Projet Data Engineering - Blent.ai
Explorer tous les projets »
Une startup propose une plateforme SaaS (abonnement mensuel) avec des dizaines de milliers d'utilisateurs connectés en même temps. Cette plateforme est très interactive dans le sans où les utilisateurs interagissent avec de nombreuses composantes. Pour mieux comprendre le comportement de ses utilisateurs, la startup souhaite collecter toutes les activités utilisateurs (pages vues, bouton cliqué, temps resté sur une page) et conserver ces informations dans une base de données.
Il a été estimé que l'ensemble des événements utilisateurs pourrait générer un débit de données de l'ordre de 100 Mo/s. Bien qu'une partie de ces données sera traité, la startup souhaite mettre en place un système capable de gérer cette quantité de données avec un faible couplage entre les applications pour éviter les goulots d'étranglement (bottleneck).
Pour cela, la startup a décidé de mettre en place un cluster Kafka qui puisse supporter la charge de 100 Mo/s afin de permettre aux applications qui consomment ces données de ne pas être saturées.
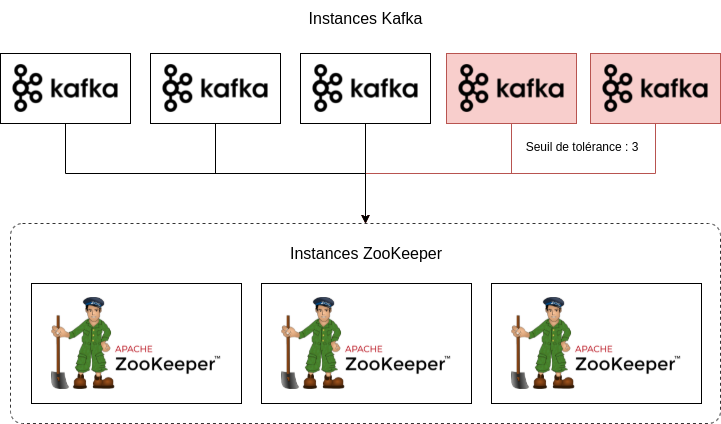
TODO : Compléter cette partie pour apporter plus d'informations sur le contexte du projet.
- Construire le diagramme d'architecture du cluster Kafka
- Exécuter une version minimale du cluster avec un seul broker Kafka et une seule instance ZooKeeper
- Configurer le cluster pour être exécuté en régime constant avec 5 brokers Kafka et 3 instances ZooKeeper
- Publier le code source et les résultats sur GitHub
La description des étapes est disponible sur la page associée au projet.
TODO : Cocher les cases au fur et à mesure de l'avancement.
Le dépôt Git contient les éléments suivantes.
k8s/contient les fichiers YAML (si Kubernetes utilisé).terraform/contient les fichiers Terraform (si utilisé).playbooks/contient les Playbooks Ansible (si utilisé).config/contient les configurations et paramètres du projet.LICENSE.txt: licence du projet.README.md: fichier d'accueil.
Les instructions suivantes permettent d'exécuter le projet sur son PC.
TODO : Ne pas hésiter à compléter/adapter cette partie en fonction des dépendances logicielles.
- Cloner le projet Git.
git clone https://github.com/blent-ai/Projet-Data-Engineering-Cluster-Kafka.git
TODO :
- Rajouter des pré-requis (cluster Kubernetes en local ou dans le Cloud, CLI Terraform, CLI Ansible, etc).
TODO : Expliquer en quelques lignes et avec des exemples de ligne de commande comment l'utilisateur peut entraîner ou utiliser lui-même le modèle.
Ce projet est proposé par Blent.ai. Les données utilisées pour ce projet peuvent être soumises à des droits d'auteur et de propriété intellectuelle. Blent.ai ne peut être responsable des utilisations faites des données utilisées dans le cadre de ce projet.
TODO : Ajouter les licences supplémentaires au projet (autres données, outils propriétaires, etc).