



简体中文 | English
One-sentence introduction: Used to extend Scrapy functionality and free up your hands.
When developing a spider using Scrapy, it is inevitable that one has to repeatedly writesettings, items, middlewares, pipeline, and some common methods. However, these contentsin different projects are roughly the same. So why not consolidate them together? I alsowant to extend some functionality, such as automatically modifying the corresponding itemand pipeline when adding a field in the spider, without even manually modifying the tablestructure of MySQL.
The main idea of the project is to allow developers to focus only on writing spider scripts,reducing development and maintenance processes. In an ideal state, one only needs to payattention to the parsing rules of fields in the spider and the .conf configuration underVIT, and be free from meaningless repetitive operations.
Taking the scenario of storing data in MySQL as an example, the project can automaticallycreate relevant databases, data tables, field annotations, add newly added fields in thespider automatically, and fix common storage problems such as field encoding, Data too long,and non-existent storage fields.
quick start:
pip install ayugespidertoolsOptional installation 1, install all database-related dependencies:
pip install ayugespidertools[database]Optional installation 2: Install all dependencies with the following command:
pip install ayugespidertools[all]Note: For detailed installation instructions, please see Installation Guide.
Developers only need to generate a sample template according to the command, and thenconfigure the relevant settings.
Here's an example of how to use it in a GIF:
The steps in the above GIF are explained as follows:
# View library version ayuge version # Create project ayuge startproject <project_name> # Enter the project root directory cd <project_name> # Replace (or overwrite) with the actual configuration .conf file: # This is just for demonstration purposes. Normally, you can simply fill in the # required configuration in the .conf file under the VIT path. cp /root/mytemp/.conf DemoSpider/VIT/.conf # Generate spider script ayuge genspider <spider_name> <example.com> # Run script scrapy crawl <spider_name> # Note: you can also use ayuge crawl <spider_name>
Please refer to the tutorial in the DemoSpider project or the readthedocs documentation for specific scenario examples. The following scenarios are currently supported:
0).The following scenarios all support obtaining configuration from nacos or consul, no more examples. Scenario of storing data in Mysql: + 1).demo_one: Get mysql configuration from .conf. + 3).demo_three: Get mysql configuration from consul. + 21).demo_mysql_nacos: Get mysql configuration from nacos. + 5).demo_five: Twisted asynchronous storage example. + 24).demo_aiomysql: Asynchronous storage example implemented with aiomysql. + 13).demo_AyuTurboMysqlPipeline: Example of using synchronous connection pooling with MySQL. Scenario of storing data in MongoDB: + 2).demo_two: Get mongodb configuration from .conf. + 4).demo_four: Get mongodb configuration from consul. + 6).demo_six: Twisted asynchronous storage example. + 17).demo_mongo_async: Asynchronous storage example implemented with motor. Scenario of storing data in PostgreSQL(need to install ayugespidertools[database]): + 22).demo_nine: Get postgresql configuration from .conf. + 23).demo_ten: Twisted asynchronous storage example. + 27).demo_eleven: Asynchronous storage example. Scenario of storing data in ElasticSearch(need to install ayugespidertools[database]): + 28).demo_es: synchronous storage example. + 29).demo_es_async: Asynchronous storage example. Scenario of storing data in Oracle(need to install ayugespidertools[database]): + 25). demo_oracle: synchronous storage example. + 26). demo_oracle_twisted: Twisted asynchronous storage example. - 7).demo_seven: Scenarios using requests to request (this feature has been removed, and using aiohttp is recommended instead) + 8).demo_eight: Scenario of storing data in both MySQL and MongoDB at the same time. + 9).demo_aiohttp_example: Scenarios using aiohttp to request. + 10).demo_aiohttp_test: Example of using scrapy aiohttp in a specific project. + 11).demo_proxy_one: Example of using dynamic tunnel proxy with "kuaidaili.com". + 12).demo_proxy_two: Example of using dedicated proxies with "kuaidaili.com". + 14).demo_crawl: Example of supporting scrapy CrawlSpider. # Example of supporting Item "Loaders feature" in this library + 15).demo_item_loader: Example of using Item Loaders in this library. - 16).demo_item_loader_two: Deleted, you can view demo_item_loader, it is very convenient to use Item Loaders. + 18).demo_mq: Template example of storing data in RabbitMQ. + 19).demo_kafka: Template example of storing data in Kafka. + 20).demo_file: Example of using this library pipeline to download images and other files to local. + 30).demo_file_sec: Self-implemented image download example. + 31).demo_oss: Example of using this library pipeline to upload to oss. + 32).demo_oss_sec: Self-implemented oss upload example. + 33).demo_oss_super: MongoDB storage scenario oss upload field supports list type. + 34).demo_conf: Supports obtaining custom configuration from .conf.
