最近 ai 相关的内容真是层出不穷,前 chatGPT 火了好一阵子,大语言模型的一次技术突进,带来了无数可能,仿佛一夜之间好多工作都能被 ai 替代,从项目、文案、代码、测试好多领域,不过现在哪怕到了 gpt-4 更多的也是辅助作用。chatGPT 的火热,顺便带动了 stable-diffusion、midjourney 这一类绘图创作,其实这两个去年中已经出来了。通过 prompt 的引导,可以创作出非常多的图,尤其是 stable-diffusion 还有许多开源的贡献,不同风格的模型、插件搭配,让整个生态变得非常丰富,连类似 midjourney 效果的 openjourney 都出来了。stable-diffusion 本身是开源的,只要提供模型和 GPU 基本就可以实现图像服务。而有了图像之后,自然是少不了抠图的功能,生成了目标图像之后,通过抠图将其发送到编辑平台里面,这样可以极大的便利用户对图像操作,不用重新下载然后到 ps 里面处理。
cv 的方式
抠图的核心算法是通过将目标物体从背景色中分离出来,而当物体与背景具有明显区别的时候,通过 cv 的方式可以简单的提取到物体。比如之前写的图像分类应用的一次探索 里面对图像分割的处理,分水岭算法和轮廓检测算法都能将目标对象抠出来。
不过 cv 的方式只能用于简单情况,对于复杂的图像,无法精确的识别到整体以及边缘,还是要找其他的方式
PaddleSeg
飞桨 PaddlePaddle 出的图像分割 PaddleSeg 通过多个算法和模型能分割图像,其中 PP-HumanSeg 系列模型效果就非常好,能将人物和背景在像素级别进行区分,模型体积非常小,响应很快,经过多次优化后,PP-HumanSegV2-Lite 甚至可以在 16ms 内分割图像,而且体积只有 5.4m,可以说非常好用。人像模型还可以直接在 web 上操作,通过上传图像,服务端对人物分段,完成抠图动作,可以用懒人抠图。如果要本地使用,可以采用如下指令:
python tools/predict.py \
--config configs/ppmattingv2/ppmattingv2-stdc1-human_512.yml \
--model_path pretrained_models/ppmattingv2-stdc1-human_512.pdparams \
--image_path demo/human.jpg \
--save_dir ./output/results \
--fg_estimate True还有其他的模型,比如通用的 MODNet-MobileNetV2,只是没有提供对应的 predict 方式。
使用 PaddleSeg 需要安装 PaddlePaddle,其本身是采用 cuda 优化加速的,对于 MAC M1 只能用 cpu 的方式,不过速度也很快。
除了人像模式,PaddleSeg 还有 EISeg 交互式分割标注软件,具体的界面如下,
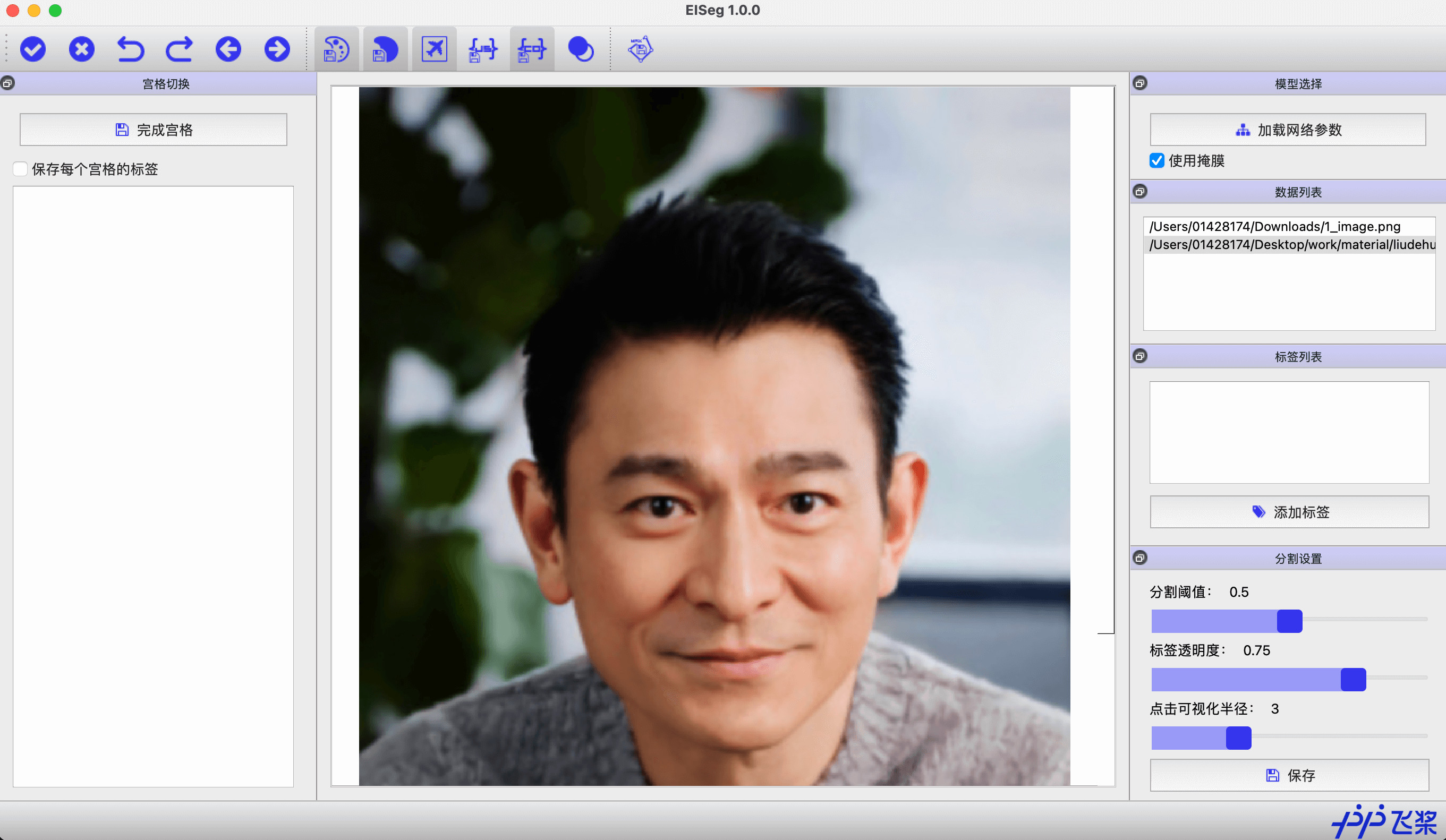
可以看到界面稍微有点简陋,可以在该平台上使用分割扣取图像,不过无法应用在 web 端。存在通用模型,不过没有对应的 pdparams 也是用不了?如果可以请指教下。
segment-anything
facebook 出的分割一切的模型 segment-anything,该模型可以在统一的框架内,指定一个点、一个边界框直接分割物体,不需要额外的训练,就可以覆盖各种场景,可以说开箱即用,对比 PaddleSeg 真的非常强。segment-anything 模型已经在 1100 万张图像和 11 亿张掩模的数据集上进行了训练,并且在各种分割任务上具有强大的零样本性能。大家可以看看下面这个示例

可以看出非常精准,每个物体都被分割出来。segment-anything 不仅可以分割一切,还能检测并分类图像。
