文本特征提取向量工具箱【中文】 - embedding/*
diff --git a/2_nlp_sdks/embedding/README.md b/2_nlp_sdks/embedding/README.md
new file mode 100644
index 00000000..fc82a2cf
--- /dev/null
+++ b/2_nlp_sdks/embedding/README.md
@@ -0,0 +1,60 @@
+
+
+#### 项目清单:
+
+
+
+
+
+
+ 代码特征向量提取工具箱 - embedding/*
+ 3个SDK:
+ 1.code2vec_sdk
+ 2.codet5p_110m_sdk
+ 3.mpnet_base_v2_sdk
+ 自然语言与代码特征提取工具箱提供3个SDK,以满足不同精度与速度的需要。。
+ |
+
+
+ 
+ |
+
+
+
+
+ 文本特征提取向量工具箱【中文】 - embedding/*
+ 文本语义特征提取工具箱提供4个 SDK:
+ 1.m3e_cn_sdk
+ 2.text2vec_base_chinese_sdk
+ 3.text2vec_base_chinese_sentence_sdk
+ 4.text2vec_base_chinese_paraphrase_sdk
+ |
+
+
+
+ |
+
+
+
+
+ 文本特征提取向量工具箱【中文】 - embedding/*
+ 文本语义特征向量提取工具箱【多语言】提供 3 个 SDK:
+ 1.sentence_encoder_15_sdk(支持 15 种语言)
+ 2.sentence_encoder_100_sdk(支持100种语言)
+ 3.text2vec_base_multilingual_sdk(支持50+种语言)
+ |
+
+
+
+ |
+
+
+
+
+
diff --git a/2_nlp_sdks/embedding/README_CN.md b/2_nlp_sdks/embedding/README_CN.md
new file mode 100644
index 00000000..fc82a2cf
--- /dev/null
+++ b/2_nlp_sdks/embedding/README_CN.md
@@ -0,0 +1,60 @@
+
+
+#### 项目清单:
+
+
+
+
+
+
+ 代码特征向量提取工具箱 - embedding/*
+ 3个SDK:
+ 1.code2vec_sdk
+ 2.codet5p_110m_sdk
+ 3.mpnet_base_v2_sdk
+ 自然语言与代码特征提取工具箱提供3个SDK,以满足不同精度与速度的需要。。
+ |
+
+
+
+ |
+
+
+
+
+ 文本特征提取向量工具箱【中文】 - embedding/*
+ 文本语义特征提取工具箱提供4个 SDK:
+ 1.m3e_cn_sdk
+ 2.text2vec_base_chinese_sdk
+ 3.text2vec_base_chinese_sentence_sdk
+ 4.text2vec_base_chinese_paraphrase_sdk
+ |
+
+
+
+ |
+
+
+
+
+ 文本特征提取向量工具箱【中文】 - embedding/*
+ 文本语义特征向量提取工具箱【多语言】提供 3 个 SDK:
+ 1.sentence_encoder_15_sdk(支持 15 种语言)
+ 2.sentence_encoder_100_sdk(支持100种语言)
+ 3.text2vec_base_multilingual_sdk(支持50+种语言)
+ |
+
+
+
+ |
+
+
+
+
+
diff --git a/2_nlp_sdks/embedding/code2vec_sdk/README.md b/2_nlp_sdks/embedding/code2vec_sdk/README.md
new file mode 100644
index 00000000..faefec11
--- /dev/null
+++ b/2_nlp_sdks/embedding/code2vec_sdk/README.md
@@ -0,0 +1,97 @@
+### 官网:
+[官网链接](http://www.aias.top/)
+
+### 下载模型,放置于models目录
+- 链接:https://pan.baidu.com/s/1zOFT88EHwYQDbkCjN025HQ?pwd=tn44
+
+### 自然语言与代码特征提取 SDK
+自然语言与代码特征提取工具箱提供3个SDK,以满足不同精度与速度的需要。特征向量提取应用场景有:
+代码推荐:基于代码特征提取算法,可以分析代码库中的代码片段,并为开发人员提供代码补全、代码片段推荐等功能,提高开发效率。
+代码克隆检测:通过比较代码的特征表示,可以检测出相似的代码片段或代码文件,帮助开发人员避免代码重复和维护困难。
+漏洞检测:利用代码特征提取算法,可以分析代码中潜在的漏洞模式或异常结构,帮助自动化漏洞检测和修复。
+代码质量分析:通过代码特征提取,可以评估代码的复杂性、重复性、规范性等指标,帮助开发团队改进代码质量和可维护性。
+自然语言处理与代码混合领域:在自然语言处理和代码之间建立桥梁,例如将自然语言描述转换为代码或代码注释生成等任务。
+代码特征提取算法在软件工程领域有着广泛的应用,可以帮助开发人员更好地理解、分析和利用代码,提高软件开发的效率和质量。
+
+
+- 句向量
+ 
+
+
+### SDK功能:
+- 向量提取
+- 相似度(余弦)计算
+- 两个模型: all-MiniLM-L12-v2.pt, all-MiniLM-L6-v2.pt
+
+### 应用场景:
+- 语义搜索,通过句向量相似性,检索语料库中与query最匹配的文本
+- 聚类,代码文本转为定长向量,通过聚类模型可无监督聚集相似文本
+- 分类,表示成句向量,直接用简单分类器即训练文本分类器
+
+
+
+#### 运行例子 - Text2VecExample
+运行成功后,命令行应该看到下面的信息:
+```text
+...
+# 测试代码:
+ String input1 = "calculate cosine similarity between two vectors";
+ String input2 = " public static float dot(float[] feature1, float[] feature2) {\n" +
+ " float ret = 0.0f;\n" +
+ " int length = feature1.length;\n" +
+ " // dot(x, y)\n" +
+ " for (int i = 0; i < length; ++i) {\n" +
+ " ret += feature1[i] * feature2[i];\n" +
+ " }\n" +
+ "\n" +
+ " return ret;\n" +
+ " }";
+ String input3 = " public static float cosineSim(float[] feature1, float[] feature2) {\n" +
+ " float ret = 0.0f;\n" +
+ " float mod1 = 0.0f;\n" +
+ " float mod2 = 0.0f;\n" +
+ " int length = feature1.length;\n" +
+ " for (int i = 0; i < length; ++i) {\n" +
+ " ret += feature1[i] * feature2[i];\n" +
+ " mod1 += feature1[i] * feature1[i];\n" +
+ " mod2 += feature2[i] * feature2[i];\n" +
+ " }\n" +
+ " // dot(x, y) / (np.sqrt(dot(x, x)) * np.sqrt(dot(y, y))))\n" +
+ " return (float) (ret / Math.sqrt(mod1) / Math.sqrt(mod2));\n" +
+ " }";
+
+# 向量维度:
+[INFO ] - Vector dimensions: 384
+
+#计算相似度:
+[INFO ] - Code Similarity: 0.33148342
+[INFO ] - Code Similarity: 0.54401565
+
+```
+
+### 开源算法
+#### 1. sdk使用的开源算法
+- sentence-transformers/all-MiniLM-L12-v2
+- sentence-transformers/all-MiniLM-L6-v2
+
+
+### 其它帮助信息
+http://aias.top/guides.html
+
+
+### Git地址:
+[Github链接](https://github.com/mymagicpower/AIAS)
+[Gitee链接](https://gitee.com/mymagicpower/AIAS)
+
+
+#### 帮助文档:
+- http://aias.top/guides.html
+- 1.性能优化常见问题:
+- http://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- http://aias.top/AIAS/guides/windows.html
+
diff --git a/2_nlp_sdks/embedding/codet5p_110m_sdk/README.md b/2_nlp_sdks/embedding/codet5p_110m_sdk/README.md
new file mode 100644
index 00000000..d4048836
--- /dev/null
+++ b/2_nlp_sdks/embedding/codet5p_110m_sdk/README.md
@@ -0,0 +1,97 @@
+### 官网:
+[官网链接](http://www.aias.top/)
+
+### 下载模型,放置于models目录
+- 链接:https://pan.baidu.com/s/1T_BVZTuYTTk4SweV9dnHzA?pwd=euxp
+
+### 自然语言与代码特征提取 SDK
+自然语言与代码特征提取工具箱提供3个SDK,以满足不同精度与速度的需要。特征向量提取应用场景有:
+代码推荐:基于代码特征提取算法,可以分析代码库中的代码片段,并为开发人员提供代码补全、代码片段推荐等功能,提高开发效率。
+代码克隆检测:通过比较代码的特征表示,可以检测出相似的代码片段或代码文件,帮助开发人员避免代码重复和维护困难。
+漏洞检测:利用代码特征提取算法,可以分析代码中潜在的漏洞模式或异常结构,帮助自动化漏洞检测和修复。
+代码质量分析:通过代码特征提取,可以评估代码的复杂性、重复性、规范性等指标,帮助开发团队改进代码质量和可维护性。
+自然语言处理与代码混合领域:在自然语言处理和代码之间建立桥梁,例如将自然语言描述转换为代码或代码注释生成等任务。
+代码特征提取算法在软件工程领域有着广泛的应用,可以帮助开发人员更好地理解、分析和利用代码,提高软件开发的效率和质量。
+
+
+- 句向量
+ 
+
+
+### SDK功能:
+- 向量提取
+- 相似度(余弦)计算
+- 两个模型: codet5p-110m.pt, codet5p-220m.pt
+
+### 应用场景:
+- 语义搜索,通过句向量相似性,检索语料库中与query最匹配的文本
+- 聚类,代码文本转为定长向量,通过聚类模型可无监督聚集相似文本
+- 分类,表示成句向量,直接用简单分类器即训练文本分类器
+
+
+
+#### 运行例子 - Text2VecExample
+运行成功后,命令行应该看到下面的信息:
+```text
+...
+# 测试代码:
+ String input1 = "calculate cosine similarity between two vectors";
+ String input2 = " public static float dot(float[] feature1, float[] feature2) {\n" +
+ " float ret = 0.0f;\n" +
+ " int length = feature1.length;\n" +
+ " // dot(x, y)\n" +
+ " for (int i = 0; i < length; ++i) {\n" +
+ " ret += feature1[i] * feature2[i];\n" +
+ " }\n" +
+ "\n" +
+ " return ret;\n" +
+ " }";
+ String input3 = " public static float cosineSim(float[] feature1, float[] feature2) {\n" +
+ " float ret = 0.0f;\n" +
+ " float mod1 = 0.0f;\n" +
+ " float mod2 = 0.0f;\n" +
+ " int length = feature1.length;\n" +
+ " for (int i = 0; i < length; ++i) {\n" +
+ " ret += feature1[i] * feature2[i];\n" +
+ " mod1 += feature1[i] * feature1[i];\n" +
+ " mod2 += feature2[i] * feature2[i];\n" +
+ " }\n" +
+ " // dot(x, y) / (np.sqrt(dot(x, x)) * np.sqrt(dot(y, y))))\n" +
+ " return (float) (ret / Math.sqrt(mod1) / Math.sqrt(mod2));\n" +
+ " }";
+
+# 向量维度:
+[INFO ] - Vector dimensions: 256
+
+#计算相似度:
+[INFO ] - Code Similarity: 0.5335303
+[INFO ] - Code Similarity: 0.7281074
+
+```
+
+### 开源算法
+#### 1. sdk使用的开源算法
+- Salesforce/codet5p-110m-bimodal
+- Salesforce/codet5p-220m-bimodal
+
+
+### 其它帮助信息
+http://aias.top/guides.html
+
+
+### Git地址:
+[Github链接](https://github.com/mymagicpower/AIAS)
+[Gitee链接](https://gitee.com/mymagicpower/AIAS)
+
+
+#### 帮助文档:
+- http://aias.top/guides.html
+- 1.性能优化常见问题:
+- http://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- http://aias.top/AIAS/guides/windows.html
+
diff --git a/2_nlp_sdks/embedding/m3e_cn_sdk/README.md b/2_nlp_sdks/embedding/m3e_cn_sdk/README.md
new file mode 100644
index 00000000..3a2fec5b
--- /dev/null
+++ b/2_nlp_sdks/embedding/m3e_cn_sdk/README.md
@@ -0,0 +1,77 @@
+### 官网:
+[官网链接](http://www.aias.top/)
+
+### 下载模型,放置于models目录
+- 链接:https://pan.baidu.com/s/1CX7mHfcHXSvywK44ENjDCg?pwd=1b2q
+
+### 句向量SDK【支持中文】
+使用场景主要是中文,少量英文的情况。
+- 模型通过千万级 (2200w+) 的中文句对数据集进行训练
+- 模型支持中英双语的同质文本相似度计算,异质文本检索等功能
+- 模型是文本嵌入模型,可以将自然语言转换成稠密的向量
+- 说明:
+- s2s, 即 sentence to sentence ,代表了同质文本之间的嵌入能力,适用任务:文本相似度,重复问题检测,文本分类等
+- s2p, 即 sentence to passage ,代表了异质文本之间的嵌入能力,适用任务:文本检索,GPT 记忆模块等
+
+- 句向量
+ 
+
+
+### SDK功能:
+- 句向量提取
+- 相似度(余弦)计算
+-
+### 句向量应用:
+- 语义搜索,通过句向量相似性,检索语料库中与query最匹配的文本
+- 文本聚类,文本转为定长向量,通过聚类模型可无监督聚集相似文本
+- 文本分类,表示成句向量,直接用简单分类器即训练文本分类器
+
+
+
+#### 运行例子 - SentenceEncoderExample
+运行成功后,命令行应该看到下面的信息:
+```text
+...
+# 测试语句:
+[INFO ] - input Sentence1: 今天天气不错
+[INFO ] - input Sentence2: 今天风和日丽
+
+# 向量维度:
+[INFO ] - Vector dimensions: 768
+
+# 中文 - 生成向量:
+[INFO ] - Sentence1 embeddings: [0.38705915, 0.47916633, ..., -0.38182813, -0.3867086]
+[INFO ] - Sentence2 embeddings: [0.504677, 0.52846897, ..., -0.36328274, -0.62557095]
+
+#计算中文相似度:
+[INFO ] - Chinese Similarity: 0.9068957
+
+```
+
+### 开源算法
+#### 1. sdk使用的开源算法
+- [m3e-base](https://huggingface.co/moka-ai/m3e-base)
+
+
+
+
+### 其它帮助信息
+http://aias.top/guides.html
+
+
+### Git地址:
+[Github链接](https://github.com/mymagicpower/AIAS)
+[Gitee链接](https://gitee.com/mymagicpower/AIAS)
+
+
+#### 帮助文档:
+- http://aias.top/guides.html
+- 1.性能优化常见问题:
+- http://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- http://aias.top/AIAS/guides/windows.html
+
diff --git a/2_nlp_sdks/embedding/mpnet_base_v2_sdk/README.md b/2_nlp_sdks/embedding/mpnet_base_v2_sdk/README.md
new file mode 100644
index 00000000..97856bc4
--- /dev/null
+++ b/2_nlp_sdks/embedding/mpnet_base_v2_sdk/README.md
@@ -0,0 +1,96 @@
+### 官网:
+[官网链接](http://www.aias.top/)
+
+### 下载模型,放置于models目录
+- 链接:https://pan.baidu.com/s/1rIQjfxJGrhFbjy2UG3p7kA?pwd=2mud
+
+### 自然语言与代码特征提取 SDK
+自然语言与代码特征提取工具箱提供3个SDK,以满足不同精度与速度的需要。特征向量提取应用场景有:
+代码推荐:基于代码特征提取算法,可以分析代码库中的代码片段,并为开发人员提供代码补全、代码片段推荐等功能,提高开发效率。
+代码克隆检测:通过比较代码的特征表示,可以检测出相似的代码片段或代码文件,帮助开发人员避免代码重复和维护困难。
+漏洞检测:利用代码特征提取算法,可以分析代码中潜在的漏洞模式或异常结构,帮助自动化漏洞检测和修复。
+代码质量分析:通过代码特征提取,可以评估代码的复杂性、重复性、规范性等指标,帮助开发团队改进代码质量和可维护性。
+自然语言处理与代码混合领域:在自然语言处理和代码之间建立桥梁,例如将自然语言描述转换为代码或代码注释生成等任务。
+代码特征提取算法在软件工程领域有着广泛的应用,可以帮助开发人员更好地理解、分析和利用代码,提高软件开发的效率和质量。
+
+
+- 句向量
+ 
+
+
+### SDK功能:
+- 向量提取
+- 相似度(余弦)计算
+
+### 应用场景:
+- 语义搜索,通过句向量相似性,检索语料库中与query最匹配的文本
+- 聚类,代码文本转为定长向量,通过聚类模型可无监督聚集相似文本
+- 分类,表示成句向量,直接用简单分类器即训练文本分类器
+
+
+
+#### 运行例子 - Text2VecExample
+运行成功后,命令行应该看到下面的信息:
+```text
+...
+# 测试代码:
+ String input1 = "calculate cosine similarity between two vectors";
+ String input2 = " public static float dot(float[] feature1, float[] feature2) {\n" +
+ " float ret = 0.0f;\n" +
+ " int length = feature1.length;\n" +
+ " // dot(x, y)\n" +
+ " for (int i = 0; i < length; ++i) {\n" +
+ " ret += feature1[i] * feature2[i];\n" +
+ " }\n" +
+ "\n" +
+ " return ret;\n" +
+ " }";
+ String input3 = " public static float cosineSim(float[] feature1, float[] feature2) {\n" +
+ " float ret = 0.0f;\n" +
+ " float mod1 = 0.0f;\n" +
+ " float mod2 = 0.0f;\n" +
+ " int length = feature1.length;\n" +
+ " for (int i = 0; i < length; ++i) {\n" +
+ " ret += feature1[i] * feature2[i];\n" +
+ " mod1 += feature1[i] * feature1[i];\n" +
+ " mod2 += feature2[i] * feature2[i];\n" +
+ " }\n" +
+ " // dot(x, y) / (np.sqrt(dot(x, x)) * np.sqrt(dot(y, y))))\n" +
+ " return (float) (ret / Math.sqrt(mod1) / Math.sqrt(mod2));\n" +
+ " }";
+
+# 向量维度:
+[INFO ] - Vector dimensions: 768
+
+#计算相似度:
+[INFO ] - Code Similarity: 0.40372553
+[INFO ] - Code Similarity: 0.57055503
+
+```
+
+### 开源算法
+#### 1. sdk使用的开源算法
+- sentence-transformers/all-mpnet-base-v2
+
+
+
+### 其它帮助信息
+http://aias.top/guides.html
+
+
+### Git地址:
+[Github链接](https://github.com/mymagicpower/AIAS)
+[Gitee链接](https://gitee.com/mymagicpower/AIAS)
+
+
+#### 帮助文档:
+- http://aias.top/guides.html
+- 1.性能优化常见问题:
+- http://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- http://aias.top/AIAS/guides/windows.html
+
diff --git a/2_nlp_sdks/embedding/sentence_encoder_100_sdk/README.md b/2_nlp_sdks/embedding/sentence_encoder_100_sdk/README.md
new file mode 100644
index 00000000..d1078caa
--- /dev/null
+++ b/2_nlp_sdks/embedding/sentence_encoder_100_sdk/README.md
@@ -0,0 +1,119 @@
+### 官网:
+[官网链接](http://www.aias.top/)
+
+### 下载模型,放置于models目录
+- 链接: https://pan.baidu.com/s/1EcT7QH_yoqIQDqdO0Hiv5A?pwd=1e1k
+
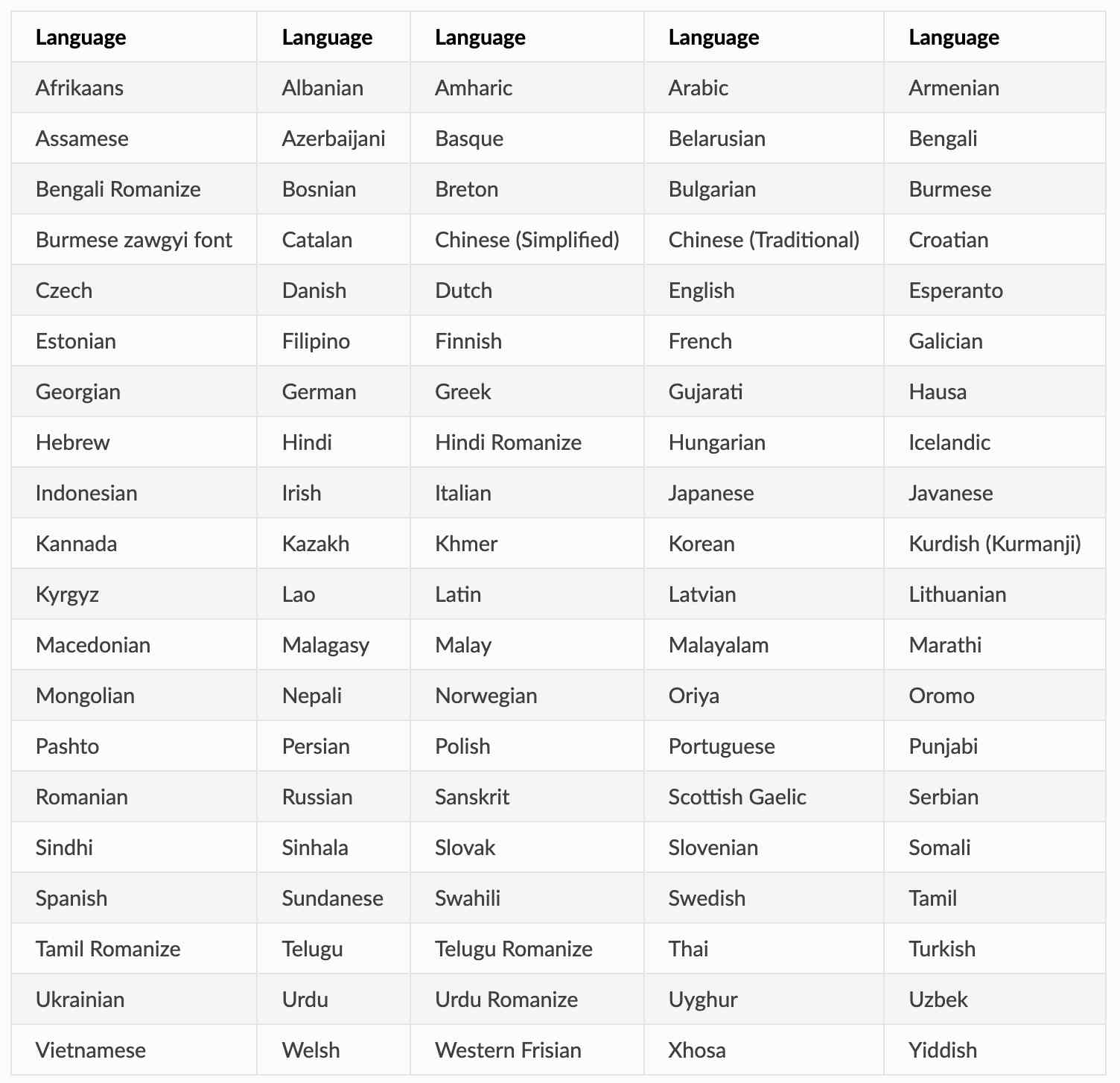
+### 句向量SDK【支持100种语言】
+句向量是指将语句映射至固定维度的实数向量。
+将不定长的句子用定长的向量表示,为NLP下游任务提供服务。
+
+- 支持下面100种语言:
+
+
+- 句向量
+
+
+-
+
+句向量应用:
+- 语义搜索,通过句向量相似性,检索语料库中与query最匹配的文本
+- 文本聚类,文本转为定长向量,通过聚类模型可无监督聚集相似文本
+- 文本分类,表示成句向量,直接用简单分类器即训练文本分类器
+
+### SDK功能:
+- 句向量提取
+- 相似度(余弦)计算
+- max_seq_length: 128(subword切词,如果是英文句子,上限平均大约60个单词)
+
+#### 运行例子 - SentenceEncoderExample
+运行成功后,命令行应该看到下面的信息:
+```text
+...
+# 测试语句:
+# 英文一组
+[INFO ] - input Sentence1: This model generates embeddings for input sentence
+[INFO ] - input Sentence2: This model generates embeddings
+
+# 中文一组
+[INFO ] - input Sentence3: 今天天气不错
+[INFO ] - input Sentence4: 今天风和日丽
+
+# 向量维度:
+[INFO ] - Vector dimensions: 768
+
+# 英文 - 生成向量:
+[INFO ] - Sentence1 embeddings: [0.10717804, 0.0023716218, ..., -0.087652676, 0.5144994]
+[INFO ] - Sentence2 embeddings: [0.06960095, 0.09246655, ..., -0.06324193, 0.2669841]
+
+#计算英文相似度:
+[INFO ] - 英文 Similarity: 0.84808713
+
+# 中文 - 生成向量:
+[INFO ] - Sentence1 embeddings: [0.19896796, 0.46568888,..., 0.09489663, 0.19511698]
+[INFO ] - Sentence2 embeddings: [0.1639189, 0.43350196, ..., -0.025053274, -0.121924624]
+
+#计算中文相似度:
+#由于使用了sentencepiece切词器,中文切词更准确,比15种语言的模型(只切成字,没有考虑词)精度更好。
+[INFO ] - 中文 Similarity: 0.67201
+
+```
+
+### 开源算法
+#### 1. sdk使用的开源算法
+- [sentence-transformers](https://github.com/UKPLab/sentence-transformers)
+- [预训练模型](https://www.sbert.net/docs/pretrained_models.html)
+- [安装](https://www.sbert.net/docs/installation.html)
+
+
+#### 2. 模型如何导出 ?
+- [how_to_convert_your_model_to_torchscript](http://docs.djl.ai/docs/pytorch/how_to_convert_your_model_to_torchscript.html)
+
+- 导出CPU模型(pytorch 模型特殊,CPU&GPU模型不通用。所以CPU,GPU需要分别导出)
+- device = torch.device("cpu")
+- device = torch.device("gpu")
+- export_model_100.py
+```text
+from sentence_transformers import SentenceTransformer
+import torch
+
+# model = SentenceTransformer('stsb-distilbert-base', device='cpu')
+model = SentenceTransformer('paraphrase-xlm-r-multilingual-v1', device='cpu')
+model.eval()
+batch_size=1
+max_seq_length=128
+device = torch.device("cpu")
+model.to(device)
+input_ids = torch.zeros(batch_size, max_seq_length, dtype=torch.long).to(device)
+input_type_ids = torch.zeros(batch_size, max_seq_length, dtype=torch.long).to(device)
+input_mask = torch.zeros(batch_size, max_seq_length, dtype=torch.long).to(device)
+# input_features = (input_ids, input_type_ids, input_mask)
+input_features = {'input_ids': input_ids, 'attention_mask': input_mask}
+
+# traced_model = torch.jit.trace(model, example_inputs=input_features)
+traced_model = torch.jit.trace(model, example_inputs=input_features,strict=False)
+traced_model.save("models/paraphrase-xlm-r-multilingual-v1/paraphrase-xlm-r-multilingual-v1.pt")
+```
+
+
+
+### 其它帮助信息
+http://aias.top/guides.html
+
+
+### Git地址:
+[Github链接](https://github.com/mymagicpower/AIAS)
+[Gitee链接](https://gitee.com/mymagicpower/AIAS)
+
+
+
+#### 帮助文档:
+- http://aias.top/guides.html
+- 1.性能优化常见问题:
+- http://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- http://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/2_nlp_sdks/embedding/sentence_encoder_15_sdk/README.md b/2_nlp_sdks/embedding/sentence_encoder_15_sdk/README.md
new file mode 100644
index 00000000..a5f30c85
--- /dev/null
+++ b/2_nlp_sdks/embedding/sentence_encoder_15_sdk/README.md
@@ -0,0 +1,116 @@
+### 官网:
+[官网链接](http://www.aias.top/)
+
+### 下载模型,放置于models目录
+- 链接: https://pan.baidu.com/s/1jFs6RzsWohumXYERvpGKrw?pwd=m7at
+
+### 句向量SDK【支持15种语言】
+句向量是指将语句映射至固定维度的实数向量。
+将不定长的句子用定长的向量表示,为NLP下游任务提供服务。
+支持 15 种语言:
+Arabic, Chinese, Dutch, English, French, German, Italian, Korean, Polish, Portuguese, Russian, Spanish, Turkish.
+
+- 句向量
+
+
+
+句向量应用:
+- 语义搜索,通过句向量相似性,检索语料库中与query最匹配的文本
+- 文本聚类,文本转为定长向量,通过聚类模型可无监督聚集相似文本
+- 文本分类,表示成句向量,直接用简单分类器即训练文本分类器
+
+### SDK功能:
+- 句向量提取
+- 相似度(余弦)计算
+
+
+#### 运行例子 - SentenceEncoderExample
+运行成功后,命令行应该看到下面的信息:
+```text
+...
+# 测试语句:
+# 英文一组
+[INFO ] - input Sentence1: This model generates embeddings for input sentence
+[INFO ] - input Sentence2: This model generates embeddings
+
+# 中文一组
+[INFO ] - input Sentence3: 今天天气不错
+[INFO ] - input Sentence4: 今天风和日丽
+
+# 向量维度:
+[INFO ] - Vector dimensions: 512
+
+# 英文 - 生成向量:
+[INFO ] - Sentence1 embeddings: [-0.07397884, 0.023079528, ..., -0.028247012, -0.08646198]
+[INFO ] - Sentence2 embeddings: [-0.084004365, -0.021871908, ..., -0.039803937, -0.090846084]
+
+#计算英文相似度:
+[INFO ] - 英文 Similarity: 0.77445346
+
+# 中文 - 生成向量:
+[INFO ] - Sentence1 embeddings: [0.012180057, -0.035749275, ..., 0.0208446, -0.048238125]
+[INFO ] - Sentence2 embeddings: [0.016560446, -0.03528302, ..., 0.023508975, -0.046362665]
+
+#计算中文相似度:
+[INFO ] - 中文 Similarity: 0.9972926
+
+```
+
+### 开源算法
+#### 1. sdk使用的开源算法
+- [sentence-transformers](https://github.com/UKPLab/sentence-transformers)
+- [预训练模型](https://www.sbert.net/docs/pretrained_models.html)
+- [安装](https://www.sbert.net/docs/installation.html)
+
+
+#### 2. 模型如何导出 ?
+- [how_to_convert_your_model_to_torchscript](http://docs.djl.ai/docs/pytorch/how_to_convert_your_model_to_torchscript.html)
+
+- 导出CPU模型(pytorch 模型特殊,CPU&GPU模型不通用。所以CPU,GPU需要分别导出)
+- device = torch.device("cpu")
+- device = torch.device("gpu")
+- export_model_15.py
+```text
+from sentence_transformers import SentenceTransformer
+import torch
+
+# model = SentenceTransformer('stsb-distilbert-base', device='cpu')
+model = SentenceTransformer('distiluse-base-multilingual-cased-v1', device='cpu')
+model.eval()
+batch_size=1
+max_seq_length=128
+device = torch.device("cpu")
+model.to(device)
+input_ids = torch.zeros(batch_size, max_seq_length, dtype=torch.long).to(device)
+input_type_ids = torch.zeros(batch_size, max_seq_length, dtype=torch.long).to(device)
+input_mask = torch.zeros(batch_size, max_seq_length, dtype=torch.long).to(device)
+# input_features = (input_ids, input_type_ids, input_mask)
+input_features = {'input_ids': input_ids, 'attention_mask': input_mask}
+
+# traced_model = torch.jit.trace(model, example_inputs=input_features)
+traced_model = torch.jit.trace(model, example_inputs=input_features,strict=False)
+traced_model.save("models/distiluse-base-multilingual-cased-v1/distiluse-base-multilingual-cased-v1.pt")
+```
+
+
+
+### 其它帮助信息
+http://aias.top/guides.html
+
+
+### Git地址:
+[Github链接](https://github.com/mymagicpower/AIAS)
+[Gitee链接](https://gitee.com/mymagicpower/AIAS)
+
+
+#### 帮助文档:
+- http://aias.top/guides.html
+- 1.性能优化常见问题:
+- http://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- http://aias.top/AIAS/guides/windows.html
+
diff --git a/2_nlp_sdks/embedding/text2vec_base_chinese_paraphrase_sdk/README.md b/2_nlp_sdks/embedding/text2vec_base_chinese_paraphrase_sdk/README.md
new file mode 100644
index 00000000..1ca5f54d
--- /dev/null
+++ b/2_nlp_sdks/embedding/text2vec_base_chinese_paraphrase_sdk/README.md
@@ -0,0 +1,73 @@
+### 官网:
+[官网链接](http://www.aias.top/)
+
+### 下载模型,放置于models目录
+- 链接:https://pan.baidu.com/s/1hW3HZ9iIuz20FXtrZBAoKg?pwd=96ij
+
+### 句向量SDK【支持中文】
+用CoSENT方法训练,基于nghuyong/ernie-3.0-base-zh用人工挑选后的中文STS数据集,加入了s2p(sentence to paraphrase)数据,
+强化了其长文本的表征能力,并在中文各NLI测试集评估达到SOTA,中文s2p(句子vs段落)语义匹配任务推荐使用。
+- 说明:
+- s2p, 即 sentence to passage ,代表了异质文本之间的嵌入能力,适用任务:文本检索,GPT 记忆模块等
+
+- 句向量
+ 
+
+
+### SDK功能:
+- 句向量提取
+- 相似度(余弦)计算
+-
+### 句向量应用:
+- 语义搜索,通过句向量相似性,检索语料库中与query最匹配的文本
+- 文本聚类,文本转为定长向量,通过聚类模型可无监督聚集相似文本
+- 文本分类,表示成句向量,直接用简单分类器即训练文本分类器
+
+
+
+#### 运行例子 - Text2VecExample
+运行成功后,命令行应该看到下面的信息:
+```text
+...
