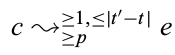The study of causality and causal inference is central to science in general and data science in particular. Being able to distinguish between correlation and causation is key to designing effective interventions in business, public policy, medicine, and many other fields. There are quite a few approaches to inferring causal relationships from data. In this post, I discuss some aspects of Judea Pearl’s graphical modelling approach, and how its limitations are addressed in recent work by Samantha Kleinberg. I then finish with a brief survey of the Bradford Hill criteria and their applicability to a key limitation of all causal inference methods: The need for untested assumptions.
The study of causality and causal inference is central to science in general and data science in particular. Being able to distinguish between correlation and causation is key to designing effective interventions in business, public policy, medicine, and many other fields. There are quite a few approaches to inferring causal relationships from data. In this post, I discuss some aspects of Judea Pearl’s graphical modelling approach, and how its limitations are addressed in recent work by Samantha Kleinberg. I then finish with a brief survey of the Bradford Hill criteria and their applicability to a key limitation of all causal inference methods: The need for untested assumptions.
Judea Pearl
Overcoming my Pearl bias
First, I must disclose that I have a personal bias in favour of Pearl’s work. While I’ve never met him, Pearl is my academic grandfather – he was the PhD advisor of my main PhD supervisor (Ingrid Zukerman). My first serious exposure to his work was through a Sydney reading group, where we discussed parts of Pearl’s approach to causal inference. Recently, I refreshed my knowledge of Pearl causality by reading Causal inference in statistics: An overview. I am by no means an expert in Pearl’s huge body of work, but I think I understand enough of it to write something of use.
Pearl’s theory of causality employs Bayesian networks to represent causal structures. These are directed acyclic graphs, where each vertex represents a variable, and an edge from X to Y implies that X causes Y. Pearl also introduces the do(X) operator, which simulates interventions by removing all the causes of X, setting it to a constant. There is much more to this theory, but two of its main contributions are the formalisation of causal concepts that are often given only a verbal treatment, and the explicit encoding of causal assumptions. These assumptions must be made by the modeller based on background knowledge, and are encoded in the graph’s structure – a missing edge between two vertices indicates that there is no direct causal relationship between the two variables.
My main issue with Pearl’s treatment of causality is that he doesn’t explicitly handle time. While time can be encoded into Pearl’s models (e.g., via dynamic Bayesian networks), there is nothing that prevents creation of models where the future causes changes in the past. A closely-related issue is that Pearl’s causal models must be directed acyclic graphs, making it hard to model feedback loops. For example, Pearl says that “mud does not cause rain”, but this isn’t true – water from mud evaporates, causing rain (which causes mud). What’s true is that “mud now doesn’t cause rain now” or something along these lines, which is something that must be accounted for by adding temporal information to the models.
Nonetheless, Pearl’s theory is an important step forward in the study of causality. In his words, “in the bulk of the statistical literature before 2000, causal claims rarely appear in the mathematics. They surface only in the verbal interpretation that investigators occasionally attach to certain associations, and in the verbal description with which investigators justify assumptions.” The importance of formal causal analysis cannot be overstated, as it underlies many decisions that affect our lives. However, it seems to me like there’s still plenty of work to be done before causal analysis becomes as established as other statistical tools.
Judea Pearl
Overcoming my Pearl bias
First, I must disclose that I have a personal bias in favour of Pearl’s work. While I’ve never met him, Pearl is my academic grandfather – he was the PhD advisor of my main PhD supervisor (Ingrid Zukerman). My first serious exposure to his work was through a Sydney reading group, where we discussed parts of Pearl’s approach to causal inference. Recently, I refreshed my knowledge of Pearl causality by reading Causal inference in statistics: An overview. I am by no means an expert in Pearl’s huge body of work, but I think I understand enough of it to write something of use.
Pearl’s theory of causality employs Bayesian networks to represent causal structures. These are directed acyclic graphs, where each vertex represents a variable, and an edge from X to Y implies that X causes Y. Pearl also introduces the do(X) operator, which simulates interventions by removing all the causes of X, setting it to a constant. There is much more to this theory, but two of its main contributions are the formalisation of causal concepts that are often given only a verbal treatment, and the explicit encoding of causal assumptions. These assumptions must be made by the modeller based on background knowledge, and are encoded in the graph’s structure – a missing edge between two vertices indicates that there is no direct causal relationship between the two variables.
My main issue with Pearl’s treatment of causality is that he doesn’t explicitly handle time. While time can be encoded into Pearl’s models (e.g., via dynamic Bayesian networks), there is nothing that prevents creation of models where the future causes changes in the past. A closely-related issue is that Pearl’s causal models must be directed acyclic graphs, making it hard to model feedback loops. For example, Pearl says that “mud does not cause rain”, but this isn’t true – water from mud evaporates, causing rain (which causes mud). What’s true is that “mud now doesn’t cause rain now” or something along these lines, which is something that must be accounted for by adding temporal information to the models.
Nonetheless, Pearl’s theory is an important step forward in the study of causality. In his words, “in the bulk of the statistical literature before 2000, causal claims rarely appear in the mathematics. They surface only in the verbal interpretation that investigators occasionally attach to certain associations, and in the verbal description with which investigators justify assumptions.” The importance of formal causal analysis cannot be overstated, as it underlies many decisions that affect our lives. However, it seems to me like there’s still plenty of work to be done before causal analysis becomes as established as other statistical tools.