segment-anything 有个 demo 网站,可以试试。基本看了一圈之后,毫无疑问,抠图的方案采用 segment-anything 就可以了,完成能满足要求。只是看了它的 demo 网站后,疑惑为什么速度这么快。用过 sd 大模型的人都知道,大模型输出图像效果是比较慢的,快的话也要五六秒,取决于 GPU 性能。而 demo 上,hover 就出效果,基本上只是略微的延迟,一看 network 好家伙,不是服务端返回的结果,居然是本地生成的?打开 sources 一看,居然有 sourceMap,debugger 一通后,发现原来是用了 onnx。
onnx
onnx(Open Neural Network Exchange)可以用于各种模型框架训练得到的模型能够通用,而现在它已经结合 onnxruntime 成为一种加速模型推理的方法。onnxruntime 就是指 onnx 格式模型的运行环境,它由微软开源,该环境集成多种模型加速工具,如 Nvidia 的 TensorRT 等,用于快速模型推断。具体了解大家可以看看模型压缩与推断加速技术
segment-anything 的轻量级掩码解码器可以导出为 onnx 格式,这样它就可以在任何支持 onnx 运行时的环境中运行,例如在示例中,采用的就是 onnxruntime-web,这是 ONNX Runtime 中的一项新功能,能够在浏览器中运行和部署机器学习模型,实现浏览器内推理。可以在浏览器环境下和 nodejs 环境下加载 onnx 模型的库,其中有两种运行模型:CPU 和 GPU,CPU 使用 webassambly 来加载模型,而 GPU 使用 Webgl 来加载,GPU 的覆盖性会差一些,默认运行在 CPU 上。onnxruntime-web 提供了 inferenceSession 的运行时对象,提供了方法 run 方法。方法如下
// URL 为 onnx 的模型地址
const session = await ort.InferenceSession.create(URL);
const dataA = Float32Array.from([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]);
const dataB = Float32Array.from([
10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120,
]);
const tensorA = new ort.Tensor("float32", dataA, [3, 4]);
const tensorB = new ort.Tensor("float32", dataB, [4, 3]);
const feeds = { a: tensorA, b: tensorB };
const results = await session.run(feeds);segment-anything 与 onnx
segment-anything 里面 onnx 的模型,可以通过 python scripts/export_onnx_model.py --checkpoint <path/to/checkpoint> --model-type <model_type> --output <path/to/output> 方式输出,然而大概看了下 export_onnx_model.py 其中有不少随机变量,如果要输出更好的 onnx 则需要自己调整。
再看看传入 session.run 里面的主要参数:
- low_res_embedding: segment-anything 模型输出的预测文件
- point_coords: 坐标点,鼠标移动/点击位置
- image_size: 尺寸大小
其中 low_res_embedding 是由 segment-anything 输出,先按照官方教程生成 predictor 对象,再加载对应图像,直接获取返回 get_image_embedding 的 base64 格式数据。
checkpoint = "./sam_vit_h_4b8939.pth"