+# 测试语句:
+[INFO ] - input Sentence1: 如何更换花呗绑定银行卡
+[INFO ] - input Sentence2: 花呗更改绑定银行卡
+
+# 向量维度:
+[INFO ] - Vector dimensions: 768
+
+# 中文 - 生成向量:
+[INFO ] - Sentence1 embeddings: [0.7316301, 0.16452518, ..., -0.6056768, -0.22449276]
+[INFO ] - Sentence2 embeddings: [0.58031255, 0.04431232, ..., -0.40282968, -0.07049167]
+
+#计算中文相似度:
+[INFO ] - Chinese Similarity: 0.93226075
+
+```
+
+### 开源算法
+#### 1. sdk使用的开源算法
+- [text2vec-base-chinese-paraphrase](https://huggingface.co/shibing624/text2vec-base-chinese-paraphrase)
+
+
+
+### 其它帮助信息
+http://aias.top/guides.html
+
+
+### Git地址:
+[Github链接](https://github.com/mymagicpower/AIAS)
+[Gitee链接](https://gitee.com/mymagicpower/AIAS)
+
+
+#### 帮助文档:
+- http://aias.top/guides.html
+- 1.性能优化常见问题:
+- http://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- http://aias.top/AIAS/guides/windows.html
+
diff --git a/2_nlp_sdks/embedding/text2vec_base_chinese_sdk/README.md b/2_nlp_sdks/embedding/text2vec_base_chinese_sdk/README.md
new file mode 100644
index 00000000..cc642e5b
--- /dev/null
+++ b/2_nlp_sdks/embedding/text2vec_base_chinese_sdk/README.md
@@ -0,0 +1,73 @@
+### 官网:
+[官网链接](http://www.aias.top/)
+
+### 下载模型,放置于models目录
+- 链接:https://pan.baidu.com/s/1tUAXk-xx4s-ehcXjclplFQ?pwd=dakb
+
+### 句向量SDK【中文】
+用CoSENT方法训练,基于hfl/chinese-macbert-base在中文STS-B数据训练得到,并在中文STS-B测试集评估达到较好效果,
+中文通用语义匹配任务推荐使用。
+- 说明:
+- s2s, 即 sentence to sentence ,代表了同质文本之间的嵌入能力,适用任务:文本相似度,重复问题检测,文本分类等
+- s2p, 即 sentence to passage ,代表了异质文本之间的嵌入能力,适用任务:文本检索,GPT 记忆模块等
+
+- 句向量
+ 
+
+
+### SDK功能:
+- 句向量提取
+- 相似度(余弦)计算
+-
+### 句向量应用:
+- 语义搜索,通过句向量相似性,检索语料库中与query最匹配的文本
+- 文本聚类,文本转为定长向量,通过聚类模型可无监督聚集相似文本
+- 文本分类,表示成句向量,直接用简单分类器即训练文本分类器
+
+
+#### 运行例子 - Text2VecExample
+运行成功后,命令行应该看到下面的信息:
+```text
+...
+# 测试语句:
+[INFO ] - input Sentence1: 如何更换花呗绑定银行卡
+[INFO ] - input Sentence2: 花呗更改绑定银行卡
+
+# 向量维度:
+[INFO ] - Vector dimensions: 768
+
+# 中文 - 生成向量:
+[INFO ] - Sentence1 embeddings: [-4.439566E-4, -0.29734704, 0.8579005, ..., -0.14315642, -0.10007854]
+[INFO ] - Sentence2 embeddings: [0.6536212, -0.0766671, 0.9596233, ..., -0.0016796805, 0.2145769]
+
+#计算中文相似度:
+[INFO ] - Chinese Similarity: 0.85514605
+
+```
+
+### 开源算法
+#### 1. sdk使用的开源算法
+- [text2vec-base-chinese](https://huggingface.co/shibing624/text2vec-base-chinese)
+
+
+
+### 其它帮助信息
+http://aias.top/guides.html
+
+
+### Git地址:
+[Github链接](https://github.com/mymagicpower/AIAS)
+[Gitee链接](https://gitee.com/mymagicpower/AIAS)
+
+
+#### 帮助文档:
+- http://aias.top/guides.html
+- 1.性能优化常见问题:
+- http://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- http://aias.top/AIAS/guides/windows.html
+
diff --git a/2_nlp_sdks/embedding/text2vec_base_chinese_sentence_sdk/README.md b/2_nlp_sdks/embedding/text2vec_base_chinese_sentence_sdk/README.md
new file mode 100644
index 00000000..12269074
--- /dev/null
+++ b/2_nlp_sdks/embedding/text2vec_base_chinese_sentence_sdk/README.md
@@ -0,0 +1,73 @@
+### 官网:
+[官网链接](http://www.aias.top/)
+
+### 下载模型,放置于models目录
+- 链接:https://pan.baidu.com/s/1Cg39GHycfjoghwsihHblYA?pwd=iap1
+
+### 句向量SDK【支持中文】
+用CoSENT方法训练,基于nghuyong/ernie-3.0-base-zh,用人工挑选后的中文STS数据集:
+shibing624/nli-zh-all/text2vec-base-chinese-sentence-dataset训练得到。
+并在中文各NLI测试集评估达到较好效果,中文s2s(句子vs句子)语义匹配任务推荐使用.
+- s2s, 即 sentence to sentence ,代表了同质文本之间的嵌入能力,适用任务:文本相似度,重复问题检测,文本分类等
+
+- 句向量
+ 
+
+
+### SDK功能:
+- 句向量提取
+- 相似度(余弦)计算
+-
+### 句向量应用:
+- 语义搜索,通过句向量相似性,检索语料库中与query最匹配的文本
+- 文本聚类,文本转为定长向量,通过聚类模型可无监督聚集相似文本
+- 文本分类,表示成句向量,直接用简单分类器即训练文本分类器
+
+
+
+#### 运行例子 - Text2VecExample
+运行成功后,命令行应该看到下面的信息:
+```text
+...
+# 测试语句:
+[INFO ] - input Sentence1: 如何更换花呗绑定银行卡
+[INFO ] - input Sentence2: 花呗更改绑定银行卡
+
+# 向量维度:
+[INFO ] - Vector dimensions: 768
+
+# 中文 - 生成向量:
+[INFO ] - Sentence1 embeddings: [0.36803457, -0.32426378, ..., -0.89762807, -0.37553307]
+[INFO ] - Sentence2 embeddings: [0.33208293, -0.38463414, ..., -0.7069321, -0.09533284]
+
+#计算中文相似度:
+[INFO ] - Chinese Similarity: 0.9704481
+
+```
+
+### 开源算法
+#### 1. sdk使用的开源算法
+- [text2vec-base-chinese-sentence](https://huggingface.co/shibing624/text2vec-base-chinese-sentence)
+
+
+
+### 其它帮助信息
+http://aias.top/guides.html
+
+
+### Git地址:
+[Github链接](https://github.com/mymagicpower/AIAS)
+[Gitee链接](https://gitee.com/mymagicpower/AIAS)
+
+
+#### 帮助文档:
+- http://aias.top/guides.html
+- 1.性能优化常见问题:
+- http://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- http://aias.top/AIAS/guides/windows.html
+
diff --git a/2_nlp_sdks/embedding/text2vec_base_multilingual_sdk/README.md b/2_nlp_sdks/embedding/text2vec_base_multilingual_sdk/README.md
new file mode 100644
index 00000000..7377ba6b
--- /dev/null
+++ b/2_nlp_sdks/embedding/text2vec_base_multilingual_sdk/README.md
@@ -0,0 +1,81 @@
+### 官网:
+[官网链接](http://www.aias.top/)
+
+### 下载模型,放置于models目录
+- 链接:https://pan.baidu.com/s/1Hg4eF1IntXlkOVCy1SEsyg?pwd=3rs3
+
+### 句向量SDK【支持中文】
+是用CoSENT方法训练,基于sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2
+用人工挑选后的多语言STS数据集训练得到, 并在中英文测试集评估相对于原模型效果有提升。
+- 说明:
+- s2s, 即 sentence to sentence ,代表了同质文本之间的嵌入能力,适用任务:文本相似度,重复问题检测,文本分类等
+- s2p, 即 sentence to passage ,代表了异质文本之间的嵌入能力,适用任务:文本检索,GPT 记忆模块等
+
+
+### 支持的语言 50+ languages:
+: ar, bg, ca, cs, da, de, el, en, es, et, fa, fi, fr, fr-ca, gl, gu, he, hi,
+hr, hu, hy, id, it, ja, ka, ko, ku, lt, lv, mk, mn, mr, ms, my, nb, nl, pl, pt, pt-br,
+ro, ru, sk, sl, sq, sr, sv, th, tr, uk, ur, vi, zh-cn, zh-tw.
+
+- 句向量
+ 
+
+
+### SDK功能:
+- 句向量提取
+- 相似度(余弦)计算
+-
+### 句向量应用:
+- 语义搜索,通过句向量相似性,检索语料库中与query最匹配的文本
+- 文本聚类,文本转为定长向量,通过聚类模型可无监督聚集相似文本
+- 文本分类,表示成句向量,直接用简单分类器即训练文本分类器
+
+
+
+#### 运行例子 - SentenceEncoderExample
+运行成功后,命令行应该看到下面的信息:
+```text
+...
+# 测试语句:
+[INFO ] - input Sentence1: 如何更换花呗绑定银行卡
+[INFO ] - input Sentence2: 花呗更改绑定银行卡
+
+# 向量维度:
+[INFO ] - Vector dimensions: 384
+
+# 中文 - 生成向量:
+[INFO ] - Sentence1 embeddings: [0.07825765, 0.39537004, 0.0050692777, ..., 0.08910287, 0.1219089]
+[INFO ] - Sentence2 embeddings: [0.07381156, 0.37328288, 0.026979268, ..., 0.040807277, 0.10056336]
+
+#计算中文相似度:
+[INFO ] - Chinese Similarity: 0.9376931
+
+```
+
+### 开源算法
+#### 1. sdk使用的开源算法
+- [text2vec-base-multilingual](https://huggingface.co/shibing624/text2vec-base-multilingual)
+
+
+
+
+### 其它帮助信息
+http://aias.top/guides.html
+
+
+### Git地址:
+[Github链接](https://github.com/mymagicpower/AIAS)
+[Gitee链接](https://gitee.com/mymagicpower/AIAS)
+
+
+#### 帮助文档:
+- http://aias.top/guides.html
+- 1.性能优化常见问题:
+- http://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- http://aias.top/AIAS/guides/windows.html
+
diff --git a/2_nlp_sdks/translation/README.md b/2_nlp_sdks/translation/README.md
new file mode 100644
index 00000000..eb9f844c
--- /dev/null
+++ b/2_nlp_sdks/translation/README.md
@@ -0,0 +1,36 @@
+
+
+#### 项目清单:
+
+
+
+
+
+
+ 202种语言互相翻译 - translation/trans_nllb_sdk
+ 支持202种语言互相翻译,支持 CPU / GPU。
+ |
+
+
+ 
+ |
+
+
+
+
+ 中英互相翻译 - translation/translation_sdk
+ 可以进行英语和中文之间的翻译,支持 CPU / GPU。
+ |
+
+
+
+ |
+
+
+
+
+
diff --git a/2_nlp_sdks/translation/README_CN.md b/2_nlp_sdks/translation/README_CN.md
new file mode 100644
index 00000000..eb9f844c
--- /dev/null
+++ b/2_nlp_sdks/translation/README_CN.md
@@ -0,0 +1,36 @@
+
+
+#### 项目清单:
+
+
+
+
+
+
+ 202种语言互相翻译 - translation/trans_nllb_sdk
+ 支持202种语言互相翻译,支持 CPU / GPU。
+ |
+
+
+
+ |
+
+
+
+
+ 中英互相翻译 - translation/translation_sdk
+ 可以进行英语和中文之间的翻译,支持 CPU / GPU。
+ |
+
+
+
+ |
+
+
+
+
+
diff --git a/2_nlp_sdks/translation/trans_nllb_sdk/README.md b/2_nlp_sdks/translation/trans_nllb_sdk/README.md
new file mode 100644
index 00000000..d4533b26
--- /dev/null
+++ b/2_nlp_sdks/translation/trans_nllb_sdk/README.md
@@ -0,0 +1,251 @@
+
+
+### 下载模型,放置于models目录
+- 链接: https://pan.baidu.com/s/1KRrr0zQE601fqHZhf4oG4Q?pwd=e4lq
+
+## 202种语言互相翻译 SDK
+
+### SDK功能:
+- 支持202种语言互相翻译。
+
+
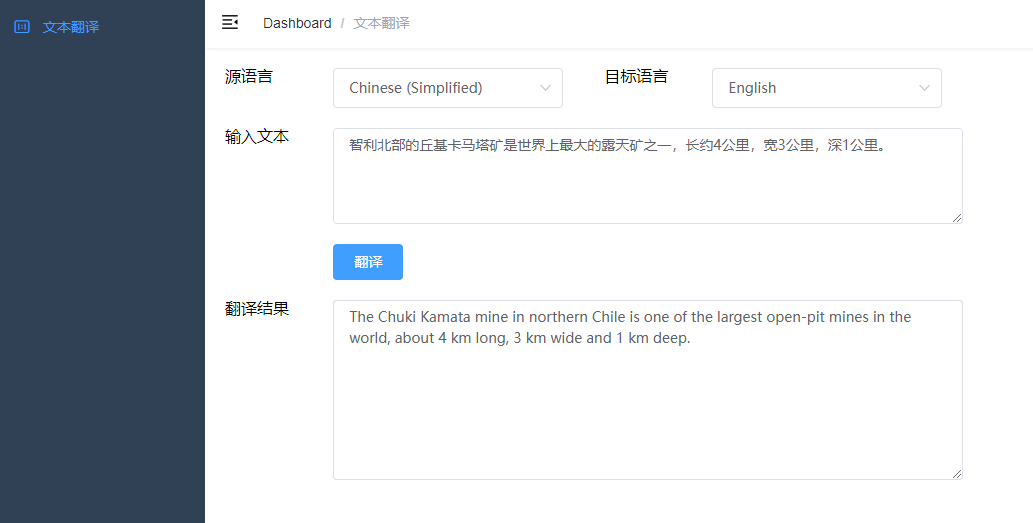
+### 运行例子 - TextGeneration
+```text
+// 输入文字
+String input = "智利北部的丘基卡马塔矿是世界上最大的露天矿之一,长约4公里,宽3公里,深1公里。";
+
+SearchConfig config = new SearchConfig();
+// 设置输出文字的最大长度
+config.setMaxSeqLength(128);
+// 设置源语言id:中文 "zho_Hans": 256200, 其它语言信息请查看:语言编码.xlsx
+config.setSrcLangId(256200);
+// 设置目标语言id:英文 "eng_Latn": 256047, 其它语言信息请查看:语言编码.xlsx
+config.setForcedBosTokenId(256047);
+
+// 运行模型,获取翻译结果
+String result = nllbModel.translate(input);
+
+// 输出翻译结果
+logger.info("{}", result);
+[INFO ] - The Chuki Kamata mine in northern Chile is one of the largest open-pit mines in the world, about 4 km long, 3 km wide and 1 km deep.
+
+```
+
+
+## 语言编码
+### 详情请参考excel文档: 语言编码.xlsx
+
+Language | Code
+---|---
+Acehnese (Arabic script) | ace_Arab
+Acehnese (Latin script) | ace_Latn
+Mesopotamian Arabic | acm_Arab
+Ta’izzi-Adeni Arabic | acq_Arab
+Tunisian Arabic | aeb_Arab
+Afrikaans | afr_Latn
+South Levantine Arabic | ajp_Arab
+Akan | aka_Latn
+Amharic | amh_Ethi
+North Levantine Arabic | apc_Arab
+Modern Standard Arabic | arb_Arab
+Modern Standard Arabic (Romanized) | arb_Latn
+Najdi Arabic | ars_Arab
+Moroccan Arabic | ary_Arab
+Egyptian Arabic | arz_Arab
+Assamese | asm_Beng
+Asturian | ast_Latn
+Awadhi | awa_Deva
+Central Aymara | ayr_Latn
+South Azerbaijani | azb_Arab
+North Azerbaijani | azj_Latn
+Bashkir | bak_Cyrl
+Bambara | bam_Latn
+Balinese | ban_Latn
+Belarusian | bel_Cyrl
+Bemba | bem_Latn
+Bengali | ben_Beng
+Bhojpuri | bho_Deva
+Banjar (Arabic script) | bjn_Arab
+Banjar (Latin script) | bjn_Latn
+Standard Tibetan | bod_Tibt
+Bosnian | bos_Latn
+Buginese | bug_Latn
+Bulgarian | bul_Cyrl
+Catalan | cat_Latn
+Cebuano | ceb_Latn
+Czech | ces_Latn
+Chokwe | cjk_Latn
+Central Kurdish | ckb_Arab
+Crimean Tatar | crh_Latn
+Welsh | cym_Latn
+Danish | dan_Latn
+German | deu_Latn
+Southwestern Dinka | dik_Latn
+Dyula | dyu_Latn
+Dzongkha | dzo_Tibt
+Greek | ell_Grek
+English | eng_Latn
+Esperanto | epo_Latn
+Estonian | est_Latn
+Basque | eus_Latn
+Ewe | ewe_Latn
+Faroese | fao_Latn
+Fijian | fij_Latn
+Finnish | fin_Latn
+Fon | fon_Latn
+French | fra_Latn
+Friulian | fur_Latn
+Nigerian Fulfulde | fuv_Latn
+Scottish Gaelic | gla_Latn
+Irish | gle_Latn
+Galician | glg_Latn
+Guarani | grn_Latn
+Gujarati | guj_Gujr
+Haitian Creole | hat_Latn
+Hausa | hau_Latn
+Hebrew | heb_Hebr
+Hindi | hin_Deva
+Chhattisgarhi | hne_Deva
+Croatian | hrv_Latn
+Hungarian | hun_Latn
+Armenian | hye_Armn
+Igbo | ibo_Latn
+Ilocano | ilo_Latn
+Indonesian | ind_Latn
+Icelandic | isl_Latn
+Italian | ita_Latn
+Javanese | jav_Latn
+Japanese | jpn_Jpan
+Kabyle | kab_Latn
+Jingpho | kac_Latn
+Kamba | kam_Latn
+Kannada | kan_Knda
+Kashmiri (Arabic script) | kas_Arab
+Kashmiri (Devanagari script) | kas_Deva
+Georgian | kat_Geor
+Central Kanuri (Arabic script) | knc_Arab
+Central Kanuri (Latin script) | knc_Latn
+Kazakh | kaz_Cyrl
+Kabiyè | kbp_Latn
+Kabuverdianu | kea_Latn
+Khmer | khm_Khmr
+Kikuyu | kik_Latn
+Kinyarwanda | kin_Latn
+Kyrgyz | kir_Cyrl
+Kimbundu | kmb_Latn
+Northern Kurdish | kmr_Latn
+Kikongo | kon_Latn
+Korean | kor_Hang
+Lao | lao_Laoo
+Ligurian | lij_Latn
+Limburgish | lim_Latn
+Lingala | lin_Latn
+Lithuanian | lit_Latn
+Lombard | lmo_Latn
+Latgalian | ltg_Latn
+Luxembourgish | ltz_Latn
+Luba-Kasai | lua_Latn
+Ganda | lug_Latn
+Luo | luo_Latn
+Mizo | lus_Latn
+Standard Latvian | lvs_Latn
+Magahi | mag_Deva
+Maithili | mai_Deva
+Malayalam | mal_Mlym
+Marathi | mar_Deva
+Minangkabau (Arabic script) | min_Arab
+Minangkabau (Latin script) | min_Latn
+Macedonian | mkd_Cyrl
+Plateau Malagasy | plt_Latn
+Maltese | mlt_Latn
+Meitei (Bengali script) | mni_Beng
+Halh Mongolian | khk_Cyrl
+Mossi | mos_Latn
+Maori | mri_Latn
+Burmese | mya_Mymr
+Dutch | nld_Latn
+Norwegian Nynorsk | nno_Latn
+Norwegian Bokmål | nob_Latn
+Nepali | npi_Deva
+Northern Sotho | nso_Latn
+Nuer | nus_Latn
+Nyanja | nya_Latn
+Occitan | oci_Latn
+West Central Oromo | gaz_Latn
+Odia | ory_Orya
+Pangasinan | pag_Latn
+Eastern Panjabi | pan_Guru
+Papiamento | pap_Latn
+Western Persian | pes_Arab
+Polish | pol_Latn
+Portuguese | por_Latn
+Dari | prs_Arab
+Southern Pashto | pbt_Arab
+Ayacucho Quechua | quy_Latn
+Romanian | ron_Latn
+Rundi | run_Latn
+Russian | rus_Cyrl
+Sango | sag_Latn
+Sanskrit | san_Deva
+Santali | sat_Olck
+Sicilian | scn_Latn
+Shan | shn_Mymr
+Sinhala | sin_Sinh
+Slovak | slk_Latn
+Slovenian | slv_Latn
+Samoan | smo_Latn
+Shona | sna_Latn
+Sindhi | snd_Arab
+Somali | som_Latn
+Southern Sotho | sot_Latn
+Spanish | spa_Latn
+Tosk Albanian | als_Latn
+Sardinian | srd_Latn
+Serbian | srp_Cyrl
+Swati | ssw_Latn
+Sundanese | sun_Latn
+Swedish | swe_Latn
+Swahili | swh_Latn
+Silesian | szl_Latn
+Tamil | tam_Taml
+Tatar | tat_Cyrl
+Telugu | tel_Telu
+Tajik | tgk_Cyrl
+Tagalog | tgl_Latn
+Thai | tha_Thai
+Tigrinya | tir_Ethi
+Tamasheq (Latin script) | taq_Latn
+Tamasheq (Tifinagh script) | taq_Tfng
+Tok Pisin | tpi_Latn
+Tswana | tsn_Latn
+Tsonga | tso_Latn
+Turkmen | tuk_Latn
+Tumbuka | tum_Latn
+Turkish | tur_Latn
+Twi | twi_Latn
+Central Atlas Tamazight | tzm_Tfng
+Uyghur | uig_Arab
+Ukrainian | ukr_Cyrl
+Umbundu | umb_Latn
+Urdu | urd_Arab
+Northern Uzbek | uzn_Latn
+Venetian | vec_Latn
+Vietnamese | vie_Latn
+Waray | war_Latn
+Wolof | wol_Latn
+Xhosa | xho_Latn
+Eastern Yiddish | ydd_Hebr
+Yoruba | yor_Latn
+Yue Chinese | yue_Hant
+Chinese (Simplified) | zho_Hans
+Chinese (Traditional) | zho_Hant
+Standard Malay | zsm_Latn
+Zulu | zul_Latn
+
+
+
+
\ No newline at end of file
diff --git a/2_nlp_sdks/translation/translation_sdk/README.md b/2_nlp_sdks/translation/translation_sdk/README.md
new file mode 100644
index 00000000..1a46c782
--- /dev/null
+++ b/2_nlp_sdks/translation/translation_sdk/README.md
@@ -0,0 +1,52 @@
+
+
+### 下载模型,放置于models目录
+- 链接: https://pan.baidu.com/s/1sCH0dPjQoBchN8T2BbTRHw?pwd=388n
+
+## 中英互相翻译 - SDK
+
+### SDK功能:
+- 可以进行英语和中文之间的翻译
+- 支持 CPU / GPU
+
+
+### 运行例子 - TextGeneration
+```text
+// 输入文字
+String input = "智利北部的丘基卡马塔矿是世界上最大的露天矿之一,长约4公里,宽3公里,深1公里。";
+
+SearchConfig config = new SearchConfig();
+config.setMaxSeqLength(128);
+
+String modelPath = "models/opus-mt-zh-en/";
+
+try (TranslationModel translationModel = new TranslationModel(config, modelPath, 4, Device.cpu());
+) {
+ System.setProperty("ai.djl.pytorch.graph_optimizer", "false");
+
+ long start = System.currentTimeMillis();
+ String result = translationModel.translate(input);
+ long end = System.currentTimeMillis();
+ logger.info("Time: {}", (end - start));
+ logger.info("{}", result);
+
+} finally {
+ System.clearProperty("ai.djl.pytorch.graph_optimizer");
+}
+
+// 输出翻译结果
+logger.info("{}", result);
+[INFO ] - The Chuki Kamata mine in northern Chile is one of the largest open-pit mines in the world, about 4 km long, 3 km wide and 1 km deep.
+
+```
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/3_audio_sdks/README.md b/3_audio_sdks/README.md
new file mode 100644
index 00000000..f013d710
--- /dev/null
+++ b/3_audio_sdks/README.md
@@ -0,0 +1,71 @@
+
+#### 项目清单:
+- 3_audio_sdks - [语音处理 SDK]
+```text
+ 1). 工具箱系列:音素工具箱,librosa,java sound,javacv ffmpeg, fft, vad工具箱等。
+ 2). 声音克隆
+ 3). 语音合成
+ 4). 声纹识别
+ 5). 语音识别
+ ...
+```
+
+
+
+
+
+
+ 语音识别(ASR)【短语音】 - asr_whisper_sdk
+ 中文语音识别。
+ |
+
+
+ 
+ |
+
+
+
+
+ 语音识别(ASR)【长语音】 - asr_whisper_long_sdk
+ 中文语音识别。
+ |
+
+
+
+ |
+
+
+
+
+ 语音处理包Librosa- librosa_sdk
+ python语音处理库librosa的java实现。
+ |
+
+
+ 
+ |
+
+
+
+
+ TTS 文本转为语音 - tts_sdk
+ TTS 文本转为语音。
+ |
+
+
+ 
+ |
+
+
+
+
+
+
diff --git a/3_audio_sdks/tts_sdk/README.md b/3_audio_sdks/tts_sdk/README.md
new file mode 100644
index 00000000..f7411ce0
--- /dev/null
+++ b/3_audio_sdks/tts_sdk/README.md
@@ -0,0 +1,75 @@
+
+### Download the model and place it in the models directory
+- Link 1: https://github.com/mymagicpower/AIAS/releases/download/apps/denoiser.zip
+- Link 2: https://github.com/mymagicpower/AIAS/releases/download/apps/speakerEncoder.zip
+- Link 3: https://github.com/mymagicpower/AIAS/releases/download/apps/tacotron2.zip
+- Link 4: https://github.com/mymagicpower/AIAS/releases/download/apps/waveGlow.zip
+-
+### TTS text to speech
+
+Note: To prevent the cloning of someone else's voice for illegal purposes, the code limits the use of voice files to only those provided in the program.
+Voice cloning refers to synthesizing audio that has the characteristics of the target speaker by using a specific voice, combining the pronunciation of the text with the speaker's voice.
+When training a speech cloning model, the target voice is used as the input of the Speaker Encoder, and the model extracts the speaker's features (voice) as the Speaker Embedding.
+Then, when training the model to resynthesize speech of this type, in addition to the input target text, the speaker's features will also be added as additional conditions to the model's training.
+During prediction, a new target voice is selected as the input of the Speaker Encoder, and its speaker's features are extracted, finally realizing the input of text and target voice and generating a speech segment of the target voice speaking the text.
+The Google team proposed a neural system for text-to-speech synthesis that can learn the speech features of multiple different speakers with only a small amount of samples, and synthesize their speech audio. In addition, for speakers that the network has not encountered during training, their speech can be synthesized with only a few seconds of unknown speaker audio without retraining, that is, the network has zero-shot learning ability.
+Traditional natural speech synthesis systems require a large amount of high-quality samples during training, usually requiring hundreds or thousands of minutes of training data for each speaker, which makes the model generally not universal and cannot be widely used in complex environments (with many different speakers). These networks combine the processes of speech modeling and speech synthesis.
+The SV2TTS work first separates these two processes and uses the first speech feature encoding network (encoder) to model the speaker's speech features, and then uses the second high-quality TTS network to convert features into speech.
+
+- SV2TTS paper
+[Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis](https://arxiv.org/pdf/1806.04558.pdf)
+
+- Network structure
+
+
+#### Mainly composed of three parts:
+#### Sound feature encoder (speaker encoder)
+Extract the speaker's voice feature information. Embed the speaker's voice into a fixed dimensional vector, which represents the speaker's potential voice features.
+The encoder mainly embeds the reference speech signal into a vector space of fixed dimension, and uses it as supervision to enable the mapping network to generate original voice signals (Mel spectrograms) with the same features.
+The key role of the encoder is similarity measurement. For different speeches of the same speaker, the vector distance (cosine angle) in the embedding vector space should be as small as possible, while for different speakers, it should be as large as possible.
+In addition, the encoder should also have the ability to resist noise and robustness, and extract the potential voice feature information of the speaker's voice without being affected by the specific speech content and background noise.
+These requirements are consistent with the requirements of the speech recognition model (speaker-discriminative), so transfer learning can be performed.
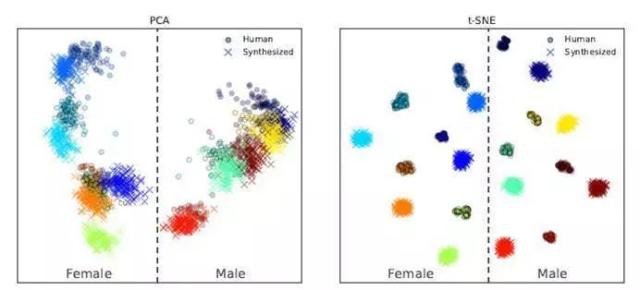
+The encoder is mainly composed of three layers of LSTM, and the input is a 40-channel logarithmic Mel spectrogram. After the output of the last frame cell of the last layer is processed by L2 regularization, the embedding vector representation of the entire sequence is obtained.
+In actual inference, any length of input speech signal will be divided into multiple segments by an 800ms window, and each segment will get an output. Finally, all outputs are averaged and superimposed to obtain the final embedding vector.
+This method is very similar to the Short-Time Fourier Transform (STFT).
+The generated embedding space vector is visualized as follows:
+
+
+It can be seen that different speakers correspond to different clustering ranges in the embedding space, which can be easily distinguished, and speakers of different genders are located on both sides.
+(However, synthesized speech and real speech are also easy to distinguish, and synthesized speech is farther away from the clustering center. This indicates that the realism of synthesized speech is not enough.)
+
+####Sequence-to-sequence mapping synthesis network (Tacotron 2)
+Based on the Tacotron 2 mapping network, the vector obtained from the text and sound feature encoder is used to generate a logarithmic Mel spectrogram.
+The Mel spectrogram takes the logarithm of the spectral frequency scale Hz and converts it to the Mel scale, so that the sensitivity of the human ear to sound is linearly positively correlated with the Mel scale.
+This network is trained independently of the encoder network. The audio signal and the corresponding text are used as inputs. The audio signal is first feature-extracted by a pre-trained encoder, and then used as input to the attention layer.
+The network output feature consists of a sequence of length 50ms and a step size of 12.5ms. After Mel scaling filtering and logarithmic dynamic range compression, the Mel spectrogram is obtained.
+In order to reduce the influence of noisy data, L1 regularization is additionally added to the loss function of this part.