An example of quickly realizing distributed development: demo_s. Please view the detailedintroduction in the DemoSpider project. The running example picture is:
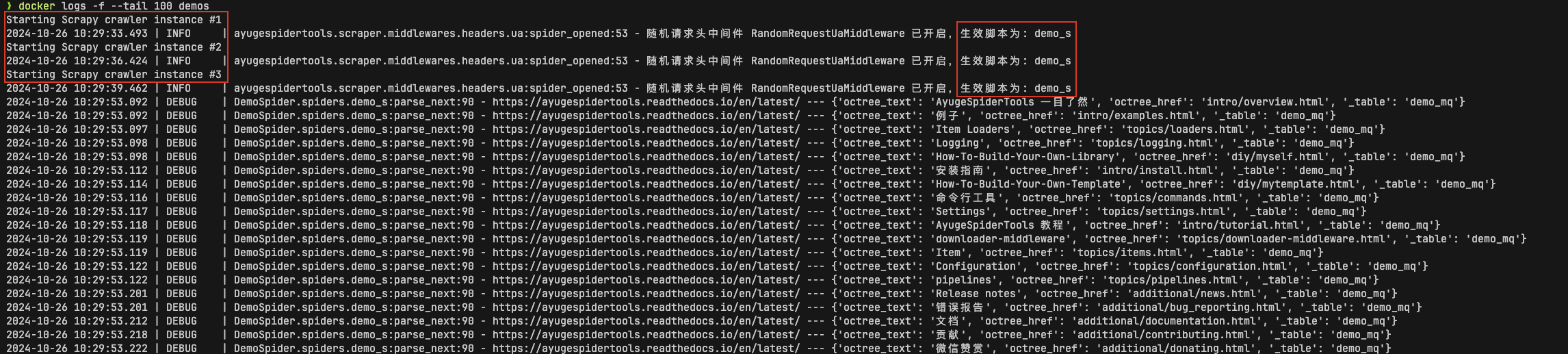
Prerequisite: You need to create a .conf file in the VIT directory of the tests, and anexample file has been provided. Please fill in the required content for testing, then:
- You can directly use tox to run the tests.
- As this library is developed with poetry, you can simply run poetry install in a new environment, and then manually run the target test or the pytest command for testing.
- Alternatively, you can use the make tool, run make start, and then make test.
If you find that the implementation of certain features in certain scenarios does notmeet your expectations and you want to modify or add custom functionality, such as removingunused modules or modifying the library name, you can modify it yourself and then build it.
This library mainly promotes the scrapy extension function. When using this library,it will not affect your scrapy project and other components.
You can use this library to develop native scrapy, or you can use scrapy style to develop,but it is still recommended to use the style development in the DemoSpider example.Will not cause excessive migration costs to developers.
You have complex storage requirements for (media) resource fields in your item! Or do you need support for other types of object cloud storage? How can I implement this easily?
- If you are familiar with this project and the Poetry packaging and building process, it is recommended to add the required functionality following the project's example style, then build and install it yourself. This approach ensures ease of use for future requirements.
- Since this is a Scrapy project, it is more advisable to use standard storage scenarios in combination with a custom Scrapy pipeline to handle resource upload fields in your item. This retains the library's generality and convenience while achieving flexibility for your specific needs.