model_type = "vit_h"
sam = sam_model_registry[model_type](checkpoint=checkpoint)
sam.to(device='cpu')
predictor = SamPredictor(sam)
def get_image_embedding(url):
print('image url:', url)
predictor.reset_image()
req = urllib.request.urlopen(url)
arr = np.asarray(bytearray(req.read()), dtype=np.uint8)
image = cv2.imdecode(arr, -1)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
predictor.set_image(image)
image_embedding = predictor.get_image_embedding().cpu().numpy()
return [base64.b64encode(image_embedding)]point_coords 则是坐标点位置,可以是鼠标滑动时候的坐标,也可以是点击时候的坐标,当然原点是图像的左上角。image_size 是遮罩缩放后的尺寸。
图像展示
通过 model.run 可以获得一维的图像数据,那如何显示出来?这里分两种操作, hover 和点选操作。
对于 hover 的情况,显示出高亮的区域就可以:
function toImageData(input: any, width: number, height: number) {
const [r, g, b, a] = [0, 114, 189, 255];
const arr = new Uint8ClampedArray(4 * width * height).fill(0);
for (let i = 0; i < input.length; i++) {
if (input[i] > 0.0) {
arr[4 * i + 0] = r;
arr[4 * i + 1] = g;
arr[4 * i + 2] = b;
arr[4 * i + 3] = a;
}
}
return new ImageData(arr, height, width);
}遍历所有数据,如果是大于 0 的,则认为是选中内容,配置对应的高亮蓝色,然后 canvas 来绘制图像,效果如下图

可以看到中间的白马会被高亮的效果。点选后,白马自身是正常显示的,周围有高亮效果,同时其他地方也会一个遮罩效果。

白马四周高亮则比较复杂,onnx 输出的数据是整体的图像数据,没有直接边缘处理。所以这里采用了自行的一套边缘处理算法,将 onnx 生成的 mask 转为 svg 数据:
- RLE 算法,遍历所有数据压缩图像,抠图过程会有非常多的冗余信息,对于只需要高亮单个模块而言,通过 RLE 降低整体信息。将原本 699392 个数据,减少到 1000+ 个,便于后面操作。
- 解析 RLE 输出后的断点信息
- 根据断点信息,生成多边形线段
- 将线段,通过
Move 形式形成多边形。
其中步骤三、步骤四涉及到非常多细节处理,包括化短线段为长线段、直角构成、反复选择相邻顶点、边形成等问题,感兴趣的可以自行研究下。
其中生成的剪切图像,则是采用 canvas 的方式,单独将 svg 和原图像绘制成新的图像,如存在值,则是绘图的区域。最后生成新的 canvas。
总结
刚开始写这篇博客的时候,chatGPT 非常很火,甚至公司内部都在孵化产品,带热了周围的生态,图生图,以及后面其他大中厂每周都会发布一个大模型,股票也是上天了。到现在三个多月过去了,chatGPT 热度明显下来,图生图也是如此,其实没有大家想象中那么好用,当然作为一个辅助产品还是不错的。
参考
- 模型压缩与推断加速技术
