{kind=link}
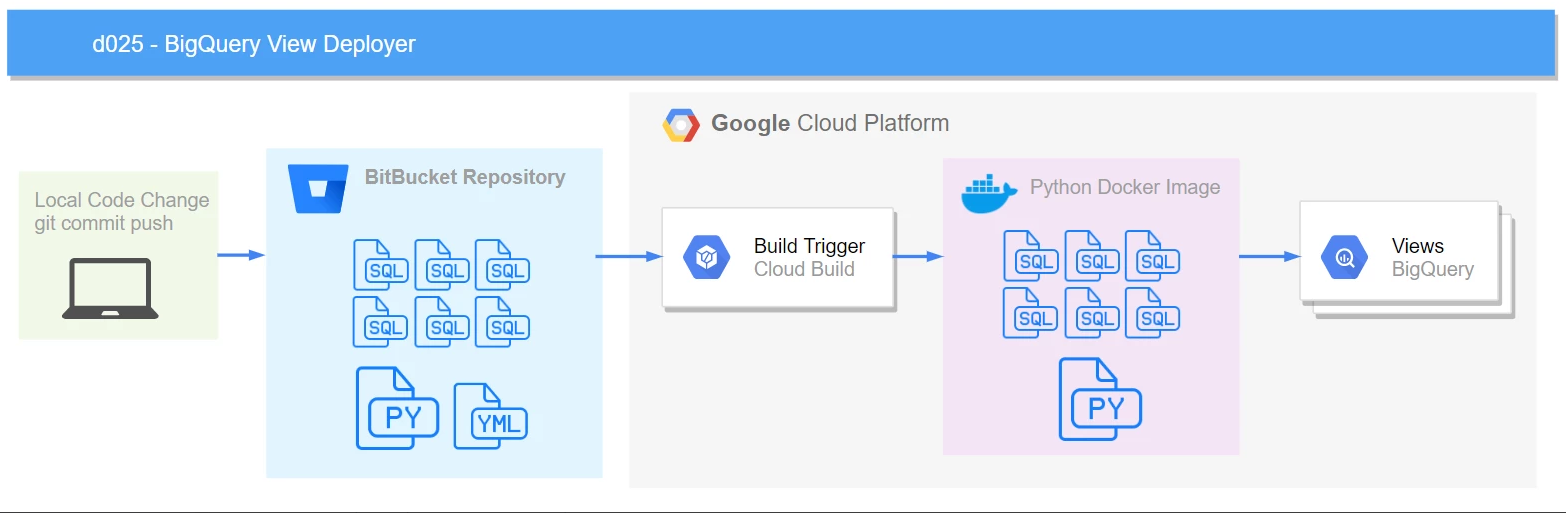
This is a process I created to deploy and maintain database sql views to Google BigQuery with the benefits of source control and the speed of continuous deployment.
Hook up a Google Cloud Build trigger to your code repository of choice. In your cloudbuild.yaml file use the python 3.7 docker image and have it execute the bq_view_deployer.py script. It will identify only the .sql files that are new/changed in the last commit and then loop through those .sql files and create/replace views in BigQuery.
Use the GCP UI to create a new Cloud Build Trigger. Choose your repo and tie to a specific branch. Have it use the Cloud Build configuration file method and point it to the bq_view_deployer.yaml file.
When a commit is merged to branch, cloud build clones your google cloud source repository, installs the pip packages in requirements.txt, and uses the python docker image and runs the .py script which creates/replaces the sql views in the repository.
Your GCP project cloud build service account needs to have the BigQuery Admin IAM role: yourGCPprojectnumber@cloudbuild.gserviceaccount.com
When you create the triggers in each environment you can tie a specific branch to each project's trigger to manage. In my application we have GCP environments for Dev, QA, Prod each with thier own build triggers so you can deploy code up through the environments.
- master branch = gcp-project-id-dev
- qa branch = gcp-project-id-qa
- prod branch = gcp-project-id-prod
The bq_view_deployer.py script examines the git tree and finds the .sql files that are new/changed in this commit and loops through each .sql file and will create/replace them in BigQuery.
It replaces dynamic variables in the .sql file text:
- _RUN_PROJECT_ID with the current project id eg: gcp-project-id-prod
- _DEPLOYMENT_DTTM is replaced with now() eg: 2019-07-01 21:25:56.516117
It gets the BigQuery dataset and view name from the .sql filename for example take filename: 'weather_data.my_weather_aggregate.sql'
- dataset_name is the string before the first '.' eg: 'weather_data'
- view_name is the middle string eg: 'my_weather_aggregate'
Due to a large number of views in many datasets, I created subfolders for each dataset. This keeps me organized and the repo cleaner.
The python script ignores the subfolder and still chooses the destination dataset from the sql filename.
See the sql files in the weather_analysis folder.