Code test coverage is a bit low, should you consider increasing it?
Regardless, don’t worry, I will use it in conjunction with automated testing of local services.
Please refer to the official documentation of poetry for specific content.
As mentioned in the section Things You Might Care About, you can clone the source code and modify any methods (e.g. you may need a different default log configuration value oradd other project structure templates for your project scenario), and then package and useit by running poetry build or make build after modification.
For example, if you need to update kafka-python in the dependency library to a new versionx.x.x, you can simply install the existing dependencies with poetry install, and then installthe target version with poetry add kafka-python==x.x.x (try not to use poetry update kafka-python).After ensuring that the test is working properly, you can package the modified librarywith poetry build for use.
Other ways to customize scrapy projects
The project can be customized through cookiecutter, please refer to the LazyScraper project.
I hope that this project can provide guidance for you when you encounter scenarios whereyou need to extend the functionality of Scrapy.
- [✓] Scenarios for extending the functionality of Scrapy:
- [✓] Scrapy script runtime information statistics and project dependency table collectionstatistics can be used for logging and alerts.
- [✓] Custom templates that generate template files suitable for this library when usingayuge startproject <projname> and ayuge genspider <spidername>.
- [✓] Get project configuration from remote application management service.
- [✓] Get project configuration from consul.
- [✓] Get project configuration from nacos(Note: Priority is lower than consul).
- [✓] Proxy middleware (dedicated proxy, dynamic tunnel proxy).
- [✓] Random User-Agent middleware.
- [✓] Use the following tools to replace scrapy's Request for sending requests:
- [✓] requests: Using the synchronous library requests will reduce the efficiencyof scrapy.(This feature has been removed, and using aiohttp is now recommended instead.)
- [✓] aiohttp: Integrated the coroutine method of replacing scrapy Request with aiohttp.
- [✓] Adaptation for scenarios where storage is done in Mysql:
- [✓] Automatically create the required databases, tables, field formats, and fieldcomments for scenarios where Mysql users need to be created.
- [✓] Adaptation for scenarios where storage is done in MongoDB.
- [✓] Adaptation for scenarios where storage is done in PostgreSQL.
- [✓] Adaptation for scenarios where storage is done in ElasticSearch.
- [✓] Adaptation for scenarios where storage is done in Oracle.
- [✓] oss uploads scene adaptation.
- [✓] Examples of asyncio syntax support and third-party library support for async:
- [✓] Example of using asyncio and aiohttp in a spider script.
- [✓] Example of using asyncio and aioMysql in a pipeline script.
- [✓] Integration of data push functions for Kafka, RabbitMQ, etc.
- [✓] Common development scenarios:
- [✓] Concatenation of sql statements.
- [✓] Formatting data processing, such as removing web page tags, removing unnecessary spaces, etc.
- [✓] Methods for restoring font-encrypted text to its original form to bypass anti-spider measures:
- [✓] Based on mapping of font files such as ttf and woff, or combined with css, etc.
- [✓] For font files where the mapping relationship can be found directly inthe xml file, you can export the mapping using the FontForge tool.
- [✓] For font files where the mapping relationship cannot be found, OCR recognition(with less than 100% accuracy) is generally used. First, each mapping is exportedas a png using fontforge, and then various methods are used for recognition.
- [✓] Part of the font anti-crawling function has been migrated to the FontMapster project.
- [✓] Based on mapping of font files such as ttf and woff, or combined with css, etc.
- [✓] Processing of HTML data, including removal of tags, invisible characters, andconversion of special characters to normal display, etc.
- [✓] Common methods for processing image CAPTCHA:
- [✓] Methods for recognizing the distance of the missing part of a slider captcha(with multiple implementation options).
- [✓] Methods for generating a trajectory array based on the distance of a slider.
- [✓] Identification of the position and click order of click-based CAPTCHAs.
- [✓] Example methods for restoring images that have been randomly disordered and mixed up.
Notice: I will include the function demo in the readthedocs documentation to avoidoverwhelming this section with too much content.
If this project is helpful to you, you can choose to reward the author.