最近 ai 相关的内容真是层出不穷,前 chatGPT 火了好一阵子,大语言模型的一次技术突进,带来了无数可能,仿佛一夜之间好多工作都能被 ai 替代,从项目、文案、代码、测试好多领域,不过现在哪怕到了 gpt-4 更多的也是辅助作用。chatGPT 的火热,顺便带动了 stable-diffusion、midjourney 这一类绘图创作,其实这两个去年中已经出来了。通过 prompt 的引导,可以创作出非常多的图,尤其是 stable-diffusion 还有许多开源的贡献,不同风格的模型、插件搭配,让整个生态变得非常丰富,连类似 midjourney 效果的 openjourney 都出来了。stable-diffusion 本身是开源的,只要提供模型和 GPU 基本就可以实现图像服务。而有了图像之后,自然是少不了抠图的功能,生成了目标图像之后,通过抠图将其发送到编辑平台里面,这样可以极大的便利用户对图像操作,不用重新下载然后到 ps 里面处理。
cv 的方式
抠图的核心算法是通过将目标物体从背景色中分离出来,而当物体与背景具有明显区别的时候,通过 cv 的方式可以简单的提取到物体。比如之前写的图像分类应用的一次探索 里面对图像分割的处理,分水岭算法和轮廓检测算法都能将目标对象抠出来。
不过 cv 的方式只能用于简单情况,对于复杂的图像,无法精确的识别到整体以及边缘,还是要找其他的方式
PaddleSeg
飞桨 PaddlePaddle 出的图像分割 PaddleSeg 通过多个算法和模型能分割图像,其中 PP-HumanSeg 系列模型效果就非常好,能将人物和背景在像素级别进行区分,模型体积非常小,响应很快,经过多次优化后,PP-HumanSegV2-Lite 甚至可以在 16ms 内分割图像,而且体积只有 5.4m,可以说非常好用。人像模型还可以直接在 web 上操作,通过上传图像,服务端对人物分段,完成抠图动作,可以用懒人抠图。如果要本地使用,可以采用如下指令:
python tools/predict.py \ --config configs/ppmattingv2/ppmattingv2-stdc1-human_512.yml \ --model_path pretrained_models/ppmattingv2-stdc1-human_512.pdparams \ --image_path demo/human.jpg \ --save_dir ./output/results \ --fg_estimate True还有其他的模型,比如通用的 MODNet-MobileNetV2,只是没有提供对应的 predict 方式。
使用 PaddleSeg 需要安装 PaddlePaddle,其本身是采用 cuda 优化加速的,对于 MAC M1 只能用 cpu 的方式,不过速度也很快。
除了人像模式,PaddleSeg 还有 EISeg 交互式分割标注软件,具体的界面如下,
可以看到界面稍微有点简陋,可以在该平台上使用分割扣取图像,不过无法应用在 web 端。存在通用模型,不过没有对应的 pdparams 也是用不了?如果可以请指教下。
segment-anything
facebook 出的分割一切的模型 segment-anything,该模型可以在统一的框架内,指定一个点、一个边界框直接分割物体,不需要额外的训练,就可以覆盖各种场景,可以说开箱即用,对比 PaddleSeg 真的非常强。segment-anything 模型已经在 1100 万张图像和 11 亿张掩模的数据集上进行了训练,并且在各种分割任务上具有强大的零样本性能。大家可以看看下面这个示例
可以看出非常精准,每个物体都被分割出来。segment-anything 不仅可以分割一切,还能检测并分类图像。