+
+The comparison of the input Mel spectrogram and the synthesized spectrogram is shown below:
+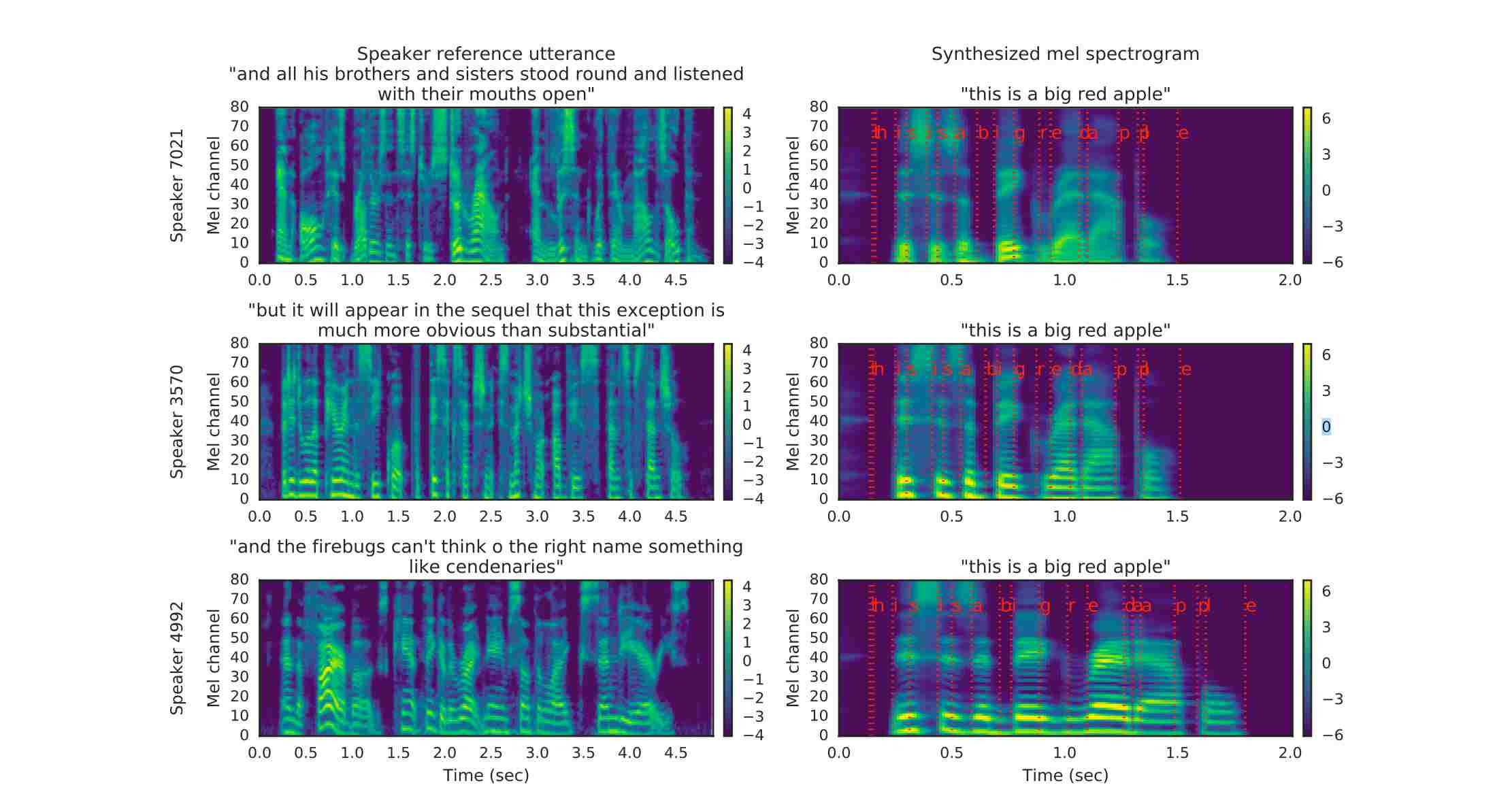
+The red line on the right graph represents the correspondence between text and spectrogram. It can be seen that the speech signal used for reference supervision does not need to be consistent with the target speech signal in the text, which is also a major feature of the SV2TTS paper.
+
+
+#### Speech synthesis network (WaveGlow)
+WaveGlow: A network that synthesizes high-quality speech by relying on streams from Mel spectrograms. It combines Glow and WaveNet to generate fast, good, and high-quality rhythms without requiring automatic regression.
+The Mel spectrogram (frequency domain) is converted into a time series sound waveform (time domain) to complete speech synthesis.
+It should be noted that these three parts of the network are trained independently, and the voice encoder network mainly plays a conditional supervision role for the sequence mapping network, ensuring that the generated speech has the unique voice features of the speaker.
+
+## Running Example- TTSExample
+
+After successful operation, the command line should see the following information:
+```text
+...
+[INFO] - Text: Convert text to speech based on the given voice
+[INFO] - Given voice: src/test/resources/biaobei-009502.mp3
+
+#Generate feature vector:
+[INFO] - Speaker Embedding Shape: [256]
+[INFO] - Speaker Embedding: [0.06272025, 0.0, 0.24136968, ..., 0.027405139, 0.0, 0.07339379, 0.0]
+[INFO] - Mel spectrogram data Shape: [80, 331]
+[INFO] - Mel spectrogram data: [-6.739388, -6.266942, -5.752069, ..., -10.643405, -10.558134, -10.5380535]
+[INFO] - Generate wav audio file: build/output/audio.wav
+```
+The speech effect generated by the text "Convert text to speech based on the given voice":
+[audio.wav](https://aias-home.oss-cn-beijing.aliyuncs.com/AIAS/voice_sdks/audio.wav)
+
diff --git a/5_bigdata_sdks/README.md b/5_bigdata_sdks/README.md
new file mode 100644
index 00000000..1713305a
--- /dev/null
+++ b/5_bigdata_sdks/README.md
@@ -0,0 +1,43 @@
+
+#### 项目清单:
+- 5_bigdata_sdks - [大数据SDK]
+
+```text
+ 1). flink-情感倾向分析【英文】- flink_sentence_encoder_sdk
+ 2). kafka-情感倾向分析【英文】- kafka_sentiment_analysis_sdk
+ ...
+```
+
+
+
+
+
+
+ flink-情感倾向分析【英文】SDK - flink_sentiment_analysis_sdk
+ 情感倾向分析(Sentiment Classification)
+ 针对带有主观描述的文本,可自动判断该文本的情感极性类别并给出相应的置信度。
+ |
+
+
+ 
+ |
+
+
+
+
+ kafka-情感倾向分析【英文】SDK - kafka_sentiment_analysis_sdk
+ 情感倾向分析(Sentiment Classification)
+ 针对带有主观描述的文本,可自动判断该文本的情感极性类别并给出相应的置信度。
+ |
+
+
+
+ |
+
+
+
+
diff --git a/6_web_app/README.md b/6_web_app/README.md
new file mode 100644
index 00000000..1fad4d03
--- /dev/null
+++ b/6_web_app/README.md
@@ -0,0 +1,189 @@
+
+
+
+#### 项目清单:
+- 6_web_app - [Web应用,前端VUE,后端Springboot]
+```text
+ 1). 训练引擎
+ ...
+```
+
+
+
+
+
+
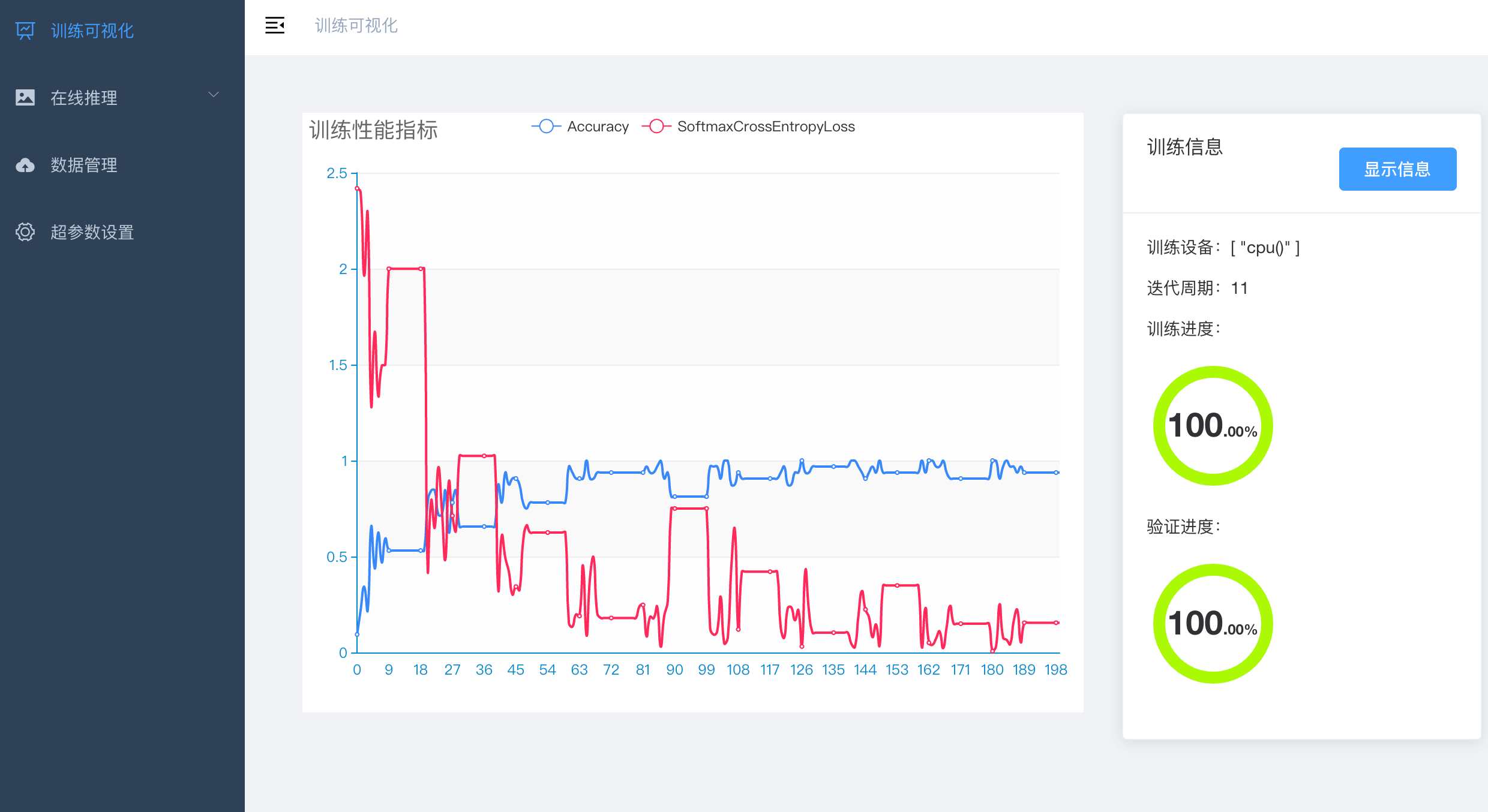
+ AI 训练平台 - training
+ AI训练平台提供分类模型训练能力。
+ 并以REST API形式为上层应用提供接口。
+ |
+
+
+ 
+ |
+
+
+
+
+ 代码语义搜索 - code_search
+ 用于软件开发过程中的,代码搜代码,语义搜代码。 s
+ 1. 代码语义搜索【无向量引擎版】
+ - simple_code_search
+ 主要特性
+ - 支持100万以内的数据量
+ - 随时对数据进行插入、删除、搜索、更新等操作
+ 2. 代码语义搜索【向量引擎版】 - code_search
+ 主要特性
+ - 底层使用特征向量相似度搜索
+ - 单台服务器十亿级数据的毫秒级搜索
+ - 近实时搜索,支持分布式部署
+ - 随时对数据进行插入、删除、搜索、更新等操作
+ |
+
+
+ 
+ |
+
+
+
+
+ 202种语言互相翻译 Web 应用 - text_translation
+ - 支持202种语言互相翻译。
+ - 支持 CPU / GPU
+ |
+
+
+ 
+ |
+
+
+
+
+ 一键抠图 Web 应用 - image_seg
+ 当前版本包含了下面功能:
+ - 1. 通用一键抠图
+ - 2. 人体一键抠图
+ - 3. 动漫一键抠图
+ |
+
+
+ 
+ |
+
+
+
+
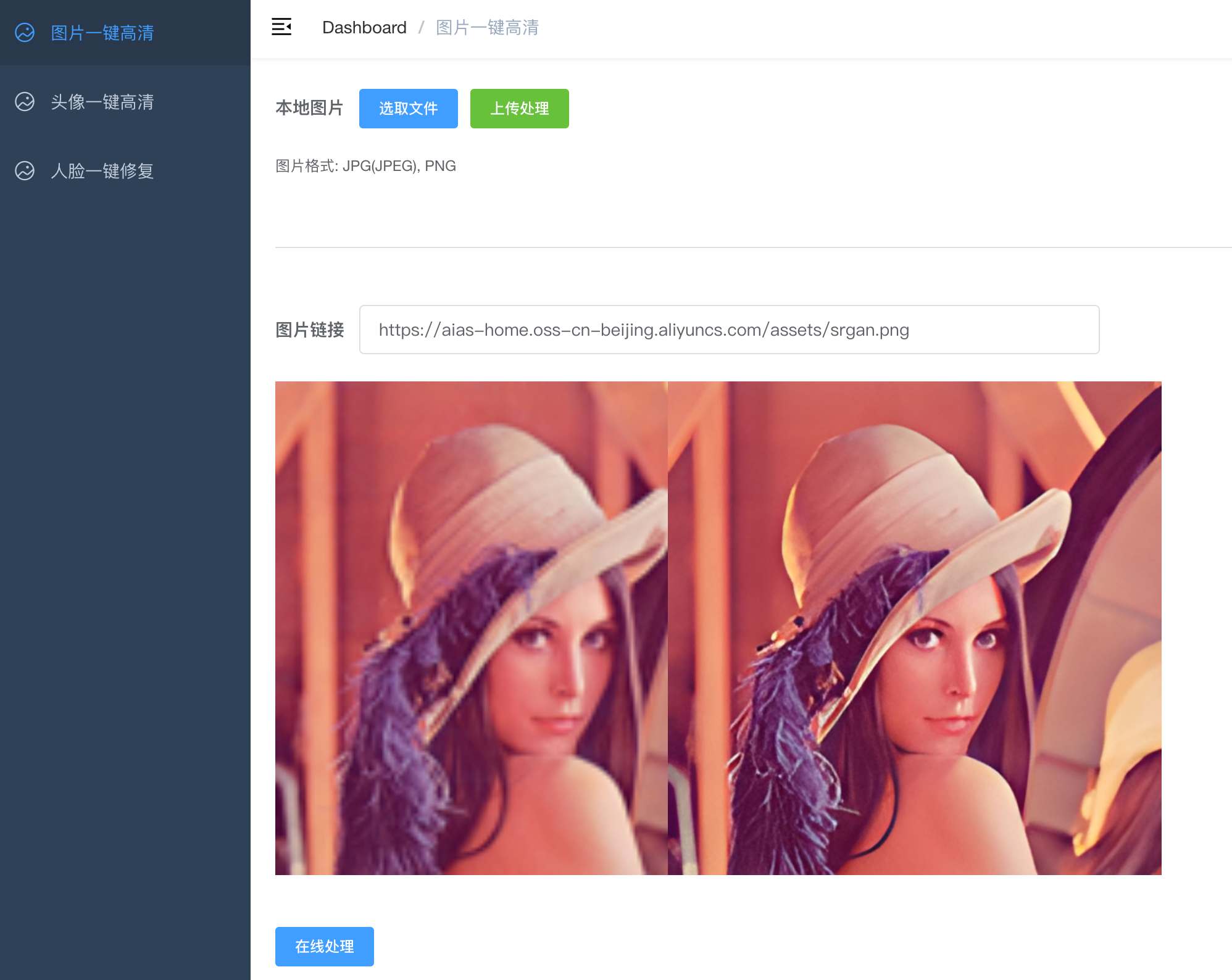
+ 图片一键高清- image_gan
+ 当前版本包含了下面功能:
+ - 图片一键高清: 提升图片4倍分辨率。
+ - 头像一键高清
+ - 人脸一键修复
+ |
+
+
+ 
+ |
+
+
+
+
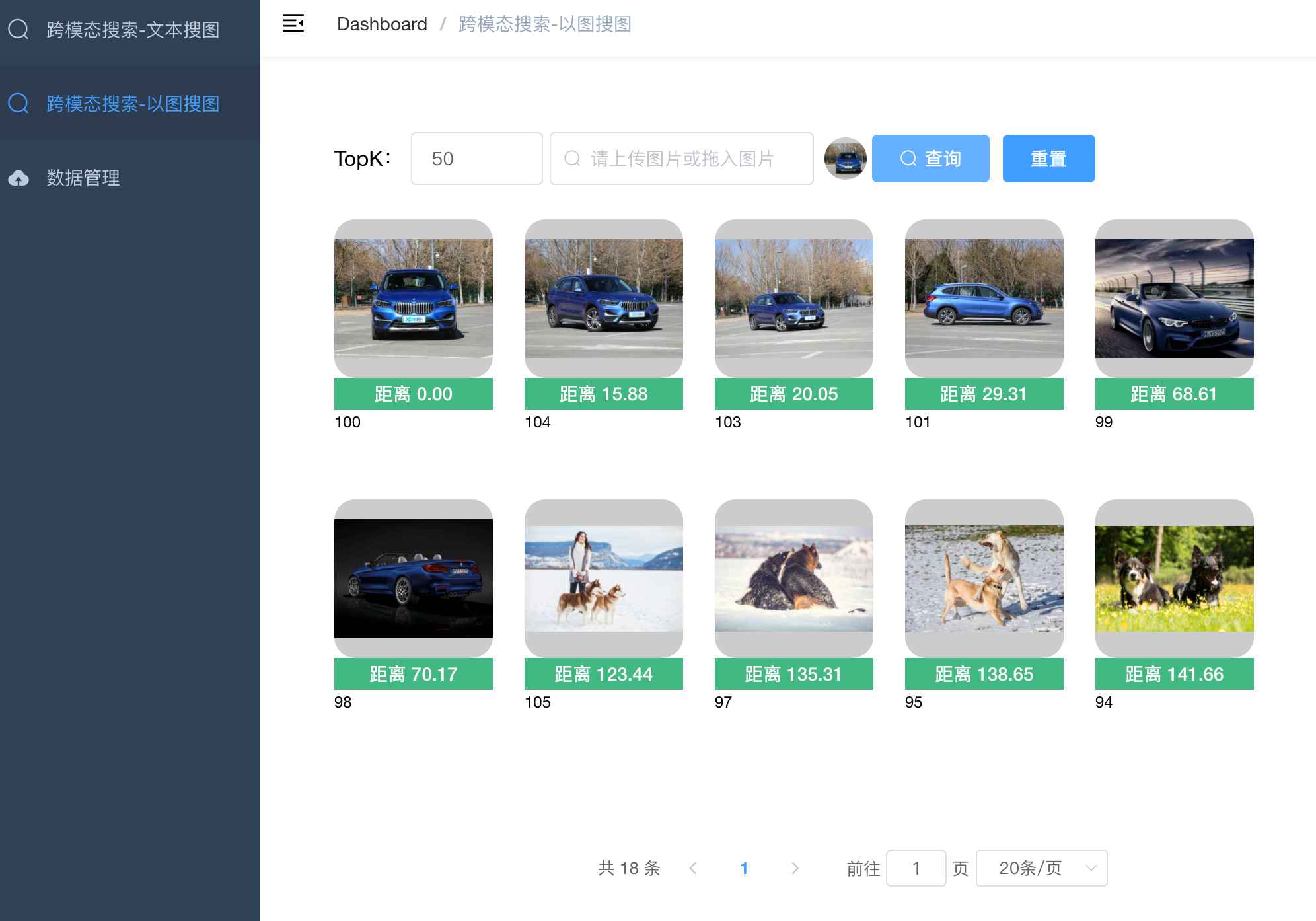
+ 图像&文本的跨模态相似性比对检索【支持40种语言】
+ - image_text_search
+ - 包含两个项目,满足不同场景的需要
+ - 1. 图像&文本的跨模态相似性比对检索
+ 【无向量引擎版】
+ - simple_image_text_search
+ - 支持100万以内的数据量
+ - 随时对数据进行插入、删除、搜索、更新等操作
+ - 2. 图像&文本的跨模态相似性比对检索
+ 【向量引擎版】
+ - image_text_search
+ - 以图搜图:上传图片搜索
+ - 以文搜图:输入文本搜索
+ - 数据管理:提供图像压缩包(zip格式)上传
+ |
+
+
+ 
+ |
+
+
+
+
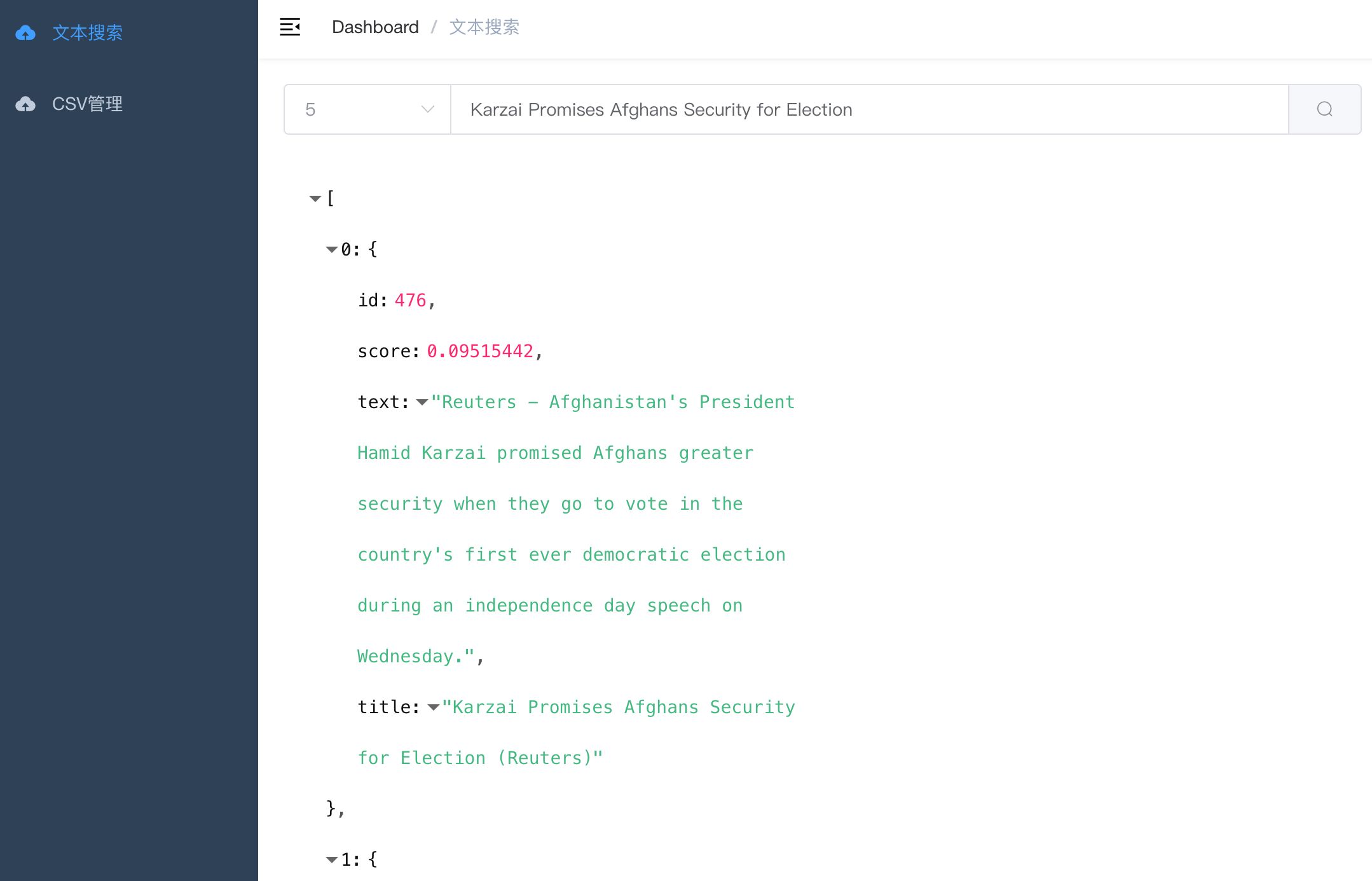
+ 文本向量搜索 - text_search
+ - 包含两个项目,满足不同场景的需要
+ - 1. 文本向量搜索【无向量引擎版】
+ - simple_text_search
+ - 2. 文本向量搜索【向量引擎版】
+ - text_search
+ - 语义搜索,通过句向量相似性, 检索语料库中与query最匹配的文本
+ - 文本聚类,文本转为定长向量, 通过聚类模型可无监督聚集相似文本
+ - 文本分类,表示成句向量, 直接用简单分类器即训练文本分类器
+ - RAG 用于大模型搜索增强生成
+ |
+
+
+ 
+ |
+
+
+
+
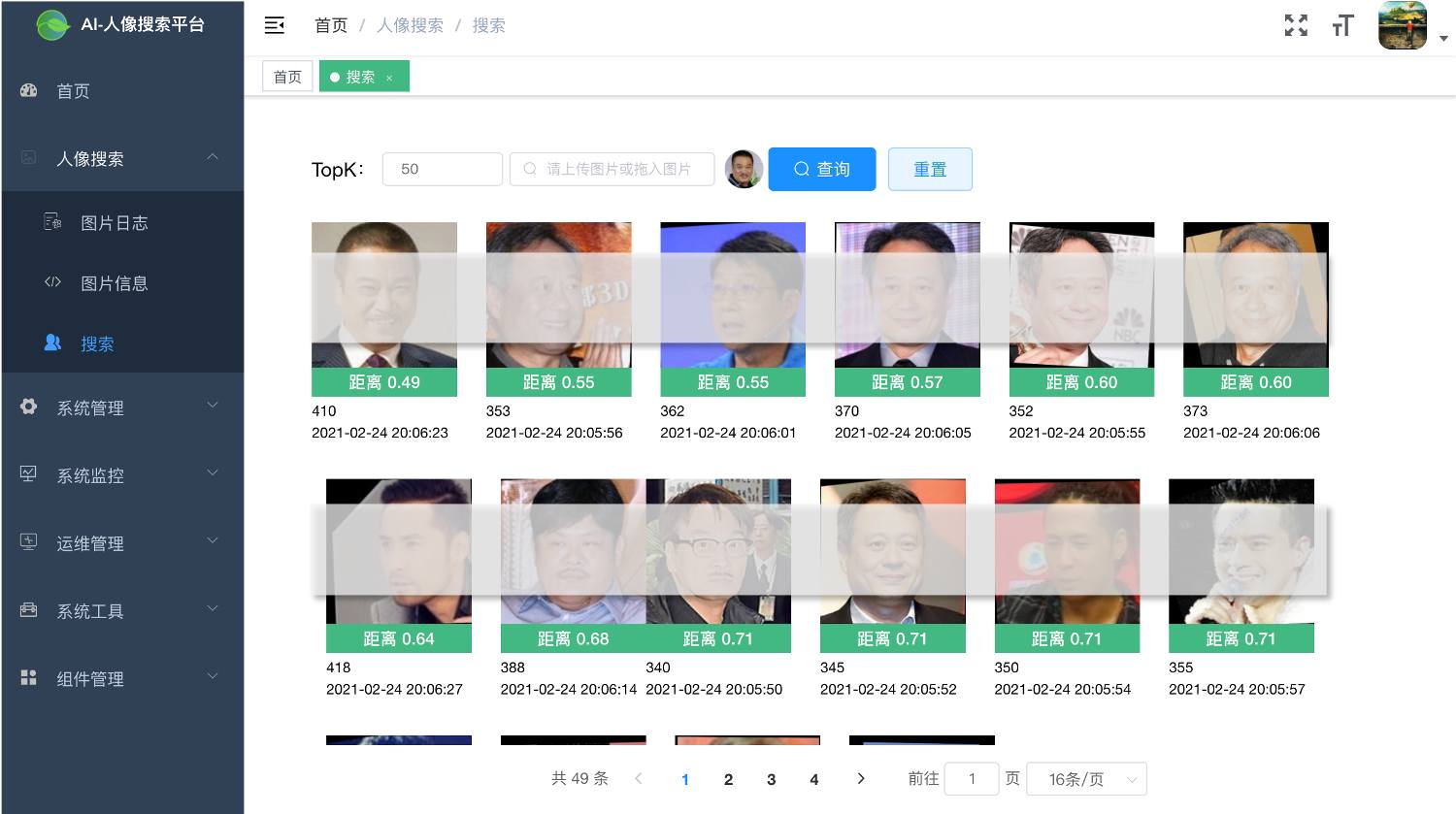
+ 人像搜索 - face_search
+ - 包含两个项目,满足不同场景的需要
+ - 1. 人像搜索【精简版】
+ - simple_face_search
+ - 2. 人像搜索【完整版】
+ - face_search
+ - 搜索管理:提供通用图像搜索, 人像搜索,图像信息查看
+ - 存储管理:提供图像压缩包(zip格式)上传, 人像特征提取,通用特征提取
+ - 用户管理:提供用户的相关配置, 新增用户后,默认密码为123456
+ - 角色管理:对权限与菜单进行分配, 可根据部门设置角色的数据权限
+ - 菜单管理:已实现菜单动态路由, 后端可配置化,支持多级菜单
+ - 部门管理:可配置系统组织架构, 树形表格展示
+ - 岗位管理:配置各个部门的职位
+ - 字典管理:可维护常用一些固定的数据, 如:状态,性别等
+ - 系统日志:记录用户操作日志与异常日志, 方便开发人员定位排错
+ - SQL监控:采用druid 监控数据库访问性能, 默认用户名admin,密码123456
+ - 定时任务:整合Quartz做定时任务, 加入任务日志,任务运行情况一目了然
+ - 服务监控:监控服务器的负载情况
+ |
+
+
+ 
+ |
+
+
+
+
+ 语音识别Web 应用 - asr
+ - 本例子提供了英文语音识别, 中文语音识别。
+ |
+
+
+ 
+ |
+
+
+
+
+
+
diff --git a/6_web_app/asr/README.md b/6_web_app/asr/README.md
new file mode 100644
index 00000000..04db4287
--- /dev/null
+++ b/6_web_app/asr/README.md
@@ -0,0 +1,130 @@
+### 目录:
+https://www.aias.top/
+
+
+### 下载模型,更新 asr_backend 的yaml配置文件
+- 链接: https://pan.baidu.com/s/12DB6Z-f6Akdz8OxsPuoj9A?pwd=6irx
+
+```bash
+model:
+ # 如果是CPU推理,最高设置为 CPU 核心数 (Core Number)
+ poolSize: 2
+ # tiny, base, small
+ type: base
+ uri:
+ # tiny 模型
+ tiny: D:\\ai_projects\\asr\\asr_backend\\models\\traced_whisper_tiny.pt
+ # base 模型
+ base: D:\\ai_projects\\asr\\asr_backend\\models\\traced_whisper_base.pt
+ # small 模型
+ small: D:\\ai_projects\\asr\\asr_backend\\models\\traced_whisper_small.pt
+```
+
+### 语音识别
+本例子提供了英文语音识别,中文语音识别。
+
+### 1. 前端部署
+
+#### 1.1 直接运行:
+```bash
+npm run dev
+```
+
+#### 1.2 构建dist安装包:
+```bash
+npm run build:prod
+```
+
+#### 1.3 nginx部署运行(mac环境为例):
+```bash
+cd /usr/local/etc/nginx/
+vi /usr/local/etc/nginx/nginx.conf
+# 编辑nginx.conf
+
+ server {
+ listen 8080;
+ server_name localhost;
+
+ location / {
+ root /Users/calvin/Documents/asr/dist/;
+ index index.html index.htm;
+ }
+ ......
+
+# 重新加载配置:
+sudo nginx -s reload
+
+# 部署应用后,重启:
+cd /usr/local/Cellar/nginx/1.19.6/bin
+
+# 快速停止
+sudo nginx -s stop
+
+# 启动
+sudo nginx
+```
+
+## 2. 后端jar部署
+#### 2.1 环境要求:
+- 系统JDK 1.8+
+
+- application.yml
+```bash
+model:
+ # 如果是CPU推理,最高设置为 CPU 核心数 (Core Number)
+ poolSize: 2
+ # 提供了三个模型从小到大:tiny, base, small,模型越大速度越慢,精度越高
+ type: base
+ uri:
+ # tiny 模型
+ tiny: D:\\ai_projects\\asr\\asr_backend\\models\\traced_whisper_tiny.pt
+ # base 模型
+ base: D:\\ai_projects\\asr\\asr_backend\\models\\traced_whisper_base.pt
+ # small 模型
+ small: D:\\ai_projects\\asr\\asr_backend\\models\\traced_whisper_small.pt
+```
+
+
+#### 2.2 运行程序:
+```bash
+# 运行程序
+
+java -jar aias-asr-0.1.0.jar
+
+```
+
+## 3. 打开浏览器
+- 输入地址: http://localhost:8090
+
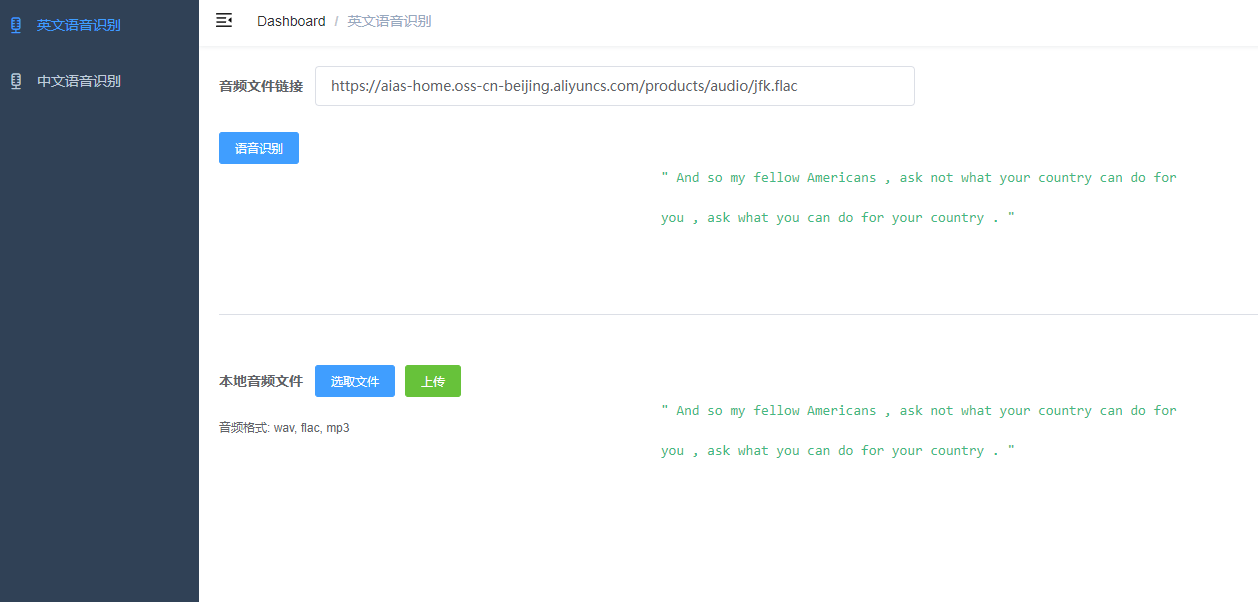
+#### 3.1. 英文语音识别
+- 1). 输入音频文件地址,在线识别
+- 2). 点击上传按钮,上传音频文件识别
+
+
+
+
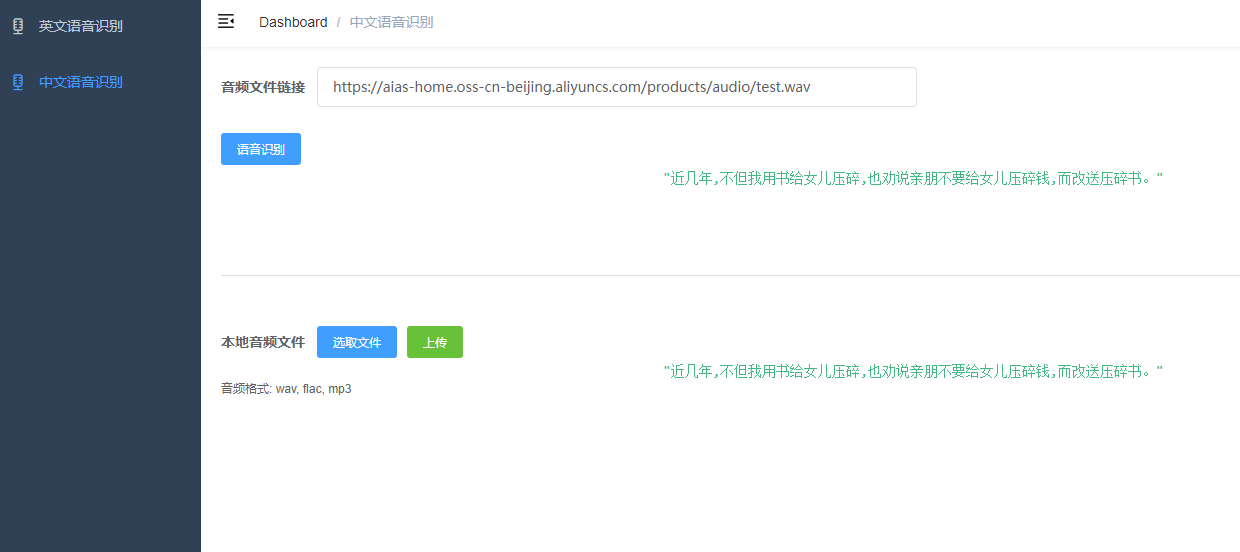
+#### 3.2. 中文语音识别
+- 1). 输入音频文件地址,在线识别
+- 2). 点击上传按钮,上传音频文件识别
+
+
+
+
+## 5. 帮助信息
+- swagger接口文档:
+http://localhost:8089/swagger-ui.html
+
+
+

+
+
+#### 帮助文档:
+- http://aias.top/guides.html
+- 1.性能优化常见问题:
+- http://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- http://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/6_web_app/code_search/README.md b/6_web_app/code_search/README.md
new file mode 100644
index 00000000..e31b88d8
--- /dev/null
+++ b/6_web_app/code_search/README.md
@@ -0,0 +1,21 @@
+## 目录:
+http://aias.top/
+
+
+### 代码语义搜索
+- 包含两个项目,满足不同场景的需要
+
+
+
+### 1. 代码语义搜索【无向量引擎版】 - simple_code_search
+#### 主要特性
+- 支持100万以内的数据量
+- 随时对数据进行插入、删除、搜索、更新等操作
+
+
+### 2. 代码语义搜索【向量引擎版】 - code_search
+#### 主要特性
+- 底层使用特征向量相似度搜索
+- 单台服务器十亿级数据的毫秒级搜索
+- 近实时搜索,支持分布式部署
+- 随时对数据进行插入、删除、搜索、更新等操作
diff --git a/6_web_app/code_search/code_search/README.md b/6_web_app/code_search/code_search/README.md
new file mode 100644
index 00000000..bdb5b541
--- /dev/null
+++ b/6_web_app/code_search/code_search/README.md
@@ -0,0 +1,148 @@
+## 目录:
+http://aias.top/
+
+### 下载模型,放置于models目录
+- 链接:https://pan.baidu.com/s/1eKaVbBwGOcx0IFeYTG0Gjg?pwd=5c0x
+
+
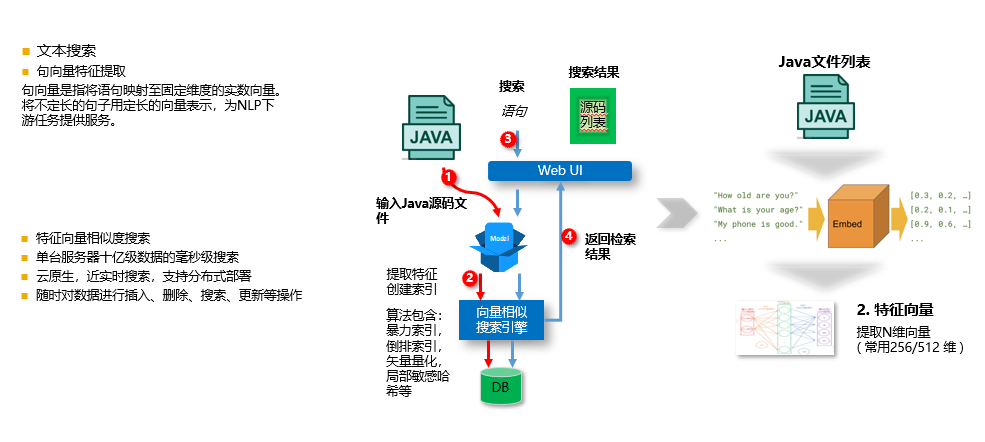
+### 代码语义搜索
+本例子提供了代码语义搜索,支持上传csv文件,使用句向量模型提取特征,并基于milvus向量引擎进行后续检索。
+
+
+
+
+#### 主要特性
+- 底层使用特征向量相似度搜索
+- 单台服务器十亿级数据的毫秒级搜索
+- 近实时搜索,支持分布式部署
+- 随时对数据进行插入、删除、搜索、更新等操作
+
+
+
+### 向量模型【支持15种语言】
+
+向量是指将语句映射至固定维度的实数向量。将不定长的文本用定长的向量表示,为NLP下游任务提供服务。
+
+
+- 句向量
+ 
+
+
+向量应用:
+
+- 语义搜索,通过句向量相似性,检索语料库中与query最匹配的文本
+- 文本聚类,文本转为定长向量,通过聚类模型可无监督聚集相似文本
+- 文本分类,表示成句向量,直接用简单分类器即训练文本分类器
+
+
+
+### 1. 前端部署
+
+#### 1.1 安装运行:
+```bash
+# 安装依赖包
+npm install
+# 运行
+npm run dev
+```
+
+#### 1.2 构建dist安装包:
+```bash
+npm run build:prod
+```
+
+#### 1.3 nginx部署运行(mac环境为例):
+```bash
+cd /usr/local/etc/nginx/
+vi /usr/local/etc/nginx/nginx.conf
+# 编辑nginx.conf
+
+ server {
+ listen 8080;
+ server_name localhost;
+
+ location / {
+ root /Users/calvin/Documents/text_search/dist/;
+ index index.html index.htm;
+ }
+ ......
+
+# 重新加载配置:
+sudo nginx -s reload
+
+# 部署应用后,重启:
+cd /usr/local/Cellar/nginx/1.19.6/bin
+
+# 快速停止
+sudo nginx -s stop
+
+# 启动
+sudo nginx
+```
+
+## 2. 后端jar部署
+#### 2.1 环境要求:
+- 系统JDK 1.8+
+
+
+#### 2.2 运行程序:
+```bash
+# 运行程序
+
+java -jar code-search-0.1.0.jar
+
+```
+
+## 3. 后端向量引擎部署(Milvus 2.2.8)
+#### 3.1 环境要求:
+- 需要安装docker运行环境,Mac环境可以使用Docker Desktop
+
+#### 3.2 拉取Milvus向量引擎镜像(用于计算特征值向量相似度)
+下载 milvus-standalone-docker-compose.yml 配置文件并保存为 docker-compose.yml
+[单机版安装文档](https://milvus.io/docs/v2.2.x)
+```bash
+wget $ wget https://github.com/milvus-io/milvus/releases/download/v2.2.8/milvus-standalone-docker-compose.yml -O docker-compose.yml
+```
+
+#### 3.3 启动 Docker 容器
+```bash
+sudo docker-compose up -d
+```
+
+#### 3.5 编辑向量引擎连接配置信息
+- application.yml
+- 根据需要编辑向量引擎连接ip地址127.0.0.1为容器所在的主机ip
+```bash
+################## 向量引擎 ################
+search:
+ host: 127.0.0.1
+ port: 19530
+```
+
+## 4. 打开浏览器
+- 输入地址: http://localhost:8090
+
+- 上传CSV数据文件
+1). 点击上传按钮上传jsonl文件.
+[测试数据](https://aias-home.oss-cn-beijing.aliyuncs.com/data/testData.jsonl)
+2). 点击特征提取按钮.
+等待文件解析,特征提取,特征存入向量引擎。通过console可以看到进度信息。
+
+
+
+- 相似代码搜索
+ 输入代码片段,点击查询,可以看到返回的清单,根据相似度排序。
+
+
+
+## 5. 帮助信息
+- swagger接口文档:
+http://localhost:8089/swagger-ui.html
+
+
+- 初始化向量引擎(清空数据):
+me.aias.tools.MilvusInit.java
+
+- Milvus向量引擎参考链接
+[Milvus向量引擎官网](https://milvus.io/cn/docs/overview.md)
+[Milvus向量引擎Github](https://github.com/milvus-io)
diff --git a/6_web_app/code_search/simple_code_search/README.md b/6_web_app/code_search/simple_code_search/README.md
new file mode 100644
index 00000000..d3aa3864
--- /dev/null
+++ b/6_web_app/code_search/simple_code_search/README.md
@@ -0,0 +1,90 @@
+## 目录:
+http://aias.top/
+
+### 下载模型,放置于models目录
+- 链接:https://pan.baidu.com/s/1eKaVbBwGOcx0IFeYTG0Gjg?pwd=5c0x
+
+
+### 代码语义搜索【无向量引擎版】 - simple_code_search
+#### 主要特性
+- 支持100万以内的数据量
+- 随时对数据进行插入、删除、搜索、更新等操作
+
+
+### 1. 前端部署
+
+#### 1.1 安装运行:
+```bash
+# 安装依赖包
+npm install
+# 运行
+npm run dev
+```
+
+#### 1.2 构建dist安装包:
+```bash
+npm run build:prod
+```
+
+#### 1.3 nginx部署运行(mac环境为例):
+```bash
+cd /usr/local/etc/nginx/
+vi /usr/local/etc/nginx/nginx.conf
+# 编辑nginx.conf
+
+ server {
+ listen 8080;
+ server_name localhost;
+
+ location / {
+ root /Users/calvin/Documents/text_search/dist/;
+ index index.html index.htm;
+ }
+ ......
+
+# 重新加载配置:
+sudo nginx -s reload
+
+# 部署应用后,重启:
+cd /usr/local/Cellar/nginx/1.19.6/bin
+
+# 快速停止
+sudo nginx -s stop
+
+# 启动
+sudo nginx
+```
+
+## 2. 后端jar部署
+#### 2.1 环境要求:
+- 系统JDK 1.8+
+
+
+#### 2.2 运行程序:
+```bash
+# 运行程序
+
+java -jar code-search-0.1.0.jar
+
+```
+
+## 3. 打开浏览器
+- 输入地址: http://localhost:8090
+
+- 上传CSV数据文件
+1). 点击上传按钮上传jsonl文件.
+[测试数据](https://aias-home.oss-cn-beijing.aliyuncs.com/data/testData.jsonl)
+2). 点击特征提取按钮.
+等待文件解析,特征提取。通过console可以看到进度信息。
+
+
+- 相似代码搜索
+ 输入代码片段,点击查询,可以看到返回的清单,根据相似度排序。
+
+
+
+## 5. 帮助信息
+- swagger接口文档:
+http://localhost:8089/swagger-ui.html
+
+
diff --git a/6_web_app/face_search/README.md b/6_web_app/face_search/README.md
new file mode 100644
index 00000000..300634a1
--- /dev/null
+++ b/6_web_app/face_search/README.md
@@ -0,0 +1,73 @@
+## 目录:
+http://aias.top/
+
+
+### 人像搜索
+
+
+
+
+
+#### 主要特性
+- 底层使用特征向量相似度搜索
+- 单台服务器十亿级数据的毫秒级搜索
+- 近实时搜索,支持分布式部署
+- 随时对数据进行插入、删除、搜索、更新等操作
+- 支持在线用户管理与服务器性能监控,支持限制单用户登录
+
+
+### 1. 人像搜索【精简版】 - simple_face_search
+#### 功能介绍
+- 人像搜索:上传人像图片搜索
+- 数据管理:提供图像压缩包(zip格式)上传,人像特征提取
+
+
+### 2. 人像搜索【完整版】 - face_search
+#### 功能介绍
+- 搜索管理:提供通用图像搜索,人像搜索,图像信息查看
+- 存储管理:提供图像压缩包(zip格式)上传,人像特征提取,通用特征提取
+- 用户管理:提供用户的相关配置,新增用户后,默认密码为123456
+- 角色管理:对权限与菜单进行分配,可根据部门设置角色的数据权限
+- 菜单管理:已实现菜单动态路由,后端可配置化,支持多级菜单
+- 部门管理:可配置系统组织架构,树形表格展示
+- 岗位管理:配置各个部门的职位
+- 字典管理:可维护常用一些固定的数据,如:状态,性别等
+- 系统日志:记录用户操作日志与异常日志,方便开发人员定位排错
+- SQL监控:采用druid 监控数据库访问性能,默认用户名admin,密码123456
+- 定时任务:整合Quartz做定时任务,加入任务日志,任务运行情况一目了然
+- 服务监控:监控服务器的负载情况
+
+
+#### 功能演示
+- 登录
+
+

+
+
+- 用户管理
+
+
+
+
+- 角色管理
+
+
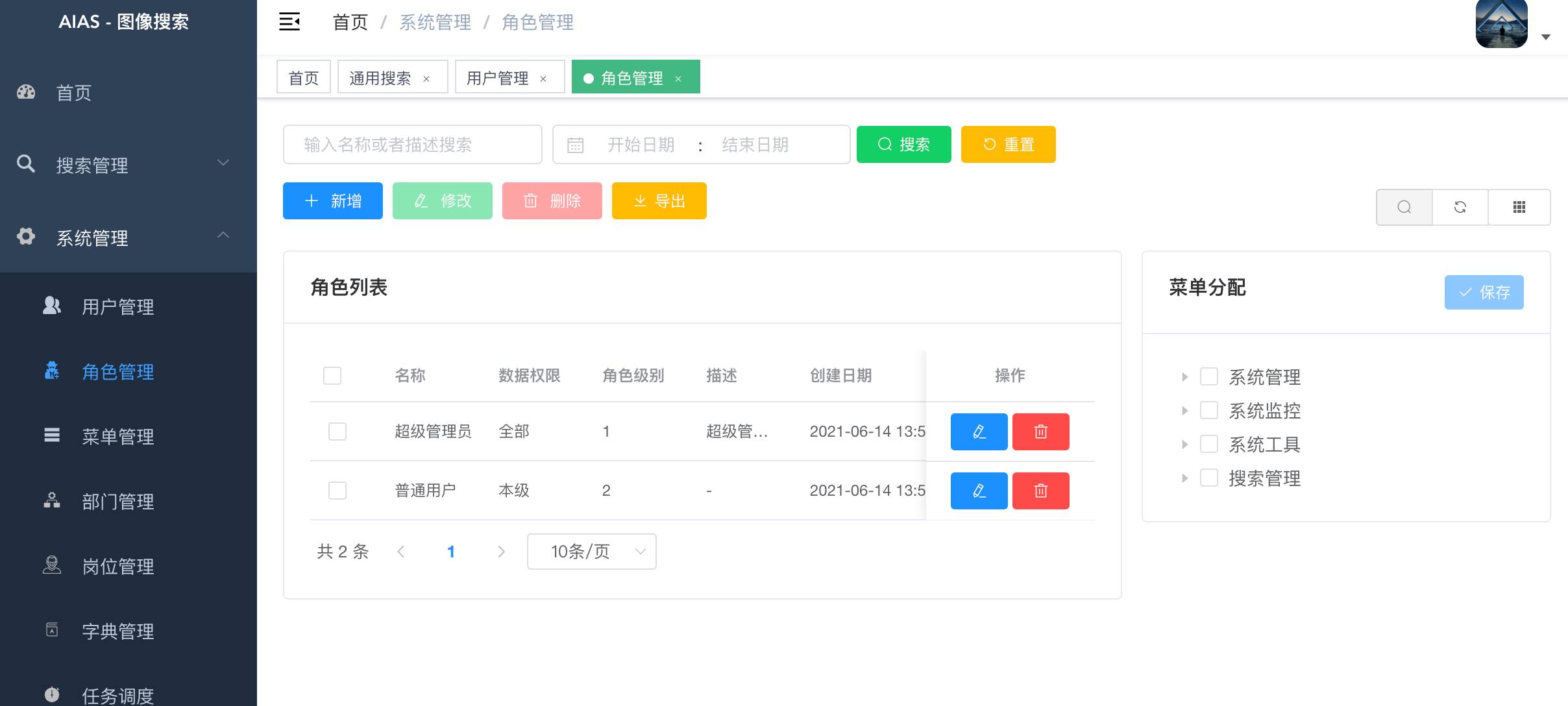
+
+
+- 运维管理
+
+
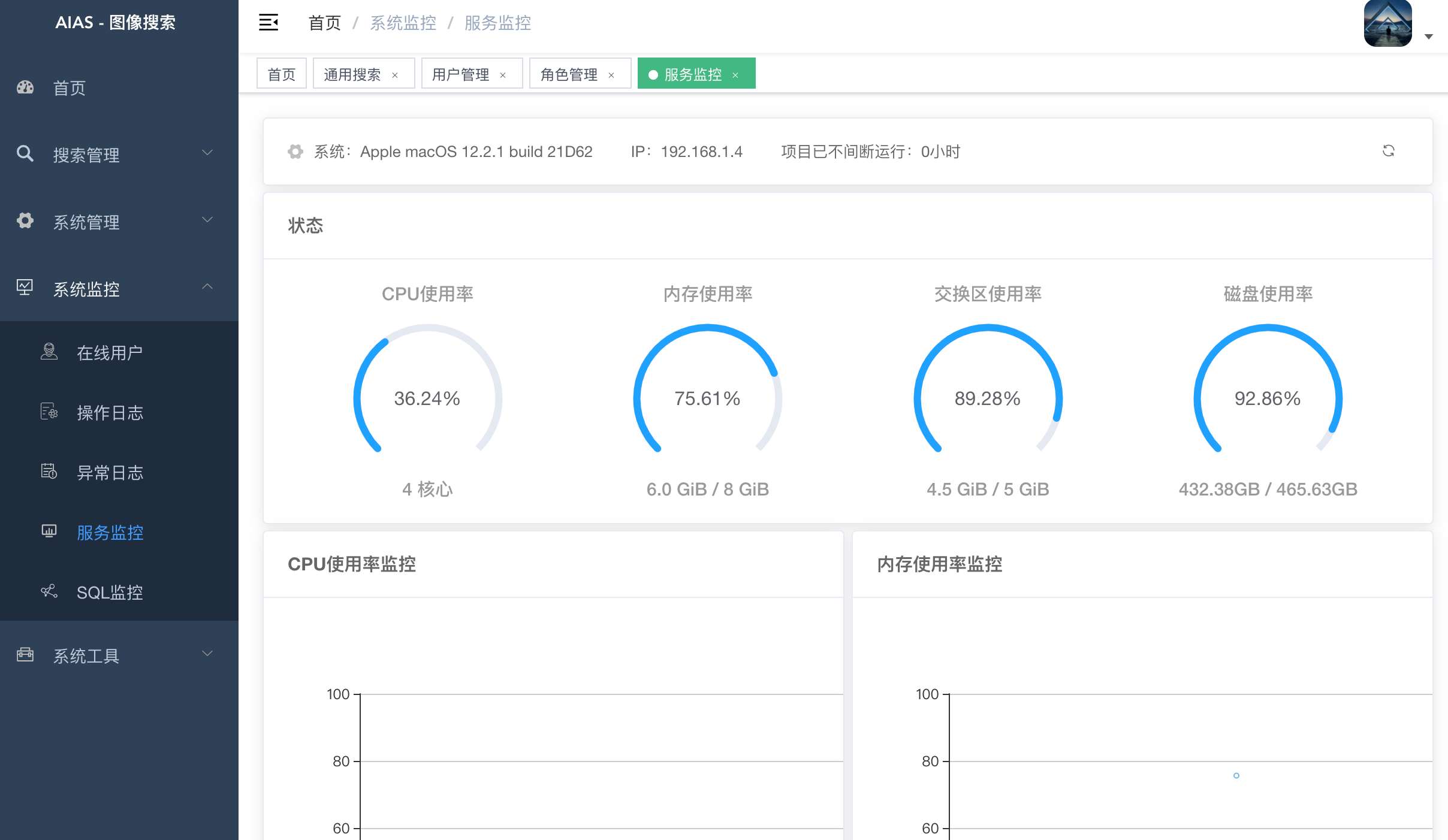
+
+
+- 图片上传
+1). 支持zip压缩包上传.
+2). 支持服务器端文件夹上传(大量图片上传使用,比如几十万张图片入库).
+3). 支持客户端文件夹上传.
+
+
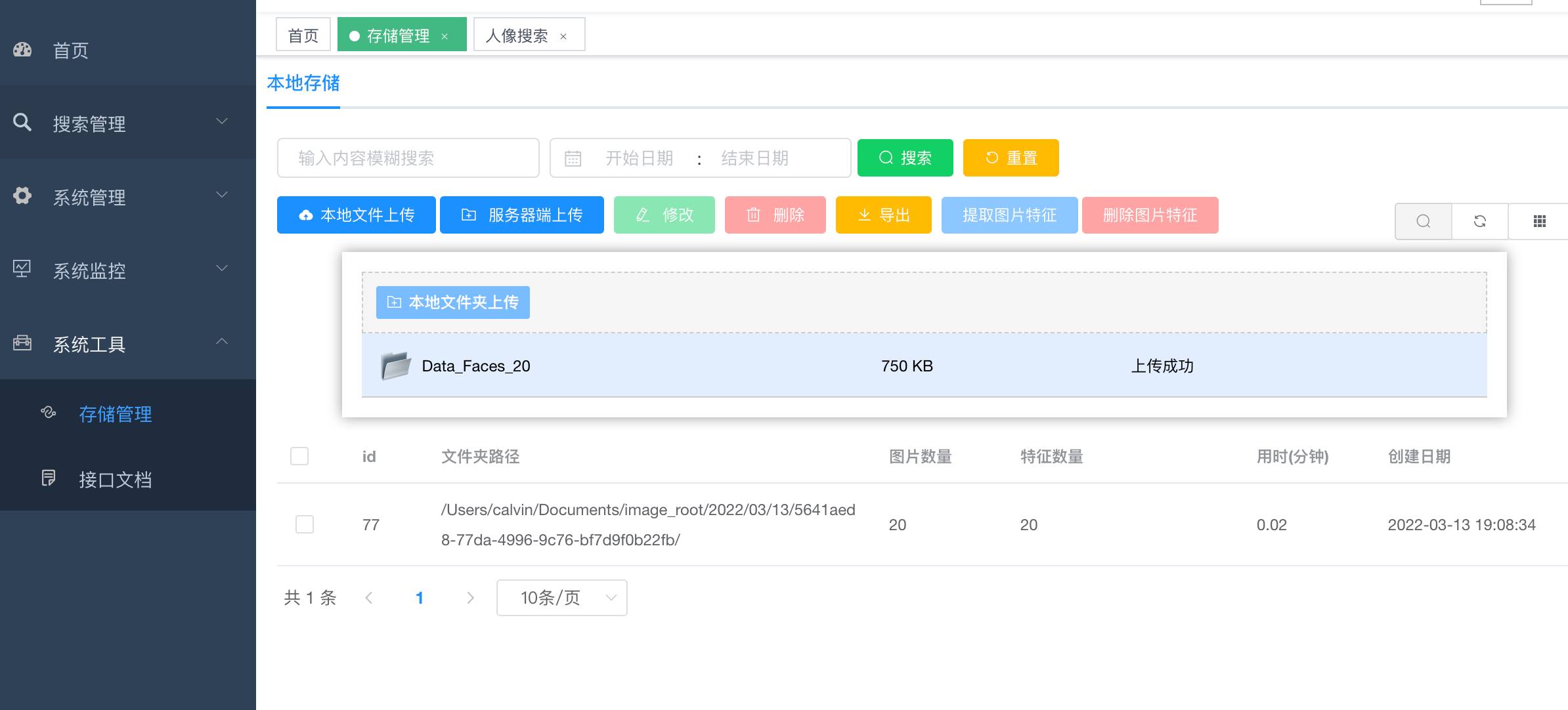
+
+
+- 人像搜索
+
+
+
diff --git a/6_web_app/face_search/face_search/README.md b/6_web_app/face_search/face_search/README.md
new file mode 100644
index 00000000..4ed3a608
--- /dev/null
+++ b/6_web_app/face_search/face_search/README.md
@@ -0,0 +1,228 @@
+
+
+
+### 人像搜索
+
+
+
+
+### 下载模型,更新 face_vector_search 的yaml配置文件
+- 链接: https://pan.baidu.com/s/1XbMhZ4c1B-7hKKpCJMte2Q?pwd=ctva
+
+```bash
+# Model URI
+#Face
+face:
+ saveDetectedFace: true
+ # 高精度大模型 retinaface detection model URI
+ retinaface: /Users/calvin/ai_projects/face_search_bak/simple_face_search/face_search/models/retinaface.onnx
+ # 速度快小模型,精度低于大模型 mobilenet face detection model URI
+ mobilenet: /Users/calvin/ai_projects/face_search_bak/simple_face_search/face_search/models/mobilenet.onnx
+ # face feature model URI
+ feature: /Users/calvin/ai_projects/face_search_bak/simple_face_search/face_search/models/face_feature.onnx
+
+model:
+ # 设置为 CPU 核心数 (Core Number)
+ poolSize: 4
+```
+
+#### 主要特性
+- 底层使用特征向量相似度搜索
+- 单台服务器十亿级数据的毫秒级搜索
+- 近实时搜索,支持分布式部署
+- 随时对数据进行插入、删除、搜索、更新等操作
+- 支持在线用户管理与服务器性能监控,支持限制单用户登录
+
+#### 系统功能
+- 搜索管理:提供通用图像搜索,人像搜索,图像信息查看
+- 存储管理:提供图像压缩包(zip格式)上传,人像特征提取,通用特征提取
+- 用户管理:提供用户的相关配置,新增用户后,默认密码为123456
+- 角色管理:对权限与菜单进行分配,可根据部门设置角色的数据权限
+- 菜单管理:已实现菜单动态路由,后端可配置化,支持多级菜单
+- 部门管理:可配置系统组织架构,树形表格展示
+- 岗位管理:配置各个部门的职位
+- 字典管理:可维护常用一些固定的数据,如:状态,性别等
+- 系统日志:记录用户操作日志与异常日志,方便开发人员定位排错
+- SQL监控:采用druid 监控数据库访问性能,默认用户名admin,密码123456
+- 定时任务:整合Quartz做定时任务,加入任务日志,任务运行情况一目了然
+- 服务监控:监控服务器的负载情况
+
+
+#### 功能介绍
+- 登录
+
+
+
+
+- 用户管理
+
+
+
+
+- 角色管理
+
+
+
+
+- 运维管理
+
+
+
+
+- 图片上传
+1). 支持zip压缩包上传.
+2). 支持服务器端文件夹上传(大量图片上传使用,比如几十万张图片入库).
+3). 支持客户端文件夹上传.
+
+
+
+
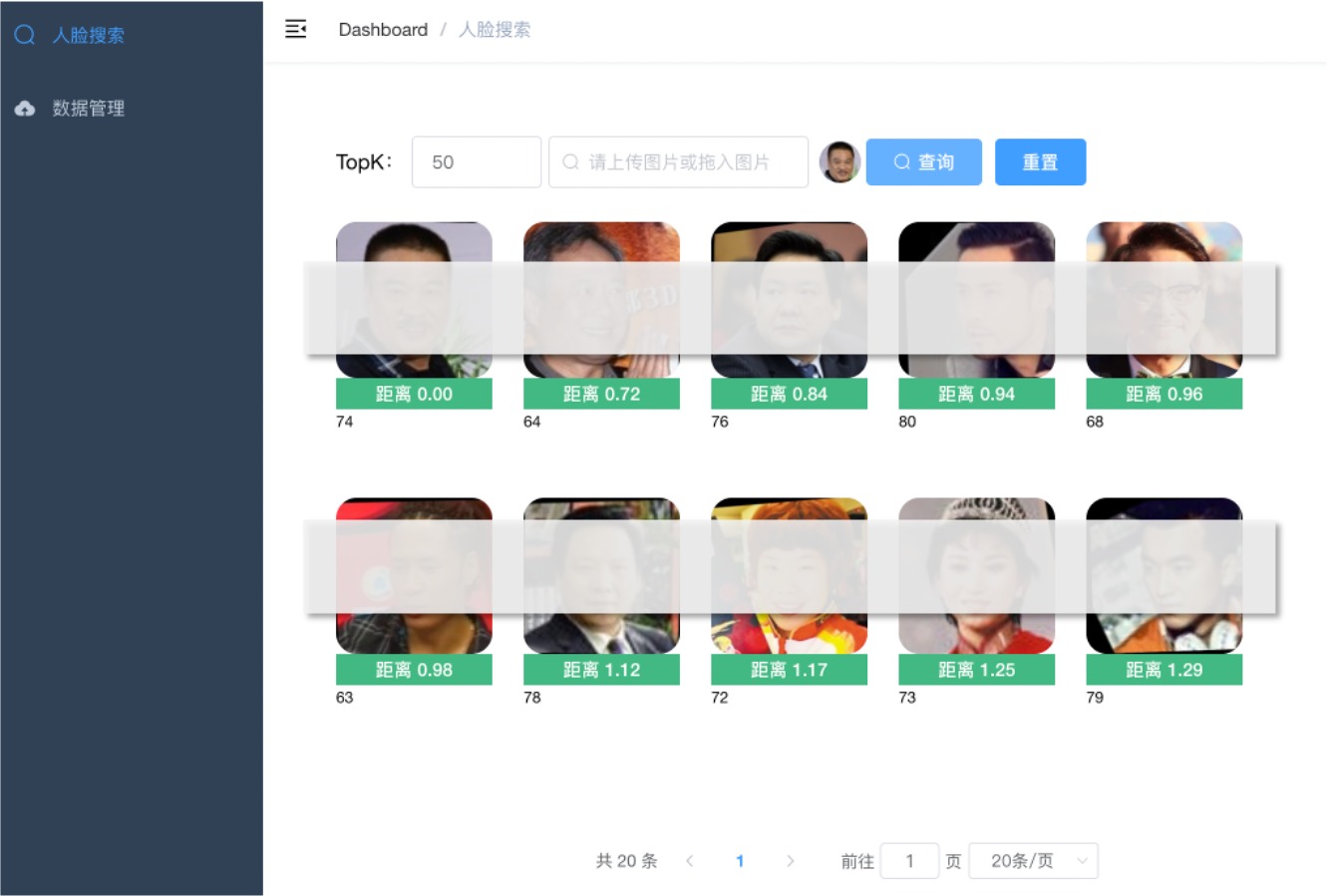
+- 人像搜索
+
+
+
+
+
+### 1. 前端部署
+
+#### 1.1 直接运行:
+```bash
+npm run dev
+```
+
+#### 1.2 构建dist安装包:
+```bash
+npm run build:prod
+```
+
+#### 1.3 nginx部署运行(mac环境部署管理前端为例):
+```bash
+cd /usr/local/etc/nginx/
+vi /usr/local/etc/nginx/nginx.conf
+# 编辑nginx.conf
+
+ server {
+ listen 8080;
+ server_name localhost;
+
+ location / {
+ root /Users/calvin/face_vector_search_ui/dist/;
+ index index.html index.htm;
+ }
+ ......
+
+# 重新加载配置:
+sudo nginx -s reload
+
+# 部署应用后,重启:
+cd /usr/local/Cellar/nginx/1.19.6/bin
+
+# 快速停止
+sudo nginx -s stop
+
+# 启动
+sudo nginx
+```
+
+### 2. 后端jar部署
+#### 环境要求:
+- 系统JDK 1.8+
+- 需要安装并redis
+- 需要安装MySQL数据库
+
+
+### 3. 后端向量引擎部署
+
+#### 3.1 环境要求:
+- 需要安装docker运行环境,Mac环境可以使用Docker Desktop
+
+#### 3.2 拉取Milvus向量引擎镜像(用于计算特征值向量相似度)
+下载 milvus-standalone-docker-compose.yml 配置文件并保存为 docker-compose.yml
+
+[单机版安装文档](https://milvus.io/docs/install_standalone-docker.md)
+[引擎配置文档](https://milvus.io/docs/configure-docker.md)
+[milvus-sdk-java](https://github.com/milvus-io/milvus-sdk-java)
+
+
+```bash
+# 例子:v2.2.11,请根据官方文档,选择合适的版本
+wget https://github.com/milvus-io/milvus/releases/download/v2.2.11/milvus-standalone-docker-compose.yml -O docker-compose.yml
+```
+
+#### 3.3 启动 Docker 容器
+```bash
+sudo docker-compose up -d
+```
+
+#### 3.4 编辑向量引擎连接配置信息
+- application.yml
+- 根据需要编辑向量引擎连接ip地址127.0.0.1为容器所在的主机ip
+```bash
+##################### 向量引擎 ###############################
+search:
+ host: 127.0.0.1
+ port: 19530
+ indexFileSize: 1024 # maximum size (in MB) of each index file
+ nprobe: 256
+ nlist: 16384
+ dimension: 128 #dimension of each vector
+ collectionName: face_search #collection name
+
+```
+
+#### 3.5 启动redis(mac环境为例)
+```bash
+nohup /usr/local/bin/redis-server &
+```
+
+#### 3.6 启动MySQL,并导入sql DLL
+```bash
+# Start MySQL
+sudo /usr/local/mysql/support-files/mysql.server start
+
+# sql 文件位置:
+# face_vector_search/sql/data.sql
+# 导入 data.sql, 如:使用 MySQL WorkBench 之类工具导入。
+```
+
+### 4. 运行程序:
+使用IDE运行 AppRun:
+位置:face_vector_search/aiplatform-system/src/main/java/me/calvin/AppRun
+或者运行编译后的jar:
+```bash
+# 运行程序
+nohup java -Dfile.encoding=utf-8 -jar xxxxx-1.0.jar > log.txt 2>&1 &
+```
+
+### 5. 打开浏览器
+- 输入地址: http://localhost:8089
+
+- 图片上传
+1). 点击上传按钮上传zip压缩包.
+2). 点击提取人脸特征按钮.
+
+
+- 人像搜索
+
+
+
+### 6. 重置Milvus向量引擎(清空数据)
+- :
+```bash
+# face_vector_search/aiplatform-system/src/main/java/me/calvin/modules/search/tools
+MilvusInit.java
+```
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/6_web_app/face_search/simple_face_search/README.md b/6_web_app/face_search/simple_face_search/README.md
new file mode 100644
index 00000000..92539450
--- /dev/null
+++ b/6_web_app/face_search/simple_face_search/README.md
@@ -0,0 +1,165 @@
+### 目录:
+https://aias.top/
+
+
+
+### 下载模型,更新 face_vector_search 的yaml配置文件
+- 链接: https://pan.baidu.com/s/1XbMhZ4c1B-7hKKpCJMte2Q?pwd=ctva
+
+```bash
+# Model URI
+#Face
+face:
+ saveDetectedFace: true
+ # 高精度大模型 retinaface detection model URI
+ retinaface: /Users/calvin/ai_projects/face_search_bak/simple_face_search/face_search/models/retinaface.onnx
+ # 速度快小模型,精度低于大模型 mobilenet face detection model URI
+ mobilenet: /Users/calvin/ai_projects/face_search_bak/simple_face_search/face_search/models/mobilenet.onnx
+ # face feature model URI
+ feature: /Users/calvin/ai_projects/face_search_bak/simple_face_search/face_search/models/face_feature.onnx
+
+model:
+ # 设置为 CPU 核心数 (Core Number)
+ poolSize: 4
+```
+
+
+### 人脸大数据搜索介绍
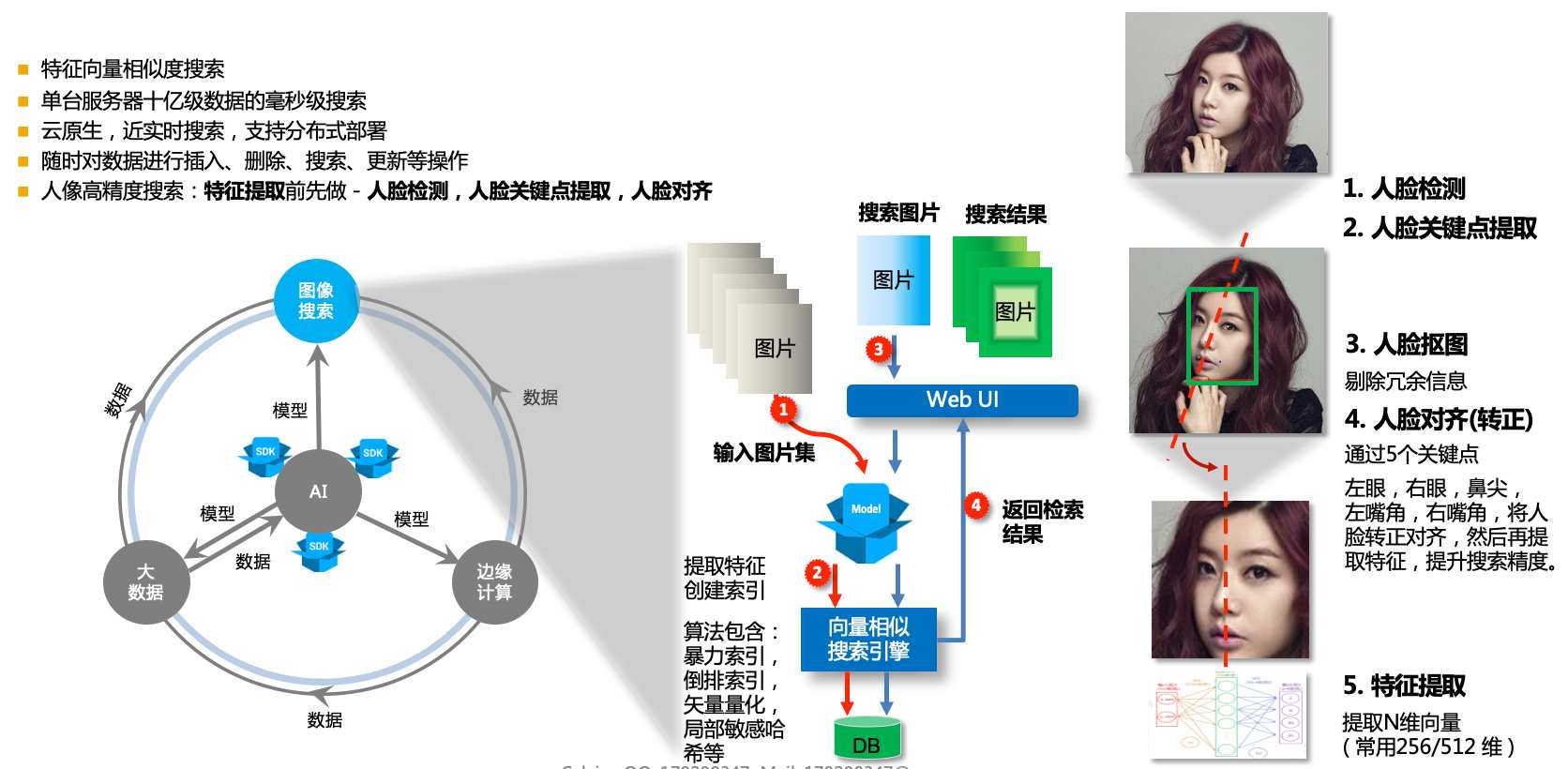
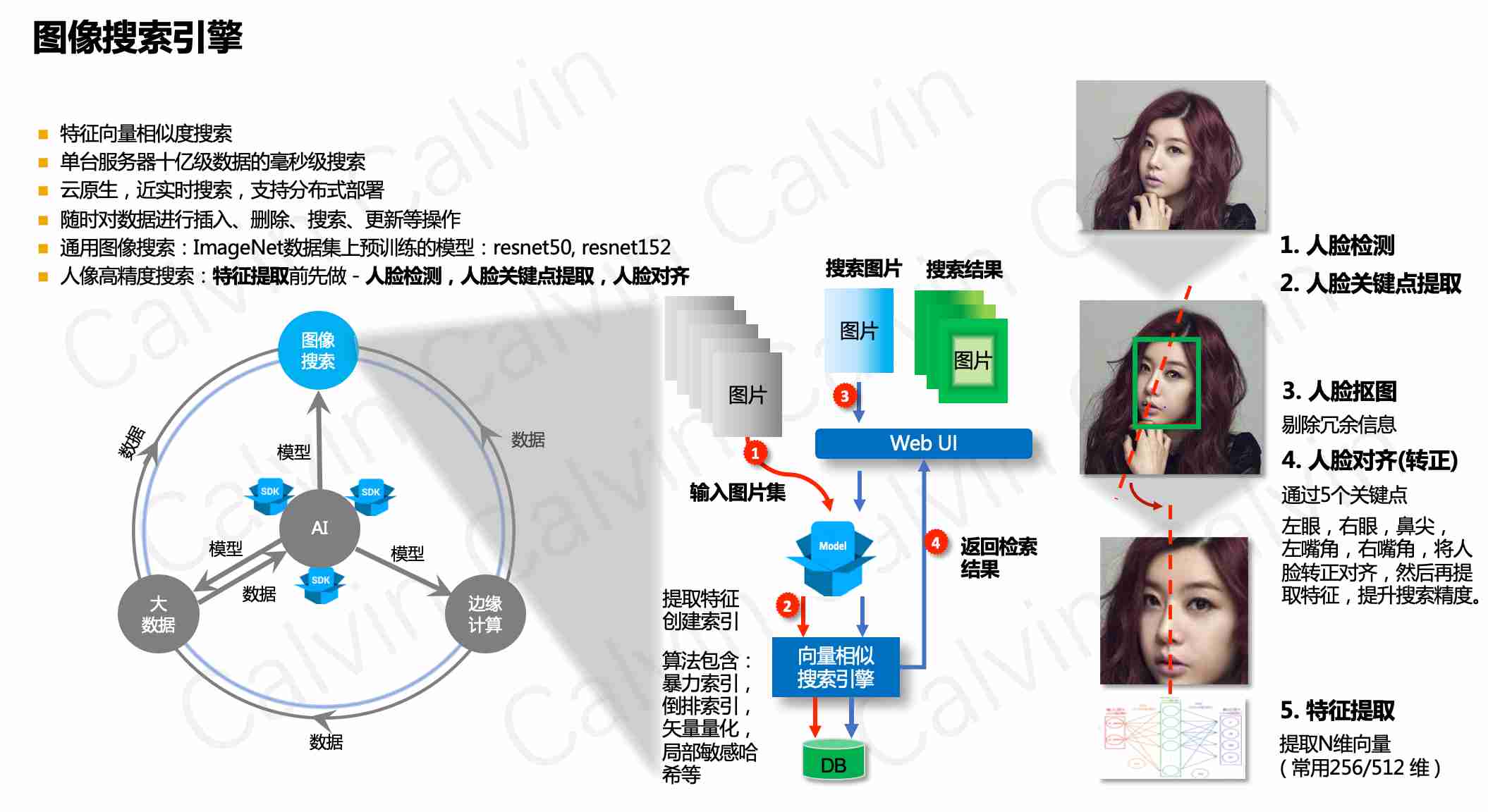
+- 人像高精度搜索:人脸特征提取(使用人脸特征模型提取128维特征)前先做 - 人脸检测,人脸关键点提取,人脸对齐
+
+
+
+
+#### 主要特性
+- 底层使用特征向量相似度搜索
+- 单台服务器十亿级数据的毫秒级搜索
+- 近实时搜索,支持分布式部署
+- 随时对数据进行插入、删除、搜索、更新等操作
+
+#### 功能介绍
+- 人像搜索:上传人像图片搜索
+- 数据管理:提供图像压缩包(zip格式)上传,人像特征提取
+
+### 1. 前端部署
+
+#### 1.1 直接运行:
+```bash
+npm run dev
+```
+
+#### 1.2 构建dist安装包:
+```bash
+npm run build:prod
+```
+
+#### 1.3 nginx部署运行(mac环境为例):
+```bash
+cd /usr/local/etc/nginx/
+vi /usr/local/etc/nginx/nginx.conf
+# 编辑nginx.conf
+
+ server {
+ listen 8080;
+ server_name localhost;
+
+ location / {
+ root /Users/calvin/face_search/dist/;
+ index index.html index.htm;
+ }
+ ......
+
+# 重新加载配置:
+sudo nginx -s reload
+
+# 部署应用后,重启:
+cd /usr/local/Cellar/nginx/1.19.6/bin
+
+# 快速停止
+sudo nginx -s stop
+
+# 启动
+sudo nginx
+```
+
+## 2. 后端jar部署
+#### 2.1 环境要求:
+- 系统JDK 1.8+
+- 需要安装redis
+- 需要安装MySQL数据库
+
+#### 2.2 运行程序:
+```bash
+# 运行程序
+
+java -jar face-search-1.0.jar
+
+```
+
+### 3. 后端向量引擎部署
+
+#### 3.1 环境要求:
+- 需要安装docker运行环境,Mac环境可以使用Docker Desktop
+
+#### 3.2 拉取Milvus向量引擎镜像(用于计算特征值向量相似度)
+下载 milvus-standalone-docker-compose.yml 配置文件并保存为 docker-compose.yml
+
+[单机版安装文档](https://milvus.io/docs/install_standalone-docker.md)
+[引擎配置文档](https://milvus.io/docs/configure-docker.md)
+[milvus-sdk-java](https://github.com/milvus-io/milvus-sdk-java)
+
+
+```bash
+# 例子:v2.2.11,请根据官方文档,选择合适的版本
+wget https://github.com/milvus-io/milvus/releases/download/v2.2.11/milvus-standalone-docker-compose.yml -O docker-compose.yml
+```
+
+#### 3.3 启动 Docker 容器
+```bash
+sudo docker-compose up -d
+```
+
+#### 3.4 编辑向量引擎连接配置信息
+- application.yml
+- 根据需要编辑向量引擎连接ip地址127.0.0.1为容器所在的主机ip
+```bash
+##################### 向量引擎 ###############################
+search:
+ host: 127.0.0.1
+ port: 19530
+ indexFileSize: 1024 # maximum size (in MB) of each index file
+ nprobe: 256
+ nlist: 16384
+ dimension: 128 #dimension of each vector
+ collectionName: face_search #collection name
+
+```
+
+## 4. 打开浏览器
+- 输入地址: http://localhost:8089
+
+- 图片上传
+1). 点击上传按钮上传zip压缩包.
+2). 点击提取人脸特征按钮.
+
+
+- 人像搜索
+
+
+
+- 重置Milvus向量引擎(清空数据):
+```bash
+top.aias.tools.MilvusInit.java
+```
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
diff --git a/6_web_app/image_gan/README.md b/6_web_app/image_gan/README.md
new file mode 100644
index 00000000..cd296f0c
--- /dev/null
+++ b/6_web_app/image_gan/README.md
@@ -0,0 +1,115 @@
+### 目录:
+https://www.aias.top/
+
+### 下载模型,配置yml文件 image_backend\src\main\resources\application-xxx.yml
+- 链接: https://pan.baidu.com/s/1H1EQvrgMfb07pXyyHsFQXQ?pwd=bpm1
+```bash
+model:
+ # 设备类型 cpu gpu
+ device: cpu
+ # 最大设置为 CPU 核心数 (Core Number)
+ poolSize: 1
+ # 模型路径
+ modelPath: D:\\ai_projects\\products\\4_apps\\image_gan\\image_backend\\models\\
+ # 人脸检测模型
+ faceModelName: retinaface_traced_model.pt
+ # 人像分割模型
+ faceSegModelName: parsenet_traced_model.pt
+ # 人脸修复模型
+ faceGanModelName: gfpgan_traced_model.pt
+ # 图像超分模型
+ srModelName: realsr_traced_model.pt
+```
+
+
+### 图像增强
+图像超分辨是指通过使用计算机算法将低分辨率图像转换为高分辨率图像的过程。在图像超分辨的任务中,我们希望通过增加图像的细节和清晰度来提高图像的质量。
+图像超分辨的挑战在于从有限的信息中恢复丢失的细节。低分辨率图像通常由于传感器限制、图像压缩或其他因素而失去了细节。图像超分辨技术通过利用图像中的上下文信息和统计特征来推测丢失的细节。
+目前,有多种图像超分辨方法可供选择,包括基于插值的方法、基于边缘的方法、基于学习的方法等。其中,基于学习的方法在图像超分辨领域取得了显著的进展。这些方法使用深度学习模型,如卷积神经网络(CNN)或生成对抗网络(GAN),通过训练大量的图像样本来学习图像的高频细节和结构,从而实现图像超分辨。
+图像超分辨技术在许多领域都有应用,包括医学影像、安防监控、视频增强等。它可以改善图像的视觉质量,提供更多细节和清晰度,有助于改善图像分析、图像识别和人机交互等任务的准确性和效果。
+人工智能图片人脸修复是一种应用计算机视觉技术和深度学习算法进行图像修复的方法。这种技术可以自动识别图像中的人脸,并进行修复和还原,从而使图像更加完整、清晰和自然。相较于传统的图像修复方法,人工智能图片人脸修复更加高效和准确。它可以快速地修复照片中的缺陷,例如面部皮肤瑕疵、眼睛或嘴巴的闭合问题等,使其看起来更加美观自然。这种技术在图像处理、医学影像、电影制作等领域都有着广泛的应用前景,并且随着人工智能技术的不断发展,其应用领域也会越来越广泛。
+
+
+当前版本包含了下面功能:
+- 图片一键高清: 提升图片4倍分辨率。
+- 头像一键高清
+- 人脸一键修复
+
+
+### 1. 前端部署
+
+#### 1.1 直接运行:
+```bash
+npm run dev
+```
+
+#### 1.2 构建dist安装包:
+```bash
+npm run build:prod
+```
+
+#### 1.3 nginx部署运行(mac环境部署管理前端为例):
+```bash
+cd /usr/local/etc/nginx/
+vi /usr/local/etc/nginx/nginx.conf
+# 编辑nginx.conf
+
+ server {
+ listen 8080;
+ server_name localhost;
+
+ location / {
+ root /Users/calvin/image_ui/dist/;
+ index index.html index.htm;
+ }
+ ......
+
+# 重新加载配置:
+sudo nginx -s reload
+
+# 部署应用后,重启:
+cd /usr/local/Cellar/nginx/1.19.6/bin
+
+# 快速停止
+sudo nginx -s stop
+
+# 启动
+sudo nginx
+```
+
+### 2. 后端jar部署
+#### 环境要求:
+- 系统JDK 1.8+,建议11
+
+### 3. 运行程序:
+运行编译后的jar:
+```bash
+# 运行程序
+nohup java -Dfile.encoding=utf-8 -jar xxxxx.jar > log.txt 2>&1 &
+```
+
+### 4. 打开浏览器
+- 输入地址: http://localhost:8089
+
+
+#### 1. 图片一键高清 (提升图片4倍分辨率)
+
+
+#### 2. 头像一键高清
+
+
+#### 3. 人脸一键修复
+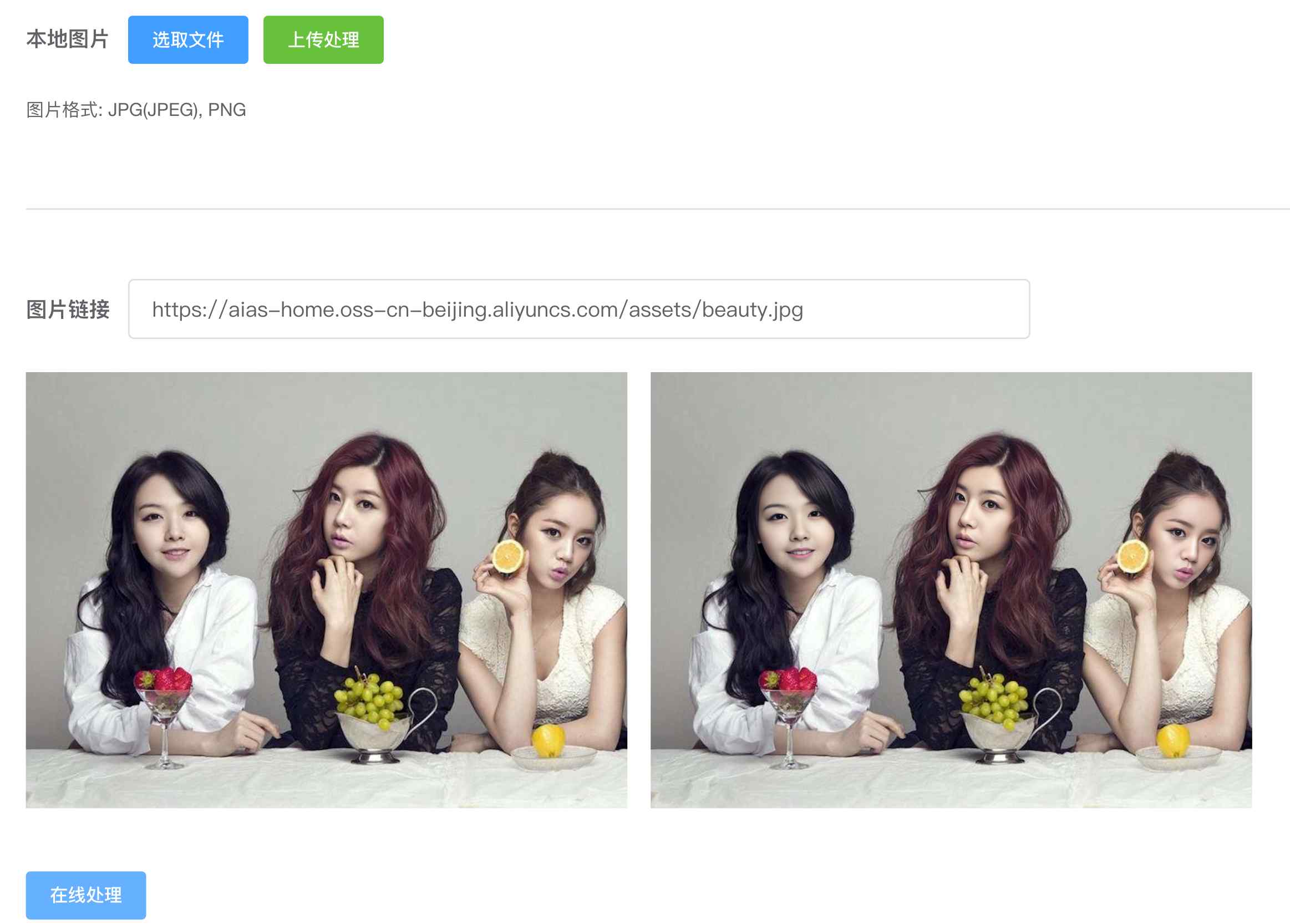
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/6_web_app/image_seg/README.md b/6_web_app/image_seg/README.md
new file mode 100644
index 00000000..ed8f9c2e
--- /dev/null
+++ b/6_web_app/image_seg/README.md
@@ -0,0 +1,124 @@
+### 目录:
+https://www.aias.top/
+
+### 下载模型,配置yml文件 image_backend\src\main\resources\application-xxx.yml
+- 链接: https://pan.baidu.com/s/1zm8tN94p2UgUS3HN0NTHRA?pwd=uzfy
+```bash
+model:
+ # 设备类型 cpu gpu
+ device: cpu
+ # 最大设置为 CPU 核心数 (Core Number)
+ poolSize: 4
+ # 遮罩层
+ mask: false
+ # 模型路径
+ modelPath: D:\\ai_projects\\products\\1_image_sdks\\seg_unet_sdk\\models\\
+ # 通用分割模型
+ bigModelName: u2net.onnx
+ middleModelName: silueta.onnx
+ smallModelName: u2netp.onnx
+ # 人体分割模型
+ humanModelName: human.onnx
+ # 动漫分割模型
+ animeModelName: anime.onnx
+ # 衣服分割模型
+ clothModelName: cloth.onnx
+```
+
+### 一键抠图
+
+一键抠图是一种图像处理技术,旨在自动将图像中的前景对象从背景中分离出来。它可以帮助用户快速、准确地实现抠图效果,无需手动绘制边界或进行复杂的图像编辑操作。
+一键抠图的原理通常基于计算机视觉和机器学习技术。它使用深度神经网络模型,通过训练大量的图像样本,学习如何识别和分离前景对象和背景。这些模型能够理解图像中的像素信息和上下文,并根据学习到的知识进行像素级别的分割。
+
+
+
+使用一键抠图可以带来许多实际用途,包括但不限于以下几个方面:
+1. 图像编辑:一键抠图可以用于图像编辑软件中,帮助用户轻松地将前景对象从一个图像中提取出来,并将其放置到另一个图像或背景中,实现合成效果。
+2. 广告设计:在广告设计中,一键抠图可以用于创建吸引人的广告素材。通过将产品或主题从原始照片中抠出,可以更好地突出产品或主题,并与其他元素进行组合。
+3. 虚拟背景:一键抠图可以用于视频会议或虚拟现实应用中,帮助用户实现虚拟背景效果。通过将用户的前景对象从实际背景中抠出,可以将其放置在虚拟环境中,提供更丰富的交互体验。
+4. 图像分析:一键抠图可以用于图像分析和计算机视觉任务中。通过将前景对象与背景分离,可以更好地理解和分析图像中的不同元素,如目标检测、图像分类、图像分割等。
+
+当前版本包含了下面功能:
+- 1. 通用一键抠图
+- 2. 人体一键抠图
+- 3. 动漫一键抠图
+
+
+
+### 1. 前端部署
+
+#### 1.1 直接运行:
+```bash
+npm run dev
+```
+
+#### 1.2 构建dist安装包:
+```bash
+npm run build:prod
+```
+
+#### 1.3 nginx部署运行(mac环境部署管理前端为例):
+```bash
+cd /usr/local/etc/nginx/
+vi /usr/local/etc/nginx/nginx.conf
+# 编辑nginx.conf
+
+ server {
+ listen 8080;
+ server_name localhost;
+
+ location / {
+ root /Users/calvin/image_ui/dist/;
+ index index.html index.htm;
+ }
+ ......
+
+# 重新加载配置:
+sudo nginx -s reload
+
+# 部署应用后,重启:
+cd /usr/local/Cellar/nginx/1.19.6/bin
+
+# 快速停止
+sudo nginx -s stop
+
+# 启动
+sudo nginx
+```
+
+### 2. 后端jar部署
+#### 环境要求:
+- 系统JDK 1.8+,建议11
+
+### 3. 运行程序:
+运行编译后的jar:
+```bash
+# 运行程序
+nohup java -Dfile.encoding=utf-8 -jar xxxxx.jar > log.txt 2>&1 &
+```
+
+### 4. 打开浏览器
+- 输入地址: http://localhost:8089
+
+
+#### 1. 通用一键抠图
+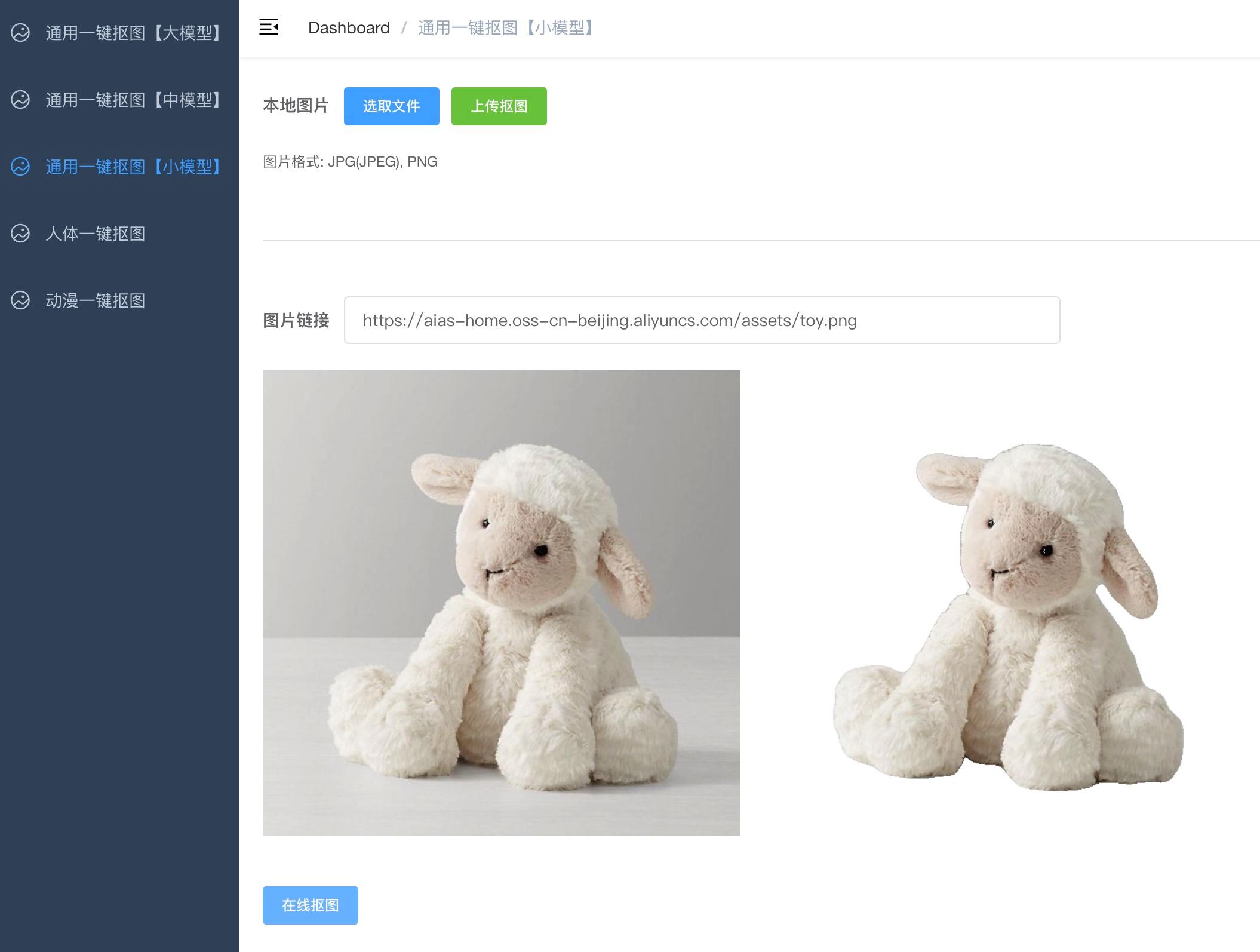
+
+#### 2. 人体一键抠图
+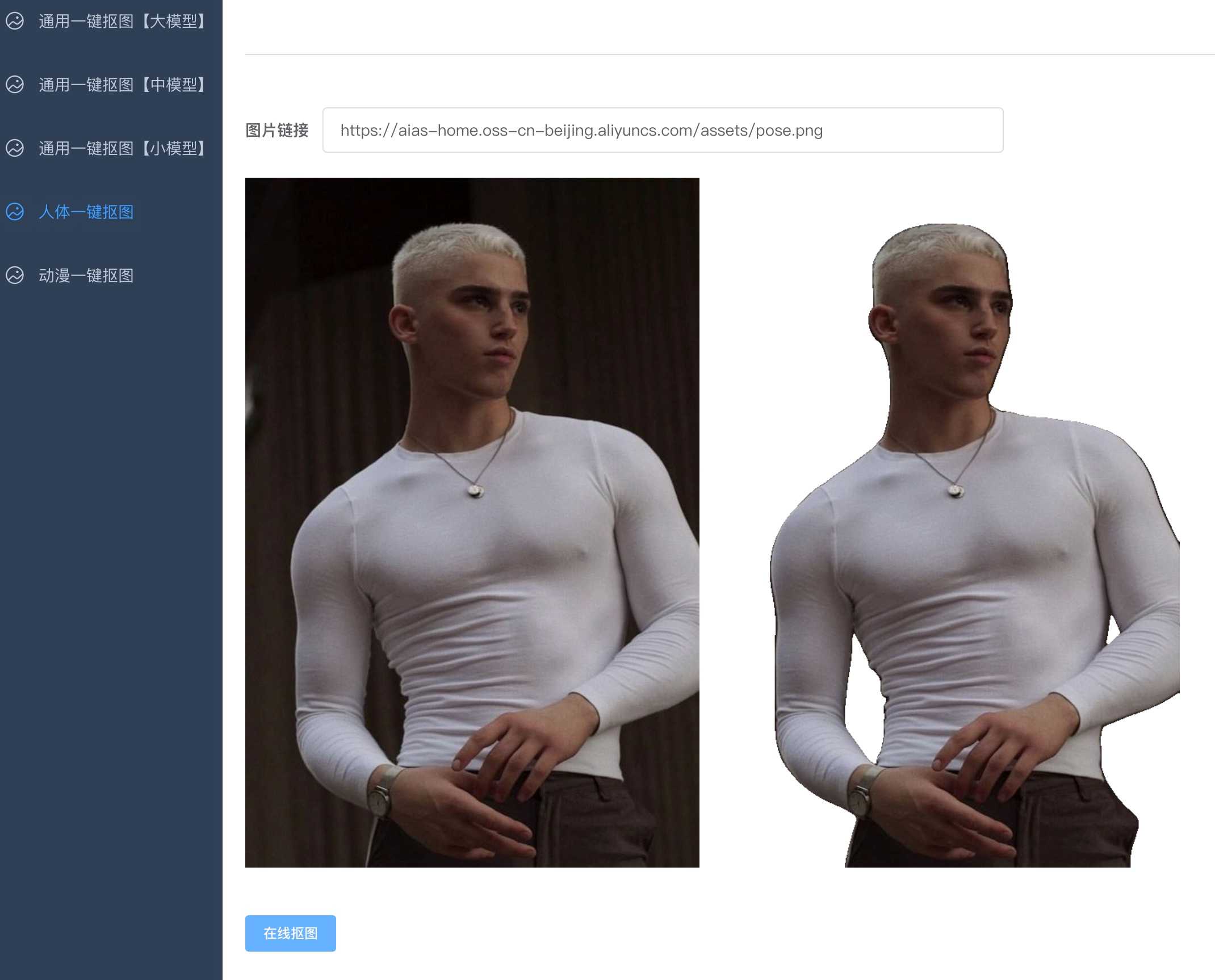
+
+#### 3. 动漫一键抠图
+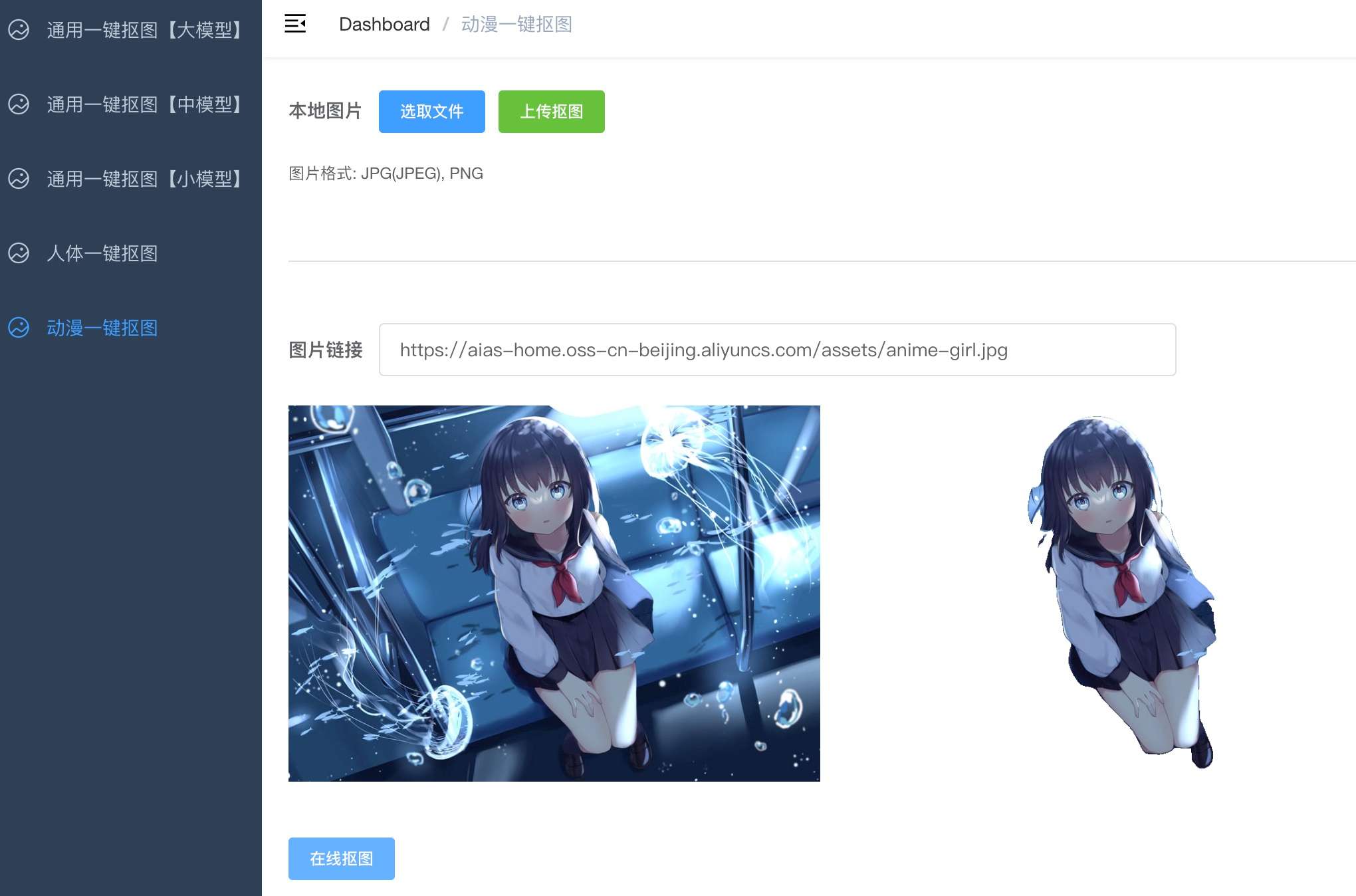
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/6_web_app/image_text_search/README.md b/6_web_app/image_text_search/README.md
new file mode 100644
index 00000000..840040cb
--- /dev/null
+++ b/6_web_app/image_text_search/README.md
@@ -0,0 +1,54 @@
+## 目录:
+http://aias.top/
+
+
+### 图像&文本的跨模态相似性比对检索【支持40种语言】
+- 包含两个项目,满足不同场景的需要
+
+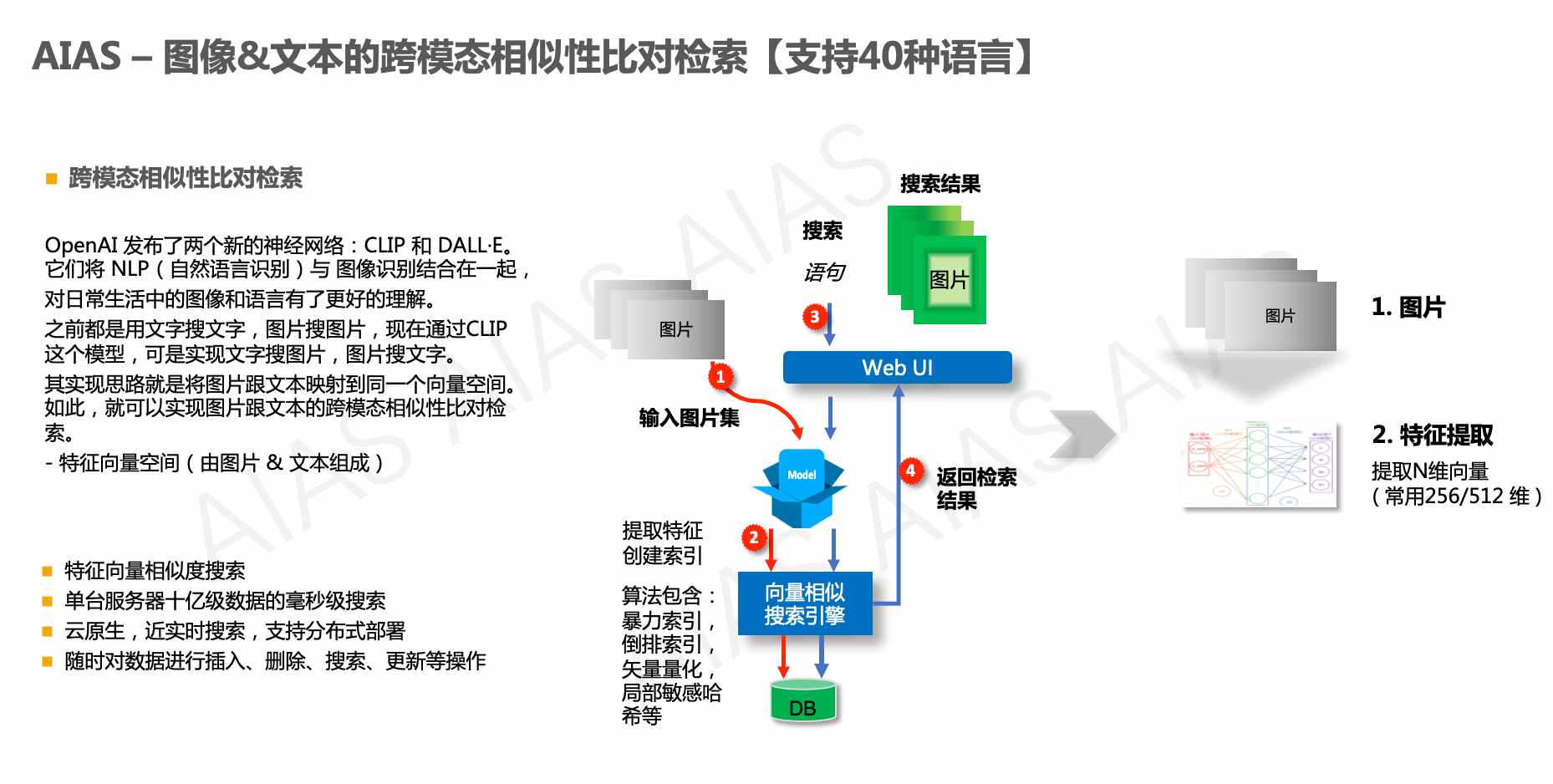
+
+### 1. 图像&文本的跨模态相似性比对检索【无向量引擎版】 - simple_image_text_search
+#### 1.1 主要特性
+- 支持100万以内的数据量
+- 随时对数据进行插入、删除、搜索、更新等操作
+
+#### 1.2 功能介绍
+- 以图搜图:上传图片搜索
+- 以文搜图:输入文本搜索
+- 数据管理:提供图像压缩包(zip格式)上传,图片特征提取
+
+
+### 2. 图像&文本的跨模态相似性比对检索【向量引擎版】 - image_text_search
+#### 2.1 主要特性
+- 底层使用特征向量相似度搜索
+- 单台服务器十亿级数据的毫秒级搜索
+- 近实时搜索,支持分布式部署
+- 随时对数据进行插入、删除、搜索、更新等操作
+
+#### 2.2 功能介绍
+- 以图搜图:上传图片搜索
+- 以文搜图:输入文本搜索
+- 数据管理:提供图像压缩包(zip格式)上传,图片特征提取
+
+
+### 3. 打开浏览器
+- 输入地址: http://localhost:8090
+
+#### 3.1 图片上传
+1). 点击上传按钮上传文件.
+[测试图片数据](https://pan.baidu.com/s/1QtF6syNUKS5qkf4OKAcuLA?pwd=wfd8)
+2). 点击特征提取按钮.
+等待图片特征提取,特征存入向量引擎。通过console可以看到进度信息。
+
+
+#### 3.2 跨模态搜索 - 文本搜图
+ 输入文字描述,点击查询,可以看到返回的图片清单,根据相似度排序。
+
+- 例子1,输入文本:车
+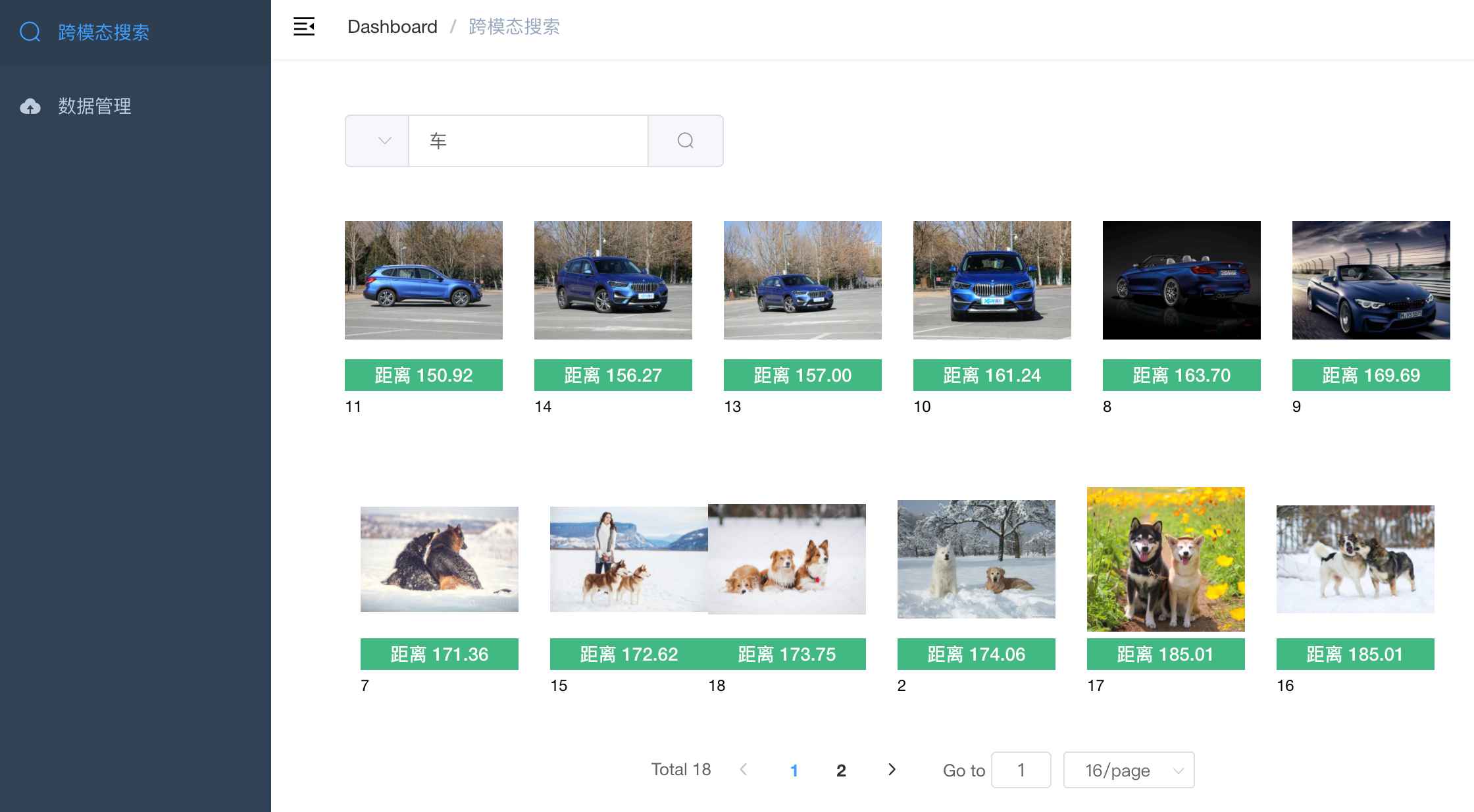
+
+- 例子2,输入文本:雪地上两只狗
+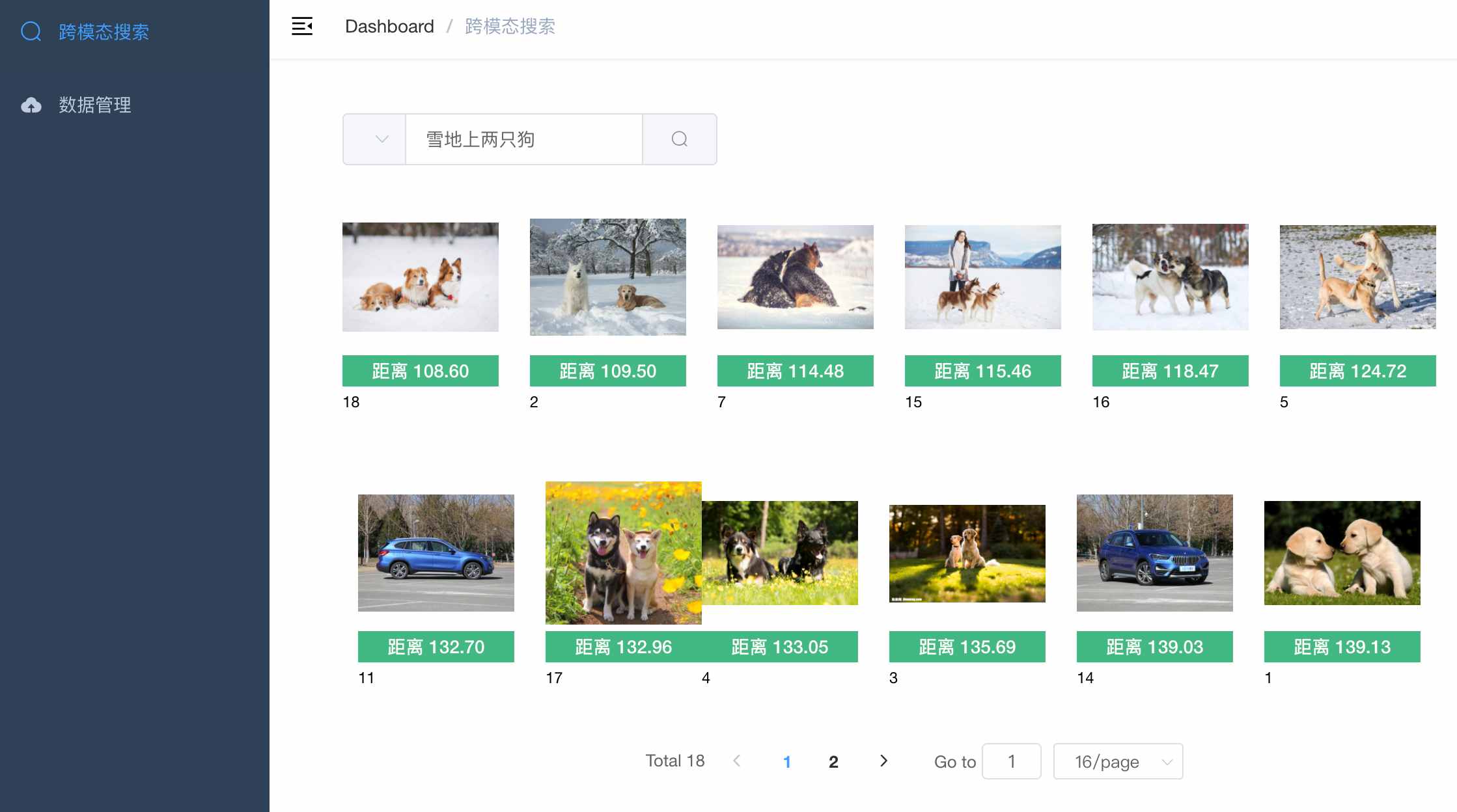
+
+#### 3.3 跨模态搜索 - 以图搜图
+
diff --git a/6_web_app/image_text_search/image_text_search/README.md b/6_web_app/image_text_search/image_text_search/README.md
new file mode 100644
index 00000000..61e4e56b
--- /dev/null
+++ b/6_web_app/image_text_search/image_text_search/README.md
@@ -0,0 +1,217 @@
+### 目录:
+http://aias.top/
+
+### 下载模型,更新 image_text_search的yaml配置文件
+- 链接: https://pan.baidu.com/s/1bc3MGsZjWz6TKFmSMUn5Ow?pwd=33b3
+```bash
+# Model URI
+model:
+ # Embedding Model
+ textModel: /Users/calvin/ai_projects/image_text_search/image_text_search/image_text_search/models/M-BERT-Base-ViT-B/M-BERT-Base-ViT-B.pt
+ imageModel: /Users/calvin/ai_projects/image_text_search/image_text_search/image_text_search/models/CLIP-ViT-B-32-IMAGE.pt
+```
+
+### 图像&文本的跨模态相似性比对检索【支持40种语言】
+本例子提供了通过文本搜图片的能力展示(模型本身当然也支持图片搜文字,或者混合搜索)。
+
+
+
+
+#### 主要特性
+- 底层使用特征向量相似度搜索
+- 单台服务器十亿级数据的毫秒级搜索
+- 近实时搜索,支持分布式部署
+- 随时对数据进行插入、删除、搜索、更新等操作
+
+#### 功能介绍
+- 以图搜图:上传图片搜索
+- 以文搜图:输入文本搜索
+- 数据管理:提供图像压缩包(zip格式)上传,图片特征提取
+
+
+#### 背景介绍
+OpenAI 发布了两个新的神经网络:CLIP 和 DALL·E。它们将 NLP(自然语言识别)与 图像识别结合在一起,对日常生活中的图像和语言有了更好的理解。
+之前都是用文字搜文字,图片搜图片,现在通过CLIP这个模型,可是实现文字搜图片,图片搜文字。其实现思路就是将图片跟文本映射到同一个向量空间。如此,就可以实现图片跟文本的跨模态相似性比对检索。
+- 特征向量空间(由图片 & 文本组成)
+
+
+#### CLIP - “另类”的图像识别
+目前,大多数模型学习从标注好的数据集的带标签的示例中识别图像,而 CLIP 则是学习从互联网获取的图像及其描述, 即通过一段描述而不是“猫”、“狗”这样的单词标签来认识图像。
+为了做到这一点,CLIP 学习将大量的对象与它们的名字和描述联系起来,并由此可以识别训练集以外的对象。
+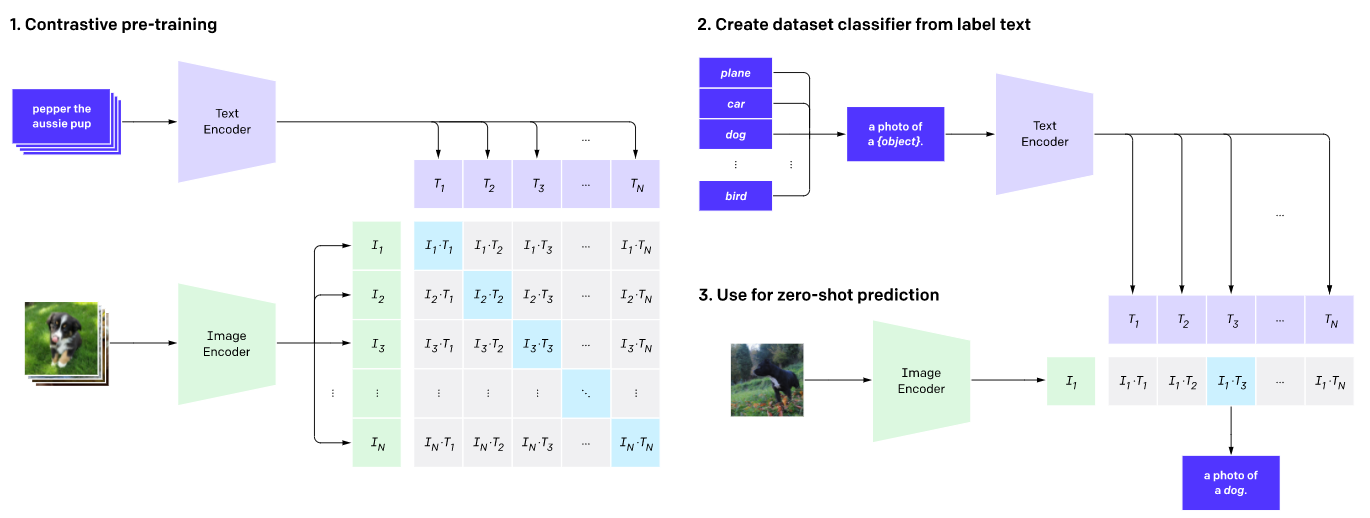
+如上图所示,CLIP网络工作流程: 预训练图编码器和文本编码器,以预测数据集中哪些图像与哪些文本配对。
+然后,将CLIP转换为zero-shot分类器。此外,将数据集的所有分类转换为诸如“一只狗的照片”之类的标签,并预测最佳配对的图像。
+
+CLIP模型地址:
+https://github.com/openai/CLIP/blob/main/README.md
+
+#### 支持的语言列表:
+
+
+### 1. 前端部署
+
+#### 1.1 直接运行:
+```bash
+npm run dev
+```
+
+#### 1.2 构建dist安装包:
+```bash
+npm run build:prod
+```
+
+#### 1.3 nginx部署运行(mac环境为例):
+```bash
+cd /usr/local/etc/nginx/
+vi /usr/local/etc/nginx/nginx.conf
+# 编辑nginx.conf
+
+ server {
+ listen 8080;
+ server_name localhost;
+
+ location / {
+ root /Users/calvin/Documents/image_text_search/dist/;
+ index index.html index.htm;
+ }
+ ......
+
+# 重新加载配置:
+sudo nginx -s reload
+
+# 部署应用后,重启:
+cd /usr/local/Cellar/nginx/1.19.6/bin
+
+# 快速停止
+sudo nginx -s stop
+
+# 启动
+sudo nginx
+```
+
+### 2. 后端jar部署
+#### 2.1 环境要求:
+- 系统JDK 1.8+
+
+- application.yml
+1). 根据需要编辑图片上传根路径rootPath
+```bash
+# 文件存储路径
+file:
+ mac:
+ path: ~/file/
+ # folder for unzip files
+ rootPath: ~/file/data_root/
+ linux:
+ path: /home/aias/file/
+ rootPath: /home/aias/file/data_root/
+ windows:
+ path: file:/D:/aias/file/
+ rootPath: file:/D:/aias/file/data_root/
+ ...
+```
+
+2). 根据需要编辑图片baseurl
+```bash
+image:
+ #baseurl是图片的地址前缀
+ baseurl: http://127.0.0.1:8089/files/
+```
+
+#### 2.2 运行程序:
+```bash
+# 运行程序
+
+java -jar image-text-search-0.1.0.jar
+
+```
+
+### 3. 后端向量引擎部署
+
+#### 3.1 环境要求:
+- 需要安装docker运行环境,Mac环境可以使用Docker Desktop
+
+#### 3.2 拉取Milvus向量引擎镜像(用于计算特征值向量相似度)
+下载 milvus-standalone-docker-compose.yml 配置文件并保存为 docker-compose.yml
+
+[单机版安装文档](https://milvus.io/docs/install_standalone-docker.md)
+[引擎配置文档](https://milvus.io/docs/configure-docker.md)
+[milvus-sdk-java](https://github.com/milvus-io/milvus-sdk-java)
+
+```bash
+# 例子:v2.2.11,请根据官方文档,选择合适的版本
+wget https://github.com/milvus-io/milvus/releases/download/v2.2.11/milvus-standalone-docker-compose.yml -O docker-compose.yml
+```
+
+#### 3.3 启动 Docker 容器
+```bash
+sudo docker-compose up -d
+```
+
+#### 3.5 编辑向量引擎连接配置信息
+- application.yml
+- 根据需要编辑向量引擎连接ip地址127.0.0.1为容器所在的主机ip
+```bash
+################## 向量引擎 ################
+search:
+ host: 127.0.0.1
+ port: 19530
+```
+
+### 4. 打开浏览器
+- 输入地址: http://localhost:8090
+
+#### 4.1 图片上传
+1). 点击上传按钮上传文件.
+[测试图片数据](https://pan.baidu.com/s/1QtF6syNUKS5qkf4OKAcuLA?pwd=wfd8)
+2). 点击特征提取按钮.
+等待图片特征提取,特征存入向量引擎。通过console可以看到进度信息。
+
+
+#### 4.2 跨模态搜索 - 文本搜图
+ 输入文字描述,点击查询,可以看到返回的图片清单,根据相似度排序。
+
+- 例子1,输入文本:车
+
+
+- 例子2,输入文本:雪地上两只狗
+
+
+#### 4.3 跨模态搜索 - 以图搜图
+
+
+### 5. 帮助信息
+- swagger接口文档:
+http://localhost:8089/swagger-ui.html
+
+
+- 初始化向量引擎(清空数据):
+
+```bash
+top.aias.tools.MilvusInit.java
+ ...
+```
+
+- Milvus向量引擎参考链接
+[Milvus向量引擎官网](https://milvus.io/cn/docs/overview.md)
+[Milvus向量引擎Github](https://github.com/milvus-io)
+
+### 官网:
+[官网链接](http://www.aias.top/)
+
+### Git地址:
+[Github链接](https://github.com/mymagicpower/AIAS)
+[Gitee链接](https://gitee.com/mymagicpower/AIAS)
+
+
+
+#### 帮助文档:
+- http://aias.top/guides.html
+- 1.性能优化常见问题:
+- http://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- http://aias.top/AIAS/guides/windows.html
diff --git a/6_web_app/image_text_search/simple_image_text_search/README.md b/6_web_app/image_text_search/simple_image_text_search/README.md
new file mode 100644
index 00000000..1a6c0333
--- /dev/null
+++ b/6_web_app/image_text_search/simple_image_text_search/README.md
@@ -0,0 +1,156 @@
+### 目录:
+http://aias.top/
+
+### 下载模型,更新 image_text_search的yaml配置文件
+- 链接: https://pan.baidu.com/s/1bc3MGsZjWz6TKFmSMUn5Ow?pwd=33b3
+```bash
+# Model URI
+model:
+ # Embedding Model
+ textModel: /Users/calvin/ai_projects/image_text_search/image_text_search/image_text_search/models/M-BERT-Base-ViT-B/M-BERT-Base-ViT-B.pt
+ imageModel: /Users/calvin/ai_projects/image_text_search/image_text_search/image_text_search/models/CLIP-ViT-B-32-IMAGE.pt
+```
+
+### 图像&文本的跨模态相似性比对检索【支持40种语言】
+#### 主要特性
+- 支持100万以内的数据量
+- 随时对数据进行插入、删除、搜索、更新等操作
+
+#### 功能介绍
+- 以图搜图:上传图片搜索
+- 以文搜图:输入文本搜索
+- 数据管理:提供图像压缩包(zip格式)上传,图片特征提取
+
+
+#### 背景介绍
+OpenAI 发布了两个新的神经网络:CLIP 和 DALL·E。它们将 NLP(自然语言识别)与 图像识别结合在一起,对日常生活中的图像和语言有了更好的理解。
+之前都是用文字搜文字,图片搜图片,现在通过CLIP这个模型,可是实现文字搜图片,图片搜文字。其实现思路就是将图片跟文本映射到同一个向量空间。如此,就可以实现图片跟文本的跨模态相似性比对检索。
+- 特征向量空间(由图片 & 文本组成)
+
+
+#### CLIP - “另类”的图像识别
+目前,大多数模型学习从标注好的数据集的带标签的示例中识别图像,而 CLIP 则是学习从互联网获取的图像及其描述, 即通过一段描述而不是“猫”、“狗”这样的单词标签来认识图像。
+为了做到这一点,CLIP 学习将大量的对象与它们的名字和描述联系起来,并由此可以识别训练集以外的对象。
+
+如上图所示,CLIP网络工作流程: 预训练图编码器和文本编码器,以预测数据集中哪些图像与哪些文本配对。
+然后,将CLIP转换为zero-shot分类器。此外,将数据集的所有分类转换为诸如“一只狗的照片”之类的标签,并预测最佳配对的图像。
+
+#### 支持的语言列表:
+
+
+### 1. 前端部署
+
+#### 1.1 直接运行:
+```bash
+npm run dev
+```
+
+#### 1.2 构建dist安装包:
+```bash
+npm run build:prod
+```
+
+#### 1.3 nginx部署运行(mac环境为例):
+```bash
+cd /usr/local/etc/nginx/
+vi /usr/local/etc/nginx/nginx.conf
+# 编辑nginx.conf
+
+ server {
+ listen 8080;
+ server_name localhost;
+
+ location / {
+ root /Users/calvin/Documents/image_text_search/dist/;
+ index index.html index.htm;
+ }
+ ......
+
+# 重新加载配置:
+sudo nginx -s reload
+
+# 部署应用后,重启:
+cd /usr/local/Cellar/nginx/1.19.6/bin
+
+# 快速停止
+sudo nginx -s stop
+
+# 启动
+sudo nginx
+```
+
+### 2. 后端jar部署
+#### 2.1 环境要求:
+- 系统JDK 1.8+
+
+- application.yml
+1). 根据需要编辑图片上传根路径rootPath
+```bash
+# 文件存储路径
+file:
+ mac:
+ path: ~/file/
+ # folder for unzip files
+ rootPath: ~/file/data_root/
+ linux:
+ path: /home/aias/file/
+ rootPath: /home/aias/file/data_root/
+ windows:
+ path: file:/D:/aias/file/
+ rootPath: file:/D:/aias/file/data_root/
+ ...
+```
+
+2). 根据需要编辑图片baseurl
+```bash
+image:
+ #baseurl是图片的地址前缀
+ baseurl: http://127.0.0.1:8089/files/
+```
+
+#### 2.2 运行程序:
+```bash
+# 运行程序
+
+java -jar image-text-search-0.1.0.jar
+
+```
+
+### 3. 功能使用
+打开浏览器
+- 输入地址: http://localhost:8090
+
+#### 3.1 图片上传
+1). 点击上传按钮上传文件.
+[测试图片数据](https://pan.baidu.com/s/1QtF6syNUKS5qkf4OKAcuLA?pwd=wfd8)
+2). 点击特征提取按钮.
+等待图片特征提取,特征存入json文件。
+
+
+#### 3.2 跨模态搜索 - 文本搜图
+ 输入文字描述,点击查询,可以看到返回的图片清单,根据相似度排序。
+
+
+#### 3.3 跨模态搜索 - 以图搜图
+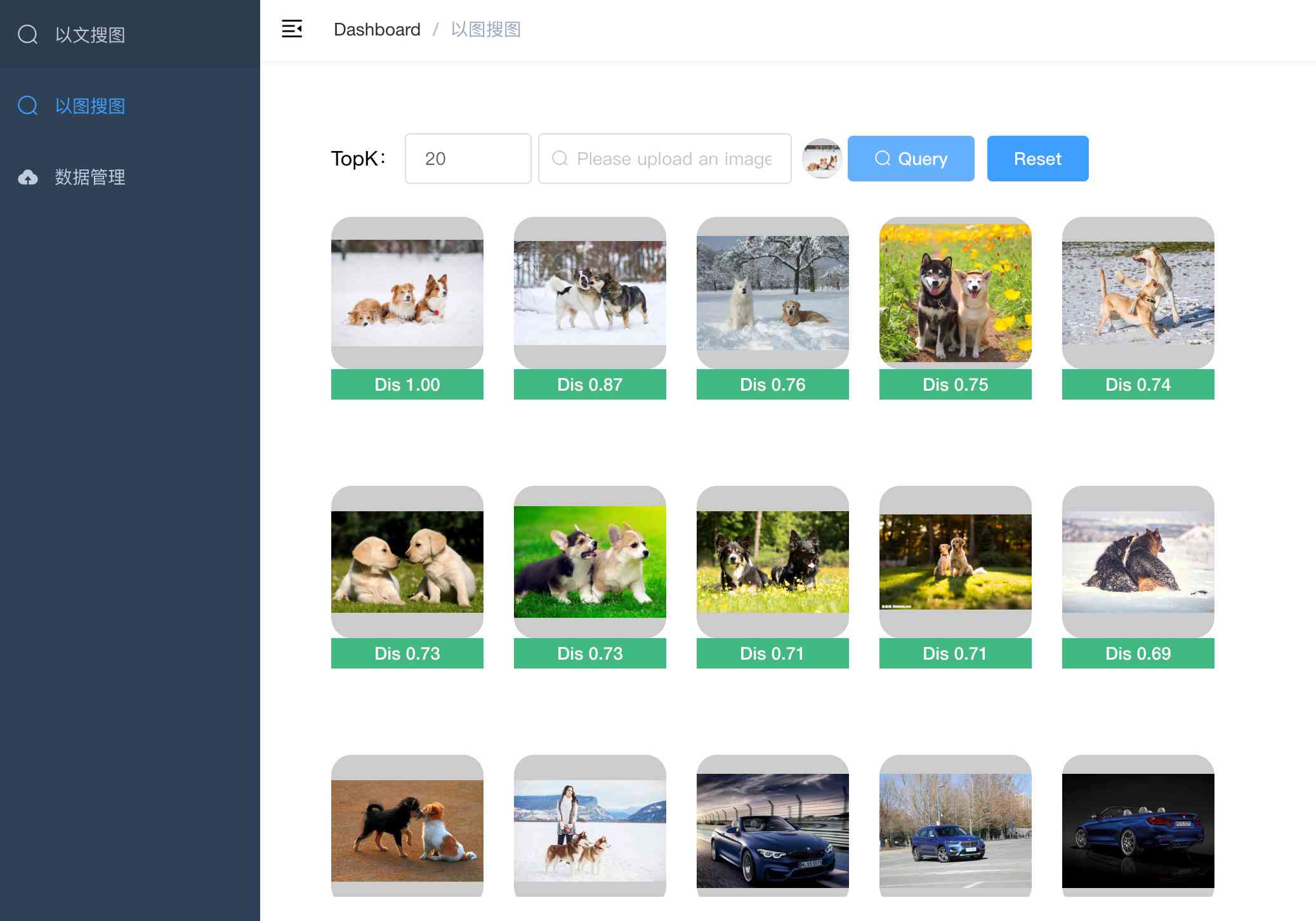
+
+### 4. 帮助信息
+- swagger接口文档:
+http://localhost:8089/swagger-ui.html
+
+
+
+### 官网:
+[官网链接](http://www.aias.top/)
+
+
+#### 帮助文档:
+- http://aias.top/guides.html
+- 1.性能优化常见问题:
+- http://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- http://aias.top/AIAS/guides/windows.html
diff --git a/6_web_app/text_search/README.md b/6_web_app/text_search/README.md
new file mode 100644
index 00000000..c7603230
--- /dev/null
+++ b/6_web_app/text_search/README.md
@@ -0,0 +1,48 @@
+## 目录:
+http://aias.top/
+
+
+### 文本向量搜索
+本例子提供了文本搜索,支持上传csv文件,使用句向量模型提取特征,用于后续检索。
+
+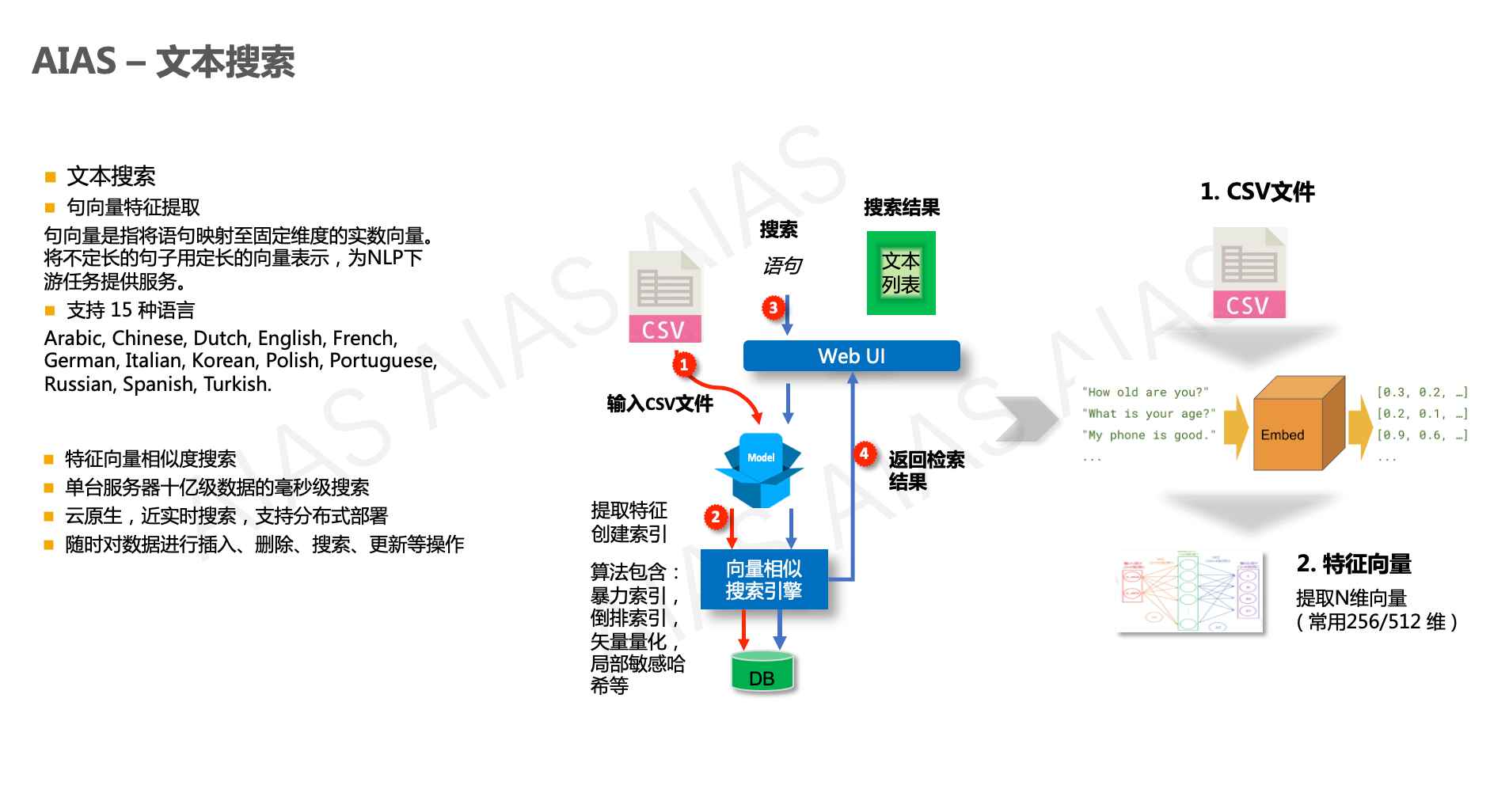
+
+#### 文本句向量搜索应用:
+- 语义搜索,通过句向量相似性,检索语料库中与query最匹配的文本
+- 文本聚类,文本转为定长向量,通过聚类模型可无监督聚集相似文本
+- 文本分类,表示成句向量,直接用简单分类器即训练文本分类器
+- RAG 用于大模型搜索增强生成
+
+### 1. 文本向量搜索【无向量引擎版】 - simple_text_search
+#### 1.1 主要特性
+- 支持100万以内的数据量
+- 随时对数据进行插入、删除、搜索、更新等操作
+
+
+### 2. 文本向量搜索【向量引擎版】 - text_search
+#### 2.1 主要特性
+- 底层使用特征向量相似度搜索
+- 单台服务器十亿级数据的毫秒级搜索
+- 近实时搜索,支持分布式部署
+- 随时对数据进行插入、删除、搜索、更新等操作
+
+## 3. 打开浏览器
+- 输入地址: http://localhost:8090
+
+- 上传CSV数据文件
+1). 点击上传按钮上传CSV文件.
+[测试数据](https://aias-home.oss-cn-beijing.aliyuncs.com/AIAS/text_search/example.csv)
+2). 点击特征提取按钮.
+等待CSV文件解析,特征提取,特征存入向量引擎。通过console可以看到进度信息。
+
+
+
+- 文本搜索
+ 输入文字,点击查询,可以看到返回的清单,根据相似度排序。
+
+
+
+## 4. 帮助信息
+- swagger接口文档:
+http://localhost:8089/swagger-ui.html
+
diff --git a/6_web_app/text_search/simple_text_search/README.md b/6_web_app/text_search/simple_text_search/README.md
new file mode 100644
index 00000000..128251f0
--- /dev/null
+++ b/6_web_app/text_search/simple_text_search/README.md
@@ -0,0 +1,154 @@
+## 目录:
+http://aias.top/
+
+### 下载模型,更新 text-search 的yaml配置文件
+- 链接: https://pan.baidu.com/s/1hI_aiTyj34mkrtGrI7Ij4A?pwd=g8fu
+```bash
+# Model URI
+model:
+ # 模型路径,注意路径最后要有分隔符
+ modelPath: /Users/calvin/products/4_apps/simple_text_search/text-search/models/m3e/
+ # 模型名字
+ modelName: traced_m3e_base_model.pt
+ # for chinese - ture, others - false
+ chinese: true
+ # 设置为 CPU 核心数 (Core Number)
+ poolSize: 4
+```
+
+#### 主要特性
+- 支持100万以内的数据量
+- 随时对数据进行插入、删除、搜索、更新等操作
+
+
+### 句向量模型【支持15种语言】
+
+句向量是指将语句映射至固定维度的实数向量。将不定长的句子用定长的向量表示,为NLP下游任务提供服务。
+支持 15 种语言:
+Arabic, Chinese, Dutch, English, French, German, Italian, Korean, Polish, Portuguese, Russian, Spanish, Turkish.
+
+- 句向量
+ 
+
+
+句向量应用:
+
+- 语义搜索,通过句向量相似性,检索语料库中与query最匹配的文本
+- 文本聚类,文本转为定长向量,通过聚类模型可无监督聚集相似文本
+- 文本分类,表示成句向量,直接用简单分类器即训练文本分类器
+
+
+
+### 1. 前端部署
+
+#### 1.1 安装运行:
+```bash
+# 安装依赖包
+npm install
+# 运行
+npm run dev
+```
+
+#### 1.2 构建dist安装包:
+```bash
+npm run build:prod
+```
+
+#### 1.3 nginx部署运行(mac环境为例):
+```bash
+cd /usr/local/etc/nginx/
+vi /usr/local/etc/nginx/nginx.conf
+# 编辑nginx.conf
+
+ server {
+ listen 8080;
+ server_name localhost;
+
+ location / {
+ root /Users/calvin/Documents/text_search/dist/;
+ index index.html index.htm;
+ }
+ ......
+
+# 重新加载配置:
+sudo nginx -s reload
+
+# 部署应用后,重启:
+cd /usr/local/Cellar/nginx/1.19.6/bin
+
+# 快速停止
+sudo nginx -s stop
+
+# 启动
+sudo nginx
+```
+
+## 2. 后端jar部署
+#### 2.1 环境要求:
+- 系统JDK 1.8+
+
+- application.yml
+```bash
+# 文件存储路径
+file:
+ mac:
+ path: ~/file/
+ linux:
+ path: /home/aias/file/
+ windows:
+ path: file:/D:/aias/file/
+ # 文件大小 /M
+ maxSize: 3000
+ ...
+```
+
+#### 2.2 运行程序:
+```bash
+# 运行程序
+
+java -jar text-search-0.1.0.jar
+
+```
+
+
+## 3. 打开浏览器
+- 输入地址: http://localhost:8090
+
+- 上传CSV数据文件
+1). 点击上传按钮上传CSV文件.
+[测试数据](https://aias-home.oss-cn-beijing.aliyuncs.com/AIAS/text_search/example.csv)
+2). 点击特征提取按钮.
+等待CSV文件解析,特征提取,特征存入向量引擎。通过console可以看到进度信息。
+
+
+
+- 文本搜索
+ 输入文字,点击查询,可以看到返回的清单,根据相似度排序。
+
+
+
+## 4s. 帮助信息
+- swagger接口文档:
+http://localhost:8089/swagger-ui.html
+
+
+
+
+### 官网:
+[官网链接](http://www.aias.top/)
+
+### Git地址:
+[Github链接](https://github.com/mymagicpower/AIAS)
+[Gitee链接](https://gitee.com/mymagicpower/AIAS)
+
+
+#### 帮助文档:
+- http://aias.top/guides.html
+- 1.性能优化常见问题:
+- http://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- http://aias.top/AIAS/guides/windows.html
diff --git a/6_web_app/text_search/text_search/README.md b/6_web_app/text_search/text_search/README.md
new file mode 100644
index 00000000..cb2d8bd6
--- /dev/null
+++ b/6_web_app/text_search/text_search/README.md
@@ -0,0 +1,194 @@
+## 目录:
+http://aias.top/
+
+### 下载模型,更新 text-search 的yaml配置文件
+- 链接: https://pan.baidu.com/s/1hI_aiTyj34mkrtGrI7Ij4A?pwd=g8fu
+```bash
+# Model URI
+model:
+ # 模型路径,注意路径最后要有分隔符
+ modelPath: /Users/calvin/products/4_apps/simple_text_search/text-search/models/m3e/
+ # 模型名字
+ modelName: traced_m3e_base_model.pt
+ # for chinese - ture, others - false
+ chinese: true
+ # 设置为 CPU 核心数 (Core Number)
+ poolSize: 4
+```
+
+
+### 文本向量搜索
+本例子提供了文本搜索,支持上传csv文件,使用句向量模型提取特征,并基于milvus向量引擎进行后续检索。
+
+
+
+
+#### 主要特性
+- 底层使用特征向量相似度搜索
+- 单台服务器十亿级数据的毫秒级搜索
+- 近实时搜索,支持分布式部署
+- 随时对数据进行插入、删除、搜索、更新等操作
+
+
+
+### 句向量模型【支持15种语言】
+
+句向量是指将语句映射至固定维度的实数向量。将不定长的句子用定长的向量表示,为NLP下游任务提供服务。
+支持 15 种语言:
+Arabic, Chinese, Dutch, English, French, German, Italian, Korean, Polish, Portuguese, Russian, Spanish, Turkish.
+
+- 句向量
+ 
+
+
+句向量应用:
+
+- 语义搜索,通过句向量相似性,检索语料库中与query最匹配的文本
+- 文本聚类,文本转为定长向量,通过聚类模型可无监督聚集相似文本
+- 文本分类,表示成句向量,直接用简单分类器即训练文本分类器
+
+
+
+### 1. 前端部署
+
+#### 1.1 安装运行:
+```bash
+# 安装依赖包
+npm install
+# 运行
+npm run dev
+```
+
+#### 1.2 构建dist安装包:
+```bash
+npm run build:prod
+```
+
+#### 1.3 nginx部署运行(mac环境为例):
+```bash
+cd /usr/local/etc/nginx/
+vi /usr/local/etc/nginx/nginx.conf
+# 编辑nginx.conf
+
+ server {
+ listen 8080;
+ server_name localhost;
+
+ location / {
+ root /Users/calvin/Documents/text_search/dist/;
+ index index.html index.htm;
+ }
+ ......
+
+# 重新加载配置:
+sudo nginx -s reload
+
+# 部署应用后,重启:
+cd /usr/local/Cellar/nginx/1.19.6/bin
+
+# 快速停止
+sudo nginx -s stop
+
+# 启动
+sudo nginx
+```
+
+## 2. 后端jar部署
+#### 2.1 环境要求:
+- 系统JDK 1.8+
+
+- application.yml
+```bash
+# 文件存储路径
+file:
+ mac:
+ path: ~/file/
+ linux:
+ path: /home/aias/file/
+ windows:
+ path: file:/D:/aias/file/
+ # 文件大小 /M
+ maxSize: 3000
+ ...
+```
+
+#### 2.2 运行程序:
+```bash
+# 运行程序
+
+java -jar text-search-0.1.0.jar
+
+```
+
+## 3. 后端向量引擎部署(Milvus 2.0)
+#### 3.1 环境要求:
+- 需要安装docker运行环境,Mac环境可以使用Docker Desktop
+
+#### 3.2 拉取Milvus向量引擎镜像(用于计算特征值向量相似度)
+下载 milvus-standalone-docker-compose.yml 配置文件并保存为 docker-compose.yml
+[单机版安装文档](https://milvus.io/docs/v2.0.0/install_standalone-docker.md)
+```bash
+wget https://github.com/milvus-io/milvus/releases/download/v2.0.0/milvus-standalone-docker-compose.yml -O docker-compose.yml
+```
+
+#### 3.3 启动 Docker 容器
+```bash
+sudo docker-compose up -d
+```
+
+#### 3.5 编辑向量引擎连接配置信息
+- application.yml
+- 根据需要编辑向量引擎连接ip地址127.0.0.1为容器所在的主机ip
+```bash
+################## 向量引擎 ################
+search:
+ host: 127.0.0.1
+ port: 19530
+```
+
+## 4. 打开浏览器
+- 输入地址: http://localhost:8090
+
+- 上传CSV数据文件
+1). 点击上传按钮上传CSV文件.
+[测试数据](https://aias-home.oss-cn-beijing.aliyuncs.com/AIAS/text_search/example.csv)
+2). 点击特征提取按钮.
+等待CSV文件解析,特征提取,特征存入向量引擎。通过console可以看到进度信息。
+
+
+
+- 文本搜索
+ 输入文字,点击查询,可以看到返回的清单,根据相似度排序。
+
+
+
+## 5. 帮助信息
+- swagger接口文档:
+http://localhost:8089/swagger-ui.html
+
+
+- 初始化向量引擎(清空数据):
+me.aias.tools.MilvusInit.java
+
+- Milvus向量引擎参考链接
+[Milvus向量引擎官网](https://milvus.io/cn/docs/overview.md)
+[Milvus向量引擎Github](https://github.com/milvus-io)
+
+### 官网:
+[官网链接](http://www.aias.top/)
+
+### Git地址:
+[Github链接](https://github.com/mymagicpower/AIAS)
+[Gitee链接](https://gitee.com/mymagicpower/AIAS)
+
+
+#### 帮助文档:
+- http://aias.top/guides.html
+- 1.性能优化常见问题:
+- http://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- http://aias.top/AIAS/guides/windows.html
diff --git a/6_web_app/text_translation/README.md b/6_web_app/text_translation/README.md
new file mode 100644
index 00000000..59e148a7
--- /dev/null
+++ b/6_web_app/text_translation/README.md
@@ -0,0 +1,342 @@
+## 目录:
+http://aias.top/
+
+### 下载模型
+- 链接: https://pan.baidu.com/s/1KRrr0zQE601fqHZhf4oG4Q?pwd=e4lq
+
+### 202种语言互相翻译 Web 应用
+
+
+
+
+#### 主要特性
+- 支持202种语言互相翻译。
+- 支持 CPU / GPU
+
+
+
+### 1. 前端部署
+
+#### 1.1 安装运行:
+```bash
+# 安装依赖包
+npm install
+# 运行
+npm run dev
+```
+
+#### 1.2 构建dist安装包:
+```bash
+npm run build:prod
+```
+
+#### 1.3 nginx部署运行(mac环境为例):
+```bash
+cd /usr/local/etc/nginx/
+vi /usr/local/etc/nginx/nginx.conf
+# 编辑nginx.conf
+
+ server {
+ listen 8080;
+ server_name localhost;
+
+ location / {
+ root /Users/calvin/Documents/text_translation/dist/;
+ index index.html index.htm;
+ }
+ ......
+
+# 重新加载配置:
+sudo nginx -s reload
+
+# 部署应用后,重启:
+cd /usr/local/Cellar/nginx/1.19.6/bin
+
+# 快速停止
+sudo nginx -s stop
+
+# 启动
+sudo nginx
+```
+
+## 2. 后端jar部署
+#### 2.1 环境要求:
+- 系统JDK 1.8+
+- 根据实际路径更新配置文件 application.yml
+
+```bash
+# Model URI
+model:
+ # 模型路径,注意路径最后要有分隔符
+ # /Users/calvin/products/4_apps/trans_nllb_sdk/text-translation/models/
+ modelPath: D:\\ai_projects\\products\\2_nlp_sdks\\trans_nllb_sdk\\models\\
+ # 模型名字
+ modelName: traced_translation.pt
+ # 设置为 CPU 核心数 (Core Number)
+ poolSize: 4
+
+# 参数配置
+config:
+ # 输出文字最大长度
+ maxLength: 128
+ # 是否启用显卡 GPU, true, false
+ gpu: false
+ ...
+```
+
+#### 2.2 运行程序:
+```bash
+# 运行程序
+
+java -jar text-translation-0.1.0.jar
+
+```
+
+
+## 4. 打开浏览器
+- 输入地址: http://localhost:8090
+
+### 文本翻译
+- 选择源语言
+- 目标语言
+- 输入文字
+- 点击查询
+
+然后可以看到返回的翻译结果。
+
+
+
+## 5. 帮助信息
+- swagger接口文档:
+- http://localhost:8089/swagger-ui.html
+
+
+
+
+
+### 官网:
+[官网链接](http://www.aias.top/)
+
+
+
+#### 帮助文档:
+- http://aias.top/guides.html
+- 1.性能优化常见问题:
+- http://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- http://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- http://aias.top/AIAS/guides/windows.html
+
+
+## 语言编码
+### 详情请参考excel文档: 语言编码.xlsx
+
+Language | Code
+---|---
+Acehnese (Arabic script) | ace_Arab
+Acehnese (Latin script) | ace_Latn
+Mesopotamian Arabic | acm_Arab
+Ta’izzi-Adeni Arabic | acq_Arab
+Tunisian Arabic | aeb_Arab
+Afrikaans | afr_Latn
+South Levantine Arabic | ajp_Arab
+Akan | aka_Latn
+Amharic | amh_Ethi
+North Levantine Arabic | apc_Arab
+Modern Standard Arabic | arb_Arab
+Modern Standard Arabic (Romanized) | arb_Latn
+Najdi Arabic | ars_Arab
+Moroccan Arabic | ary_Arab
+Egyptian Arabic | arz_Arab
+Assamese | asm_Beng
+Asturian | ast_Latn
+Awadhi | awa_Deva
+Central Aymara | ayr_Latn
+South Azerbaijani | azb_Arab
+North Azerbaijani | azj_Latn
+Bashkir | bak_Cyrl
+Bambara | bam_Latn
+Balinese | ban_Latn
+Belarusian | bel_Cyrl
+Bemba | bem_Latn
+Bengali | ben_Beng
+Bhojpuri | bho_Deva
+Banjar (Arabic script) | bjn_Arab
+Banjar (Latin script) | bjn_Latn
+Standard Tibetan | bod_Tibt
+Bosnian | bos_Latn
+Buginese | bug_Latn
+Bulgarian | bul_Cyrl
+Catalan | cat_Latn
+Cebuano | ceb_Latn
+Czech | ces_Latn
+Chokwe | cjk_Latn
+Central Kurdish | ckb_Arab
+Crimean Tatar | crh_Latn
+Welsh | cym_Latn
+Danish | dan_Latn
+German | deu_Latn
+Southwestern Dinka | dik_Latn
+Dyula | dyu_Latn
+Dzongkha | dzo_Tibt
+Greek | ell_Grek
+English | eng_Latn
+Esperanto | epo_Latn
+Estonian | est_Latn
+Basque | eus_Latn
+Ewe | ewe_Latn
+Faroese | fao_Latn
+Fijian | fij_Latn
+Finnish | fin_Latn
+Fon | fon_Latn
+French | fra_Latn
+Friulian | fur_Latn
+Nigerian Fulfulde | fuv_Latn
+Scottish Gaelic | gla_Latn
+Irish | gle_Latn
+Galician | glg_Latn
+Guarani | grn_Latn
+Gujarati | guj_Gujr
+Haitian Creole | hat_Latn
+Hausa | hau_Latn
+Hebrew | heb_Hebr
+Hindi | hin_Deva
+Chhattisgarhi | hne_Deva
+Croatian | hrv_Latn
+Hungarian | hun_Latn
+Armenian | hye_Armn
+Igbo | ibo_Latn
+Ilocano | ilo_Latn
+Indonesian | ind_Latn
+Icelandic | isl_Latn
+Italian | ita_Latn
+Javanese | jav_Latn
+Japanese | jpn_Jpan
+Kabyle | kab_Latn
+Jingpho | kac_Latn
+Kamba | kam_Latn
+Kannada | kan_Knda
+Kashmiri (Arabic script) | kas_Arab
+Kashmiri (Devanagari script) | kas_Deva
+Georgian | kat_Geor
+Central Kanuri (Arabic script) | knc_Arab
+Central Kanuri (Latin script) | knc_Latn
+Kazakh | kaz_Cyrl
+Kabiyè | kbp_Latn
+Kabuverdianu | kea_Latn
+Khmer | khm_Khmr
+Kikuyu | kik_Latn
+Kinyarwanda | kin_Latn
+Kyrgyz | kir_Cyrl
+Kimbundu | kmb_Latn
+Northern Kurdish | kmr_Latn
+Kikongo | kon_Latn
+Korean | kor_Hang
+Lao | lao_Laoo
+Ligurian | lij_Latn
+Limburgish | lim_Latn
+Lingala | lin_Latn
+Lithuanian | lit_Latn
+Lombard | lmo_Latn
+Latgalian | ltg_Latn
+Luxembourgish | ltz_Latn
+Luba-Kasai | lua_Latn
+Ganda | lug_Latn
+Luo | luo_Latn
+Mizo | lus_Latn
+Standard Latvian | lvs_Latn
+Magahi | mag_Deva
+Maithili | mai_Deva
+Malayalam | mal_Mlym
+Marathi | mar_Deva
+Minangkabau (Arabic script) | min_Arab
+Minangkabau (Latin script) | min_Latn
+Macedonian | mkd_Cyrl
+Plateau Malagasy | plt_Latn
+Maltese | mlt_Latn
+Meitei (Bengali script) | mni_Beng
+Halh Mongolian | khk_Cyrl
+Mossi | mos_Latn
+Maori | mri_Latn
+Burmese | mya_Mymr
+Dutch | nld_Latn
+Norwegian Nynorsk | nno_Latn
+Norwegian Bokmål | nob_Latn
+Nepali | npi_Deva
+Northern Sotho | nso_Latn
+Nuer | nus_Latn
+Nyanja | nya_Latn
+Occitan | oci_Latn
+West Central Oromo | gaz_Latn
+Odia | ory_Orya
+Pangasinan | pag_Latn
+Eastern Panjabi | pan_Guru
+Papiamento | pap_Latn
+Western Persian | pes_Arab
+Polish | pol_Latn
+Portuguese | por_Latn
+Dari | prs_Arab
+Southern Pashto | pbt_Arab
+Ayacucho Quechua | quy_Latn
+Romanian | ron_Latn
+Rundi | run_Latn
+Russian | rus_Cyrl
+Sango | sag_Latn
+Sanskrit | san_Deva
+Santali | sat_Olck
+Sicilian | scn_Latn
+Shan | shn_Mymr
+Sinhala | sin_Sinh
+Slovak | slk_Latn
+Slovenian | slv_Latn
+Samoan | smo_Latn
+Shona | sna_Latn
+Sindhi | snd_Arab
+Somali | som_Latn
+Southern Sotho | sot_Latn
+Spanish | spa_Latn
+Tosk Albanian | als_Latn
+Sardinian | srd_Latn
+Serbian | srp_Cyrl
+Swati | ssw_Latn
+Sundanese | sun_Latn
+Swedish | swe_Latn
+Swahili | swh_Latn
+Silesian | szl_Latn
+Tamil | tam_Taml
+Tatar | tat_Cyrl
+Telugu | tel_Telu
+Tajik | tgk_Cyrl
+Tagalog | tgl_Latn
+Thai | tha_Thai
+Tigrinya | tir_Ethi
+Tamasheq (Latin script) | taq_Latn
+Tamasheq (Tifinagh script) | taq_Tfng
+Tok Pisin | tpi_Latn
+Tswana | tsn_Latn
+Tsonga | tso_Latn
+Turkmen | tuk_Latn
+Tumbuka | tum_Latn
+Turkish | tur_Latn
+Twi | twi_Latn
+Central Atlas Tamazight | tzm_Tfng
+Uyghur | uig_Arab
+Ukrainian | ukr_Cyrl
+Umbundu | umb_Latn
+Urdu | urd_Arab
+Northern Uzbek | uzn_Latn
+Venetian | vec_Latn
+Vietnamese | vie_Latn
+Waray | war_Latn
+Wolof | wol_Latn
+Xhosa | xho_Latn
+Eastern Yiddish | ydd_Hebr
+Yoruba | yor_Latn
+Yue Chinese | yue_Hant
+Chinese (Simplified) | zho_Hans
+Chinese (Traditional) | zho_Hant
+Standard Malay | zsm_Latn
+Zulu | zul_Latn
\ No newline at end of file
diff --git a/6_web_app/training/README_EN.md b/6_web_app/training/README_EN.md
deleted file mode 100644
index 48105c06..00000000
--- a/6_web_app/training/README_EN.md
+++ /dev/null
@@ -1,123 +0,0 @@
-### This project is only for study and research purposes. For project development, it is recommended to use Python training frameworks such as PaddlePaddle, PyTorch, TensorFlow, etc.
-
-### Download the model and place it in the models directory
-- Link: https://github.com/mymagicpower/AIAS/releases/download/apps/resnet50_v2.zip
-
-### AI Training Platform
-
-The AI training platform provides classification model training capabilities and provides interfaces to upper-layer applications in the form of REST APIs. The current version includes the following functions:
-
-- Classification model training (resnet50 model pre-trained with Imagenet dataset)
-- Model training visualization
-- Image classification inference
-- Image feature extraction (512-dimensional feature)
-- Image 1:1 comparison
-
-## Front-end deployment
-
-### nginx deployment operation:
-```bash
-cd /usr/local/etc/nginx/
-vi /usr/local/etc/nginx/nginx.conf
-#Edit nginx.conf
-
-server {
-listen 8080;
-server_name localhost;
-
-location / {
-root /Users/calvin/platform/dist/;
-index index.html index.htm;
- }
-......
-
-#Reload configuration:
-sudo nginx -s reload
-
-#After deploying the application, restart:
-cd /usr/local/Cellar/nginx/1.19.6/bin
-
-#Fast stop
-sudo nginx -s stop
-
-#Start
-sudo nginx
-
-```
-
-#### Configure the hosts file:
-```bash
-#Add the mapping <127.0.0.1 train.aias.me> to the hosts file of the client (browser) machine,
-#where 127.0.0.1 is replaced with the IP address of the server where the JAR package is running.
-
-127.0.0.1 train.aias.me
-```
-
-## Back-end deployment
-```bash
-# Compile & run the program
-java -jar aais-platform-train-0.1.0.jar
-
-```
-
-## Open the browser
-
-Enter the address: http://localhost:8080
-
-#### 1. 训练数据准备-ZIP格式压缩包:
-### 1. Training data preparation-ZIP format compression package:
-
-The compressed package must contain 2 directories (named strictly the same):
--TRAIN: Contains training data, and each folder corresponds to a classification (try to keep the number of images in each classification as balanced as possible)
--VALIDATION: Contains validation data, and each folder corresponds to a classification
-
-
-
--[Download 320 vehicle image test data](https://github.com/mymagicpower/AIAS/releases/download/apps/Cars_320.zip)
-
-### 2. Upload data and start training:
-
-- Select the zip file and upload it
-- Click the train button to start training
-
-
-#### 3. View the training process:
-
-
-#### 4. Image classification test:
-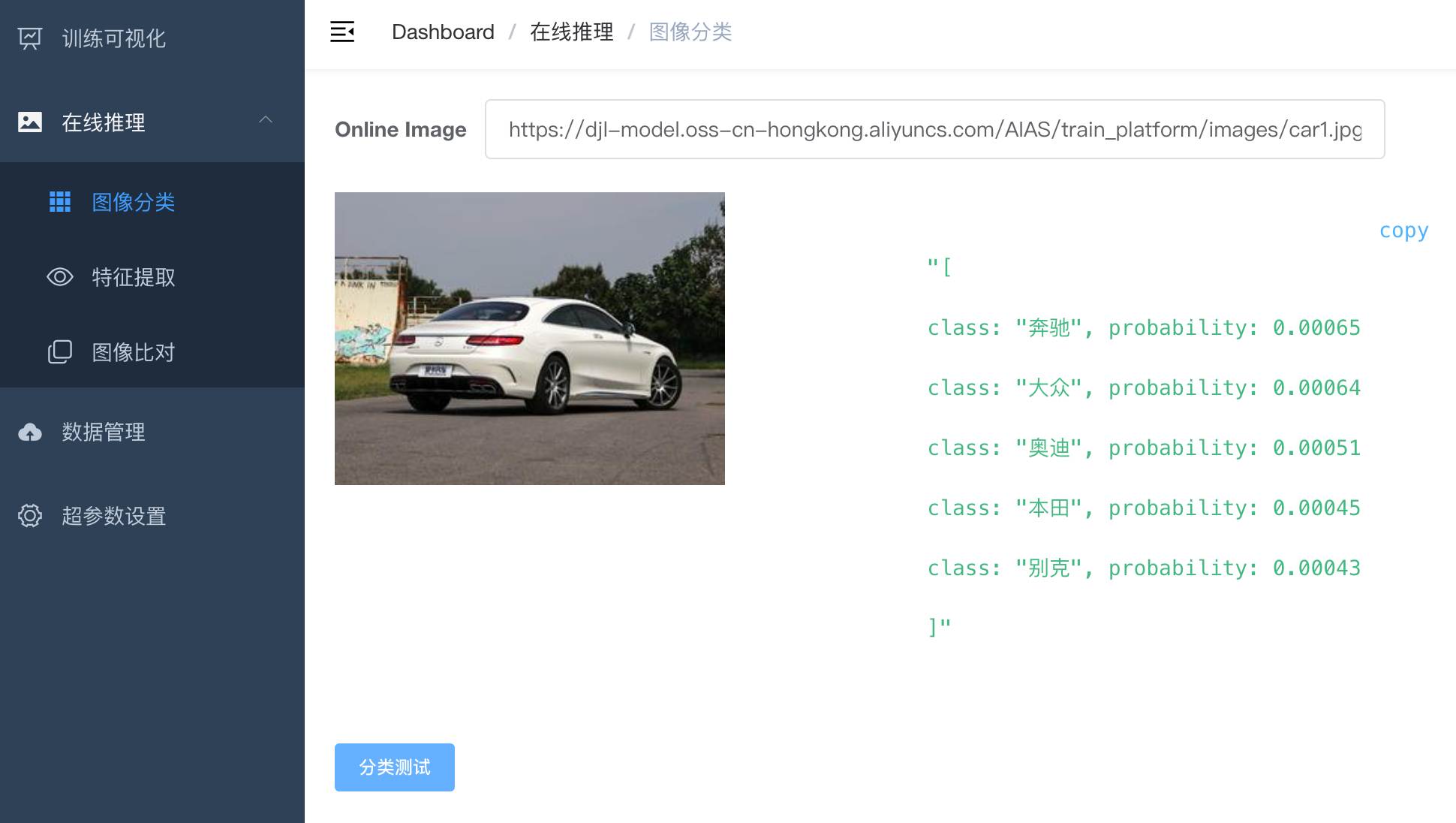
-
-#### 5. Feature extraction test:
-The image feature extraction uses the newly trained model. The features come from the feature extraction layer of the model.
-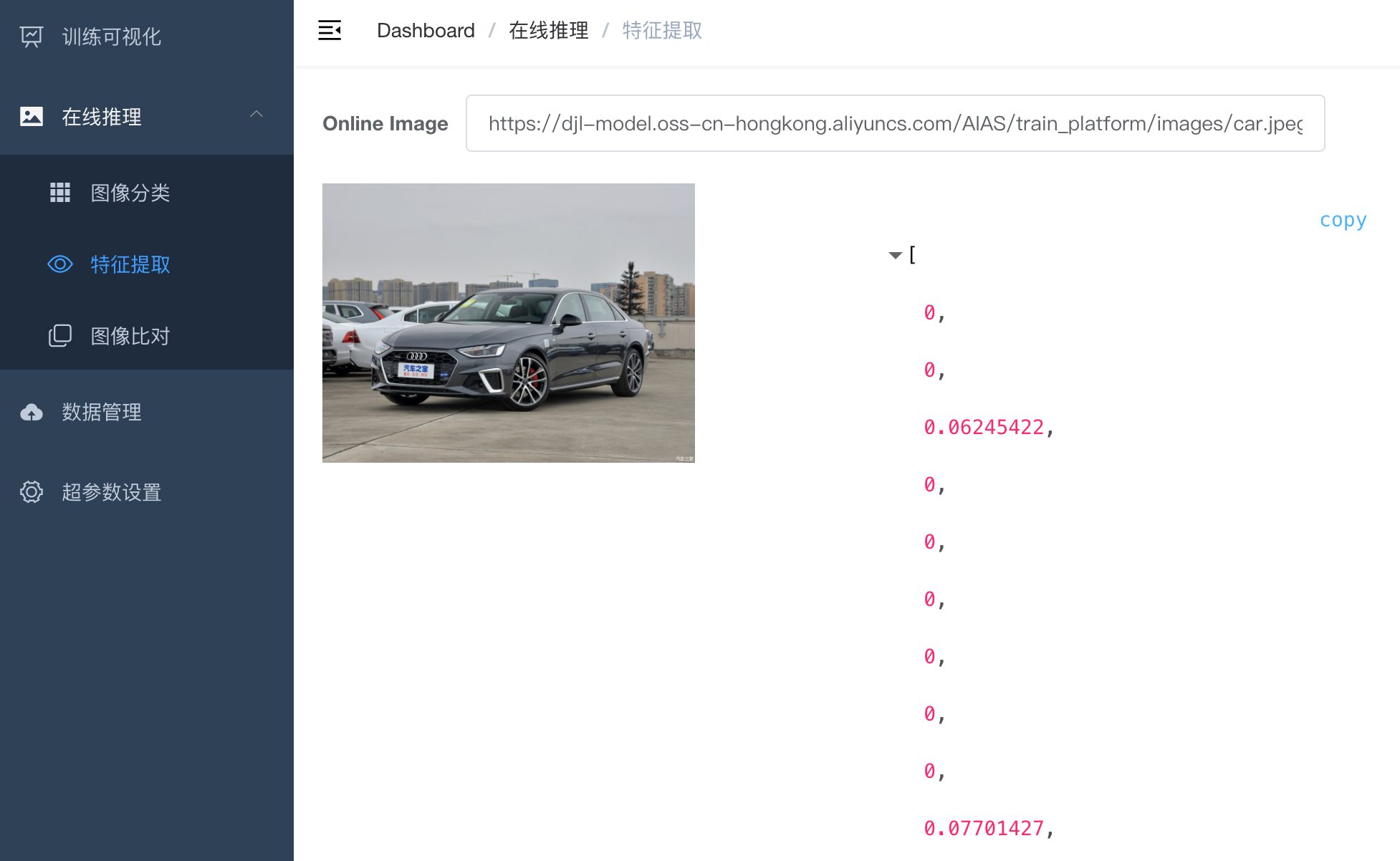
-
-#### 6. Image comparison test:
-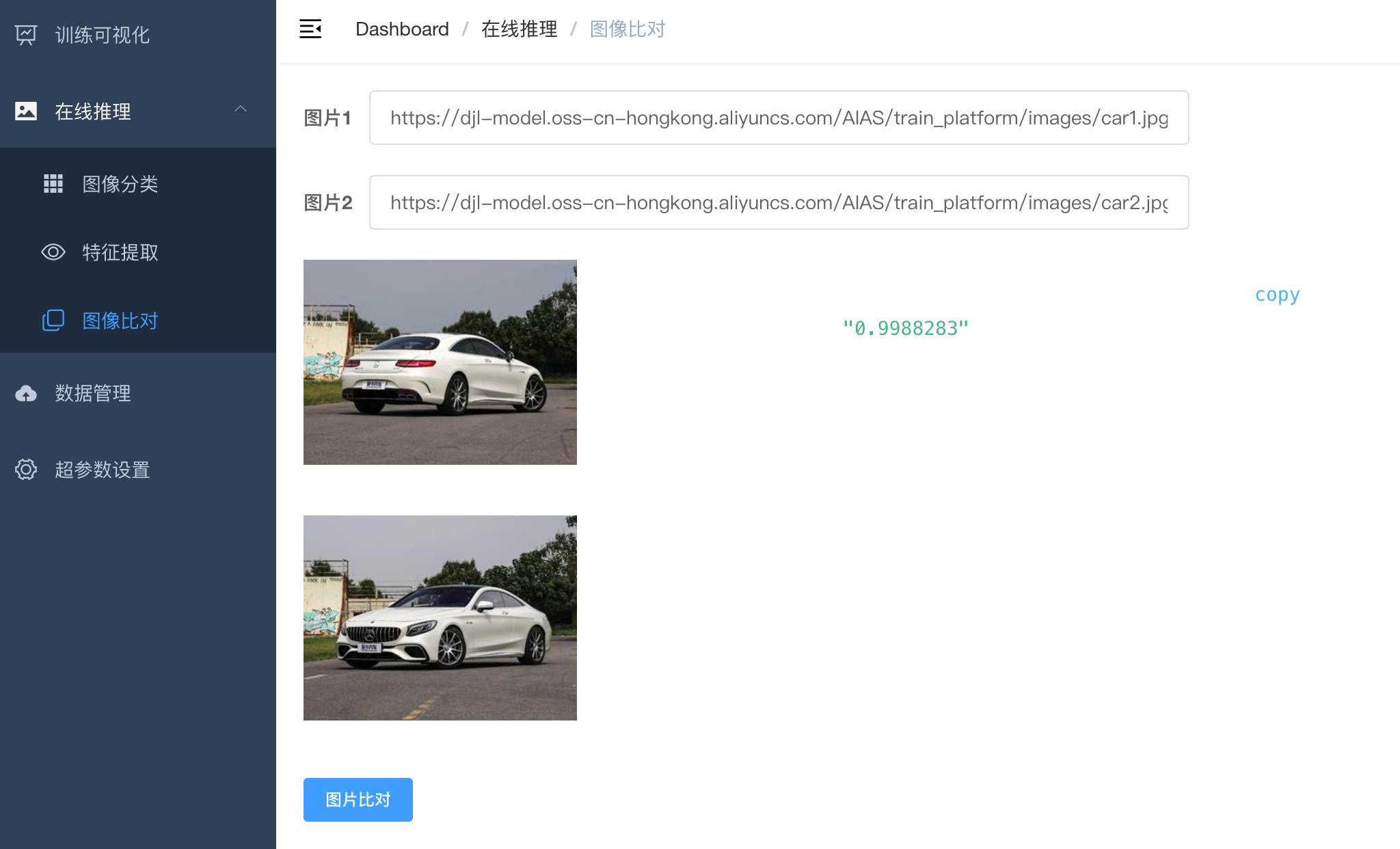
-
-#### 7. API documentation:
-http://127.0.0.1:8089/swagger-ui.html
-
-
-### Edit the application.yml in the JAR package
-
-Edit the image upload path and model save path in the application.yml as needed
-(Windows environment can use 7-zip to edit directly, no need to decompress and recompress the JAR package)
-
-```bash
-#File storage path
-file:
- mac:
- path: ~/file/
- imageRootPath: ~/file/image_root/ #Folder for decompressing compressed files
- newModelPath: ~/file/model/ #Folder for storing models after training
- linux:
- path: /home/aias/file/
- imageRootPath: /home/aias/file/image_root/ #Folder for decompressing compressed files
- newModelPath: /home/aias/file//model/ #Folder for storing models after training
- windows:
- path: C:\\aias\\file\\
- imageRootPath: C:\\aias\\file\\image_root\\ #Folder for decompressing compressed files
- newModelPath: C:\\aias\\file\\modelv2\\ #Folder for storing models after training
- #File size / M
- maxSize: 3000
-```
diff --git a/7_aigc/README.md b/7_aigc/README.md
new file mode 100644
index 00000000..6eaaa370
--- /dev/null
+++ b/7_aigc/README.md
@@ -0,0 +1,395 @@
+
+
+#### 项目清单:
+- 7_aigc - [图像生成]
+
+```text
+ 1). 图像生成预处理工具箱 controlnet_sdks
+ 2). 图像生成SD工具箱 stable_diffusion_sdks
+ ...
+```
+
+- 7.1 图像生成预处理工具箱 controlnet_sdks
+
+
+
+
+
+ 1. Canny 边缘检测
+ - canny_sdk
+ - Canny 边缘检测预处理器可很好识别出 图像内各对象的边缘轮廓,常用于生成线稿。
+ - 对应ControlNet模型: control_canny
+ |
+
+
+ 
+ |
+
+
+
+
+ 2. MLSD 线条检测
+ - mlsd_sdk
+ - MLSD 线条检测用于生成房间、 直线条的建筑场景效果比较好。
+ - 对应ControlNet模型: control_mlsd
+ |
+
+
+ 
+ |
+
+
+
+
+ 3. Scribble 涂鸦
+ - scribble_hed_sdk
+ - scribble_pidinet_sdk
+ - 图片自动生成类似涂鸦效果的草图线条。
+ - 对应ControlNet模型: control_mlsd
+ |
+
+
+ 
+ |
+
+
+
+
+ 4. SoftEdge 边缘检测
+ - softedge_hed_sdk
+ - HED - HedScribbleExample
+ - HED Safe - HedScribbleExample
+ - softedge_pidinet_sdk
+ - PidiNet - PidiNetGPUExample
+ - PidiNet Safe - PidiNetGPUExample
+ - SoftEdge 边缘检测可保留更多柔和的边缘细节, 类似手绘效果。
+ - 对应ControlNet模型: control_softedge。
+ |
+
+
+ 
+ |
+
+
+
+
+ 5. OpenPose 姿态检测
+ - pose_sdk
+ - OpenPose 姿态检测可生成图像中角色动作 姿态的骨架图(含脸部特征以及手部骨架检测) ,这个骨架图可用于控制生成角色的姿态动作。
+ - 对应ControlNet模型: control_openpose。
+ |
+
+
+ 
+ |
+
+
+
+
+ 6. Segmentation 语义分割
+ - seg_upernet_sdk
+ - 语义分割可多通道应用, 原理是用颜色把不同类型的对象分割开, 让AI能正确识别对象类型和需求生成的区界。
+ - 对应ControlNet模型: control_seg。
+ |
+
+
+ 
+ |
+
+
+
+
+ 7. Depth 深度检测
+ - depth_estimation_midas_sdk
+ - Midas - MidasDepthEstimationExample
+ - depth_estimation_dpt_sdks
+ - DPT - DptDepthEstimationExample
+ - 通过提取原始图片中的深度信息, 生成具有原图同样深度结构的深度图, 越白的越靠前,越黑的越靠后。
+ - 对应ControlNet模型: control_depth。
+ |
+
+
+ 
+ |
+
+
+
+
+ 8. Normal Map 法线贴图
+ - normal_bae_sdk
+ - NormalBaeExample
+ - 根据图片生成法线贴图,适合CG或游戏美术师。 法线贴图能根据原始素材生成 一张记录凹凸信息的法线贴图, 便于AI给图片内容进行更好的光影处理, 它比深度模型对于细节的保留更加的精确。 法线贴图在游戏制作领域用的较多, 常用于贴在低模上模拟高模的复杂光影效果。
+ - 对应ControlNet模型: control_normal。
+ |
+
+
+ 
+ |
+
+
+
+
+ 9. Lineart 生成线稿
+ - lineart_sdk
+ - lineart_coarse_sdk
+ - Lineart 边缘检测预处理器可很好识别出 图像内各对象的边缘轮廓,用于生成线稿。
+ - 对应ControlNet模型: control_lineart。
+ |
+
+
+ 
+ |
+
+
+
+
+ 10. Lineart Anime 生成线稿
+ - lineart_anime_sdk
+ - LineArtAnimeExample
+ - Lineart Anime 边缘检测预处理器 可很好识别出卡通图像内 各对象的边缘轮廓,用于生成线稿。
+ - 对应ControlNet模型: control_lineart_anime。
+ |
+
+
+ 
+ |
+
+
+
+
+ 11. Content Shuffle
+ - content_shuffle_sdk
+ - ContentShuffleExample
+ - Content Shuffle 图片内容变换位置, 打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+ - 对应ControlNet模型: control_shuffle。
+ |
+
+
+ 
+ |
+
+
+
+
+- 7.2 图像生成SD工具箱 stable_diffusion_sdks
+
+
+
+
+
+ 1. 文生图:输入提示词(仅支持英文),
生成图片(仅支持英文)
+ - txt2image_sdk
+ |
+
+
+ 
+ |
+
+
+
+
+ 2. 图生图:根据图片及提示词
(仅支持英文)生成图片
+ - image2image_sdk
+ |
+
+
+
+ |
+
+
+
+
+ 3. Lora 文生图
+ - lora_sdk
+ |
+
+
+
+ |
+
+
+
+
+ 4. Controlnet 图像生成-4.1. Canny 边缘检测
+ - controlnet_canny_sdk
+ - Canny 边缘检测预处理器可 很好识别出图像内各对象 的边缘轮廓,常用于生成线稿。
+ |
+
+
+ 
+ |
+
+
+
+
+ 4. Controlnet 图像生成-4.2. MLSD 线条检测
+ - controlnet_mlsd_sdk
+ - MLSD 线条检测用于生成房间、 直线条的建筑场景效果比较好。
+ |
+
+
+ 
+ |
+
+
+
+
+ 4. Controlnet 图像生成-4.3. Scribble 涂鸦
+ - controlnet_scribble_sdk
+ - 图片自动生成类似涂鸦效果的草图线条。
+ |
+
+
+ 
+ |
+
+
+
+
+ 4. Controlnet 图像生成-4.4. SoftEdge 边缘检测
+ - controlnet_softedge_sdk
+ - SoftEdge 边缘检测可保留更多 柔和的边缘细节,类似手绘效果。
+ |
+
+
+ 
+ |
+
+
+
+
+ 4. Controlnet 图像生成-4.5. OpenPose 姿态检测
+ - controlnet_pose_sdk
+ - OpenPose 姿态检测可生成图像 中角色动作姿态的骨架图 (含脸部特征以及手部骨架检测) ,这个骨架图可用于控制生成角色的姿态动作。
+ |
+
+
+ 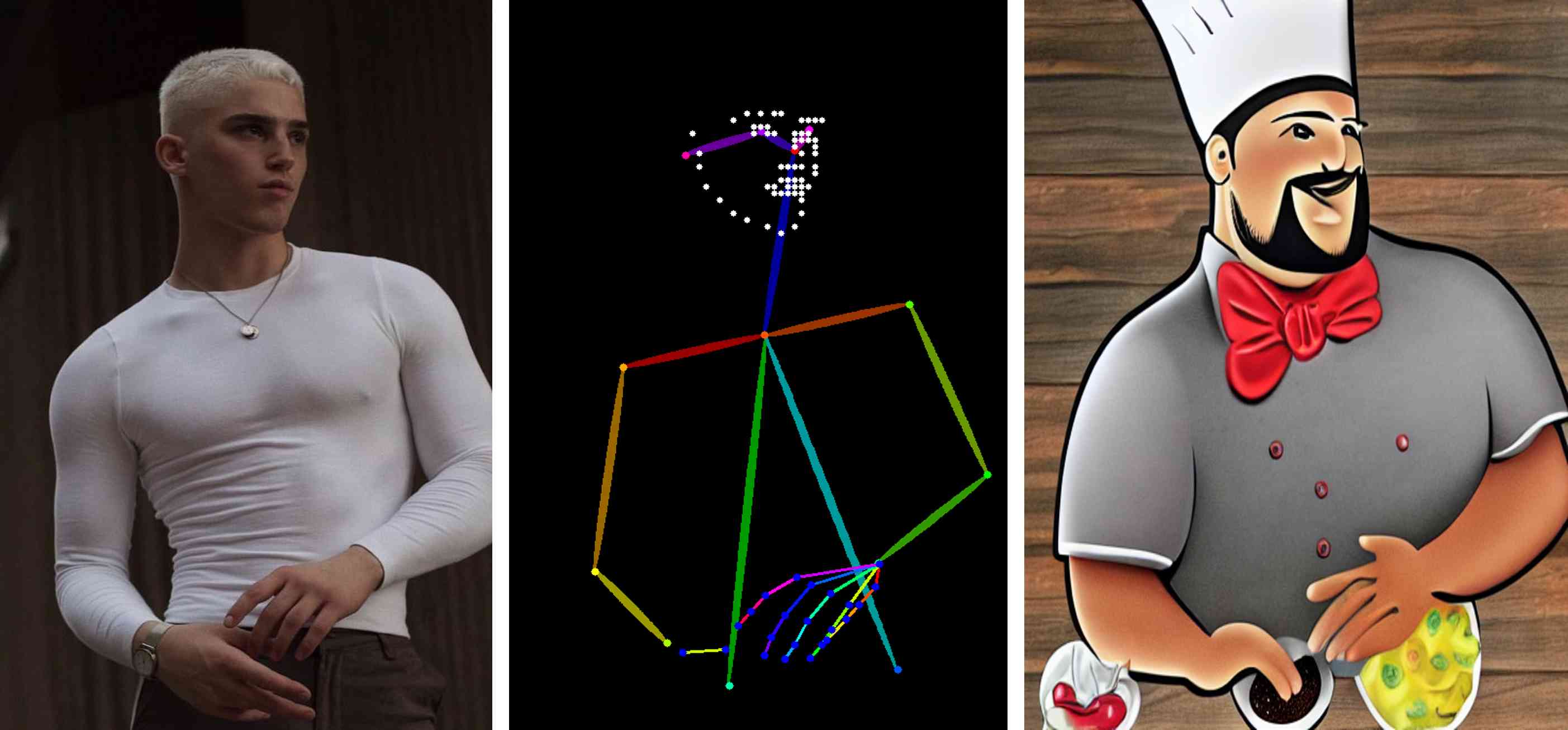
+ |
+
+
+
+
+ 4. Controlnet 图像生成-4.6. Segmentation 语义分割
+ - controlnet_seg_sdk
+ - 语义分割可多通道应用, 原理是用颜色把不同类型的对象分割开, 让AI能正确识别对象类型和需求生成的区界。
+ |
+
+
+ 
+ |
+
+
+
+
+ 4. Controlnet 图像生成-4.7. Depth 深度检测
+ - controlnet_depth_sdk
+ - 通过提取原始图片中的深度信息, 生成具有原图同样深度结构的深度图, 越白的越靠前,越黑的越靠后。
+ |
+
+
+ 
+ |
+
+
+
+
+ 4. Controlnet 图像生成-4.8. Normal Map 法线贴图
+ - controlnet_normal_sdk
+ - 根据图片生成法线贴图, 适合CG或游戏美术师。 法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图, 便于AI给图片内容进行更好的光影处理, 它比深度模型对于细节的保留更加的精确。 法线贴图在游戏制作领域用的较多, 常用于贴在低模上模拟高模的复杂光影效果。
+ |
+
+
+ 
+ |
+
+
+
+
+ 4. Controlnet 图像生成-4.9. Lineart 生成线稿
+ - controlnet_lineart_sdk
+ - controlnet_lineart_coarse_sdk
+ - Lineart 边缘检测预处理器可很好识别出 图像内各对象的边缘轮廓,用于生成线稿。
+ |
+
+
+ 
+ |
+
+
+
+
+ 4. Controlnet 图像生成-4.10. Lineart Anime 生成线稿
+ - controlnet_lineart_anime_sdk
+ - Lineart Anime 边缘检测预处理器可很好 识别出卡通图像内各对象的边缘轮廓, 用于生成线稿。
+ |
+
+
+ 
+ |
+
+
+
+
+ 4. Controlnet 图像生成-4.11. Content Shuffle
+ - controlnet_shuffle_sdk
+ - Content Shuffle 图片内容变换位置, 打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+ |
+
+
+ 
+ |
+
+
+
+
diff --git a/7_aigc/controlnet_sdks/README.md b/7_aigc/controlnet_sdks/README.md
new file mode 100644
index 00000000..28330409
--- /dev/null
+++ b/7_aigc/controlnet_sdks/README.md
@@ -0,0 +1,126 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+### 下载模型,放置于各自项目的models目录
+- 链接: https://pan.baidu.com/s/1BUnSYila9LQ_7hREZzY-3Q?pwd=h5fv
+
+### 图像生成预处理
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. Canny 边缘检测
+- CannyExample
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 2. MLSD 线条检测
+- MlsdExample
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 3. Scribble 涂鸦
+- HedScribbleExample
+- PidiNetScribbleGPUExample
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4. SoftEdge 边缘检测
+- HED - HedScribbleExample
+- HED Safe - HedScribbleExample
+- PidiNet - PidiNetGPUExample
+- PidiNet Safe - PidiNetGPUExample
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 5. OpenPose 姿态检测
+- PoseExample
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 6. Segmentation 语义分割
+- SegUperNetExample
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 7. Depth 深度检测
+- Midas - MidasDepthEstimationExample
+- DPT - DptDepthEstimationExample
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 8. Normal Map 法线贴图
+- NormalBaeExample
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 9. Lineart 生成线稿
+- LineArtExample
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 10. Lineart Anime 生成线稿
+- LineArtAnimeExample
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 11. Content Shuffle
+- ContentShuffleExample
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/controlnet_sdks/canny_sdk/README.md b/7_aigc/controlnet_sdks/canny_sdk/README.md
new file mode 100644
index 00000000..6ed834c6
--- /dev/null
+++ b/7_aigc/controlnet_sdks/canny_sdk/README.md
@@ -0,0 +1,123 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+### 图像生成预处理
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. Canny 边缘检测
+- CannyExample
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 2. MLSD 线条检测
+- MlsdExample
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 3. Scribble 涂鸦
+- HedScribbleExample
+- PidiNetScribbleGPUExample
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4. SoftEdge 边缘检测
+- HED - HedScribbleExample
+- HED Safe - HedScribbleExample
+- PidiNet - PidiNetGPUExample
+- PidiNet Safe - PidiNetGPUExample
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 5. OpenPose 姿态检测
+- PoseExample
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 6. Segmentation 语义分割
+- SegUperNetExample
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 7. Depth 深度检测
+- Midas - MidasDepthEstimationExample
+- DPT - DptDepthEstimationExample
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 8. Normal Map 法线贴图
+- NormalBaeExample
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 9. Lineart 生成线稿
+- LineArtExample
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 10. Lineart Anime 生成线稿
+- LineArtAnimeExample
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 11. Content Shuffle
+- ContentShuffleExample
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/controlnet_sdks/content_shuffle_sdk/README.md b/7_aigc/controlnet_sdks/content_shuffle_sdk/README.md
new file mode 100644
index 00000000..6ed834c6
--- /dev/null
+++ b/7_aigc/controlnet_sdks/content_shuffle_sdk/README.md
@@ -0,0 +1,123 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+### 图像生成预处理
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. Canny 边缘检测
+- CannyExample
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 2. MLSD 线条检测
+- MlsdExample
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 3. Scribble 涂鸦
+- HedScribbleExample
+- PidiNetScribbleGPUExample
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4. SoftEdge 边缘检测
+- HED - HedScribbleExample
+- HED Safe - HedScribbleExample
+- PidiNet - PidiNetGPUExample
+- PidiNet Safe - PidiNetGPUExample
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 5. OpenPose 姿态检测
+- PoseExample
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 6. Segmentation 语义分割
+- SegUperNetExample
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 7. Depth 深度检测
+- Midas - MidasDepthEstimationExample
+- DPT - DptDepthEstimationExample
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 8. Normal Map 法线贴图
+- NormalBaeExample
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 9. Lineart 生成线稿
+- LineArtExample
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 10. Lineart Anime 生成线稿
+- LineArtAnimeExample
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 11. Content Shuffle
+- ContentShuffleExample
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/controlnet_sdks/depth_estimation_dpt_sdk/README.md b/7_aigc/controlnet_sdks/depth_estimation_dpt_sdk/README.md
new file mode 100644
index 00000000..6ed834c6
--- /dev/null
+++ b/7_aigc/controlnet_sdks/depth_estimation_dpt_sdk/README.md
@@ -0,0 +1,123 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+### 图像生成预处理
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. Canny 边缘检测
+- CannyExample
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 2. MLSD 线条检测
+- MlsdExample
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 3. Scribble 涂鸦
+- HedScribbleExample
+- PidiNetScribbleGPUExample
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4. SoftEdge 边缘检测
+- HED - HedScribbleExample
+- HED Safe - HedScribbleExample
+- PidiNet - PidiNetGPUExample
+- PidiNet Safe - PidiNetGPUExample
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 5. OpenPose 姿态检测
+- PoseExample
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 6. Segmentation 语义分割
+- SegUperNetExample
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 7. Depth 深度检测
+- Midas - MidasDepthEstimationExample
+- DPT - DptDepthEstimationExample
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 8. Normal Map 法线贴图
+- NormalBaeExample
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 9. Lineart 生成线稿
+- LineArtExample
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 10. Lineart Anime 生成线稿
+- LineArtAnimeExample
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 11. Content Shuffle
+- ContentShuffleExample
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/controlnet_sdks/depth_estimation_midas_sdk/README.md b/7_aigc/controlnet_sdks/depth_estimation_midas_sdk/README.md
new file mode 100644
index 00000000..1920fda8
--- /dev/null
+++ b/7_aigc/controlnet_sdks/depth_estimation_midas_sdk/README.md
@@ -0,0 +1,123 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+### 图像生成预处理
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. Canny 边缘检测
+- CannyExample
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 2. MLSD 线条检测
+- MlsdExample
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 3. Scribble 涂鸦
+- HedScribbleExample
+- PidiNetScribbleGPUExample
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4. SoftEdge 边缘检测
+- HED - HedScribbleExample
+- HED Safe - HedScribbleExample
+- PidiNet - PidiNetGPUExample
+- PidiNet Safe - PidiNetGPUExample
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 5. OpenPose 姿态检测
+- PoseExample
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 6. Segmentation 语义分割
+- SegUperNetExample
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 7. Depth 深度检测
+- Midas - top.aias.sd.MidasDepthEstimationExample
+- DPT - DptDepthEstimationExample
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 8. Normal Map 法线贴图
+- NormalBaeExample
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 9. Lineart 生成线稿
+- LineArtExample
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 10. Lineart Anime 生成线稿
+- LineArtAnimeExample
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 11. Content Shuffle
+- ContentShuffleExample
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/controlnet_sdks/lineart_anime_sdk/README.md b/7_aigc/controlnet_sdks/lineart_anime_sdk/README.md
new file mode 100644
index 00000000..6ed834c6
--- /dev/null
+++ b/7_aigc/controlnet_sdks/lineart_anime_sdk/README.md
@@ -0,0 +1,123 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+### 图像生成预处理
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. Canny 边缘检测
+- CannyExample
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 2. MLSD 线条检测
+- MlsdExample
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 3. Scribble 涂鸦
+- HedScribbleExample
+- PidiNetScribbleGPUExample
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4. SoftEdge 边缘检测
+- HED - HedScribbleExample
+- HED Safe - HedScribbleExample
+- PidiNet - PidiNetGPUExample
+- PidiNet Safe - PidiNetGPUExample
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 5. OpenPose 姿态检测
+- PoseExample
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 6. Segmentation 语义分割
+- SegUperNetExample
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 7. Depth 深度检测
+- Midas - MidasDepthEstimationExample
+- DPT - DptDepthEstimationExample
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 8. Normal Map 法线贴图
+- NormalBaeExample
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