attempts splitting by various characters.
- Language-Specific Splitters: Supports languages like Python, Markdown, etc.
- Store document splits and their embeddings.
- Enable efficient similarity search and retrieval.
- Text is converted into numerical vectors to capture semantic meaning.
- Similar texts yield similar vector representations.
- Basic Semantic Similarity: Matches queries with related content.
- Maximum Marginal Relevance (MMR): Ensures diverse responses.
- Metadata-Based Queries: Uses metadata for filtering results.
- LLM-Aided Retrieval:
- Converts user questions into precise queries using LLMs.
- Example: Self-Query for automatic query refinement.
- Shrinks retrieved responses to fit within LLM context by retaining only relevant information.
- Retrieve relevant documents from the vector store.
- Optionally compress the results to fit into the LLM context.
- Pass the compressed results and the query to an LLM for the final answer.
A chain combines retrieval and LLM-based processing:
- RetrievalQA.from_chain_type() supports different methods:
- Stuff: Includes all retrieved documents in the prompt.
- Map-Reduce: Summarizes documents into key points.
Agents use LLMs to determine:
- What actions to take.
- The sequence of those actions.
- PromptTemplate: Constructs prompts based on user input.
- Language Model: Processes the prompt and generates output.
- Output Parser: Converts model output into actionable data.
from langchain.agents import initialize_agent, AgentType
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)