segment-anything 有个 demo 网站,可以试试。基本看了一圈之后,毫无疑问,抠图的方案采用 segment-anything 就可以了,完成能满足要求。只是看了它的 demo 网站后,疑惑为什么速度这么快。用过 sd 大模型的人都知道,大模型输出图像效果是比较慢的,快的话也要五六秒,取决于 GPU 性能。而 demo 上,hover 就出效果,基本上只是略微的延迟,一看 network 好家伙,不是服务端返回的结果,居然是本地生成的?打开 sources 一看,居然有 sourceMap,debugger 一通后,发现原来是用了 onnx。
onnx
onnx(Open Neural Network Exchange)可以用于各种模型框架训练得到的模型能够通用,而现在它已经结合 onnxruntime 成为一种加速模型推理的方法。onnxruntime 就是指 onnx 格式模型的运行环境,它由微软开源,该环境集成多种模型加速工具,如 Nvidia 的 TensorRT 等,用于快速模型推断。具体了解大家可以看看模型压缩与推断加速技术
segment-anything 的轻量级掩码解码器可以导出为 onnx 格式,这样它就可以在任何支持 onnx 运行时的环境中运行,例如在示例中,采用的就是 onnxruntime-web,这是 ONNX Runtime 中的一项新功能,能够在浏览器中运行和部署机器学习模型,实现浏览器内推理。可以在浏览器环境下和 nodejs 环境下加载 onnx 模型的库,其中有两种运行模型:CPU 和 GPU,CPU 使用 webassambly 来加载模型,而 GPU 使用 Webgl 来加载,GPU 的覆盖性会差一些,默认运行在 CPU 上。onnxruntime-web 提供了 inferenceSession 的运行时对象,提供了方法 run 方法。方法如下
segment-anything 与 onnx
segment-anything 里面 onnx 的模型,可以通过
python scripts/export_onnx_model.py --checkpoint <path/to/checkpoint> --model-type <model_type> --output <path/to/output>方式输出,然而大概看了下export_onnx_model.py其中有不少随机变量,如果要输出更好的 onnx 则需要自己调整。再看看传入
session.run里面的主要参数:其中
low_res_embedding是由 segment-anything 输出,先按照官方教程生成predictor对象,再加载对应图像,直接获取返回get_image_embedding的 base64 格式数据。point_coords则是坐标点位置,可以是鼠标滑动时候的坐标,也可以是点击时候的坐标,当然原点是图像的左上角。image_size是遮罩缩放后的尺寸。图像展示
通过
model.run可以获得一维的图像数据,那如何显示出来?这里分两种操作, hover 和点选操作。对于 hover 的情况,显示出高亮的区域就可以:
遍历所有数据,如果是大于 0 的,则认为是选中内容,配置对应的高亮蓝色,然后 canvas 来绘制图像,效果如下图
可以看到中间的白马会被高亮的效果。点选后,白马自身是正常显示的,周围有高亮效果,同时其他地方也会一个遮罩效果。
白马四周高亮则比较复杂,onnx 输出的数据是整体的图像数据,没有直接边缘处理。所以这里采用了自行的一套边缘处理算法,将 onnx 生成的 mask 转为 svg 数据:
Move形式形成多边形。其中步骤三、步骤四涉及到非常多细节处理,包括化短线段为长线段、直角构成、反复选择相邻顶点、边形成等问题,感兴趣的可以自行研究下。
其中生成的剪切图像,则是采用 canvas 的方式,单独将 svg 和原图像绘制成新的图像,如存在值,则是绘图的区域。最后生成新的 canvas。
总结
刚开始写这篇博客的时候,chatGPT 非常很火,甚至公司内部都在孵化产品,带热了周围的生态,图生图,以及后面其他大中厂每周都会发布一个大模型,股票也是上天了。到现在三个多月过去了,chatGPT 热度明显下来,图生图也是如此,其实没有大家想象中那么好用,当然作为一个辅助产品还是不错的。
参考