Samantha Kleinberg
Kleinberg: Addressing gaps in Pearl’s work
I recently finished reading Samantha Kleinberg’s Causality, Probability, and Time. Kleinberg dedicates a good portion of the book to presenting the history of causality and discussing its many definitions. As hinted by the book’s title, Kleinberg believes that one cannot discuss causality without considering time. In her words: “One of the most critical pieces of information about causality, though – the time it takes for the cause to produce its effect – has been largely ignored by both philosophical theories and computational methods. If we do not know when the effect will occur, we have little hope of being able to act successfully using the causal relationship.” Following this assertion, Kleinberg presents a new approach to causal inference that is based on probabilistic computation tree logic (PCTL). With PCTL, one can concisely express probabilistic temporal statements. For example, if we observe a potential cause c occurring at time t, and a possible effect e occurring at time t’, we can use PCTL to state the hypothesis that in general, after c becomes true, it takes between one and |t’ – t| time units for e to become true with probability at least p, i.e., c leads to e:
It is obvious why PCTL may be a better fit than Bayesian networks for expressing causal statements. For example, with a Bayesian network, we can easily express the statement that smoking causes lung cancer with probability 0.3, but this isn’t that useful, as it doesn’t tell us how long it’ll take for cancer to develop. With PCTL, we can state that smoking causes lung cancer in 5-30 years with probability at least 0.3. This matches our knowledge that cancer doesn’t develop immediately – one cigarette won’t kill you.
One of the key concepts introduced by Kleinberg is that of causal significance. Calculating the causal significance of a cause c to an effect e relies on first identifying the set X of potential (or prima facie) causes of e. The set X contains all discrete variables x such that E[e|x]≠E[e] and x occurs earlier than e. Given the set X, the causal significance of c to e is the mean of E[e|c∧x] – E[e|¬c∧x] for all x≠c. The intuition is that if a cause c is significant, its causal significance value will be high when other potential causes are held fixed. For example, if c is heavy smoking and e is severity of lung cancer (with e=0 meaning no cancer), the expected value of e given c is likely to be higher than the expected value of e given ¬c, when conditioned on any other potential cause. Once causal significance has been measured, we can separate significant causes from insignificant causes by setting a threshold on causal significance values (this threshold can be inferred from the data). Significant causes are considered to be genuine if the data is stationary and the common causes of all pairs of variables have been included, which is a very strong condition that may be hard to fulfil in realistic scenarios. However, causal significance is an evolving concept – last year, Huang and Kleinberg introduced a new definition of causal significance that can be inferred faster and yield more accurate results. My general feeling is that this line of research will continue to yield many interesting and useful results in coming years.
Kleinberg’s work is not without its limitations. In addition to the assumptions that causal relationships are stationary and the requirement to identify all potential causes, the recently-introduced definition of causal significance also requires the relationships to be linear and additive (though this limitation may be relaxed in future work). Another issue is that most of the evaluation in the studies I’ve read was done on synthetic datasets. While there are some results on real-life health and finance data, I find it hard to judge the practicality of utilising Kleinberg’s methods without applying them to problems that I’m more familiar with. Finally, as with other work in the field of causal inference, we need to have some degree of belief in untested assumptions to reach useful conclusions. In Kleinberg’s words:
Thus, a just so cause is genuine in the case where all of the outlined assumptions hold (namely that all common causes are included, the structure is representative of the system and, when data is used, a formula satisfied by the data will be satisfied by the structure). Our belief in whether a cause is genuine, in the case where it is not certain that the assumptions hold, should be proportional to how much we believe that the assumptions are true.
It is obvious why PCTL may be a better fit than Bayesian networks for expressing causal statements. For example, with a Bayesian network, we can easily express the statement that smoking causes lung cancer with probability 0.3, but this isn’t that useful, as it doesn’t tell us how long it’ll take for cancer to develop. With PCTL, we can state that smoking causes lung cancer in 5-30 years with probability at least 0.3. This matches our knowledge that cancer doesn’t develop immediately – one cigarette won’t kill you.
One of the key concepts introduced by Kleinberg is that of causal significance. Calculating the causal significance of a cause c to an effect e relies on first identifying the set X of potential (or prima facie) causes of e. The set X contains all discrete variables x such that E[e|x]≠E[e] and x occurs earlier than e. Given the set X, the causal significance of c to e is the mean of E[e|c∧x] – E[e|¬c∧x] for all x≠c. The intuition is that if a cause c is significant, its causal significance value will be high when other potential causes are held fixed. For example, if c is heavy smoking and e is severity of lung cancer (with e=0 meaning no cancer), the expected value of e given c is likely to be higher than the expected value of e given ¬c, when conditioned on any other potential cause. Once causal significance has been measured, we can separate significant causes from insignificant causes by setting a threshold on causal significance values (this threshold can be inferred from the data). Significant causes are considered to be genuine if the data is stationary and the common causes of all pairs of variables have been included, which is a very strong condition that may be hard to fulfil in realistic scenarios. However, causal significance is an evolving concept – last year, Huang and Kleinberg introduced a new definition of causal significance that can be inferred faster and yield more accurate results. My general feeling is that this line of research will continue to yield many interesting and useful results in coming years.
Kleinberg’s work is not without its limitations. In addition to the assumptions that causal relationships are stationary and the requirement to identify all potential causes, the recently-introduced definition of causal significance also requires the relationships to be linear and additive (though this limitation may be relaxed in future work). Another issue is that most of the evaluation in the studies I’ve read was done on synthetic datasets. While there are some results on real-life health and finance data, I find it hard to judge the practicality of utilising Kleinberg’s methods without applying them to problems that I’m more familiar with. Finally, as with other work in the field of causal inference, we need to have some degree of belief in untested assumptions to reach useful conclusions. In Kleinberg’s words:
Thus, a just so cause is genuine in the case where all of the outlined assumptions hold (namely that all common causes are included, the structure is representative of the system and, when data is used, a formula satisfied by the data will be satisfied by the structure). Our belief in whether a cause is genuine, in the case where it is not certain that the assumptions hold, should be proportional to how much we believe that the assumptions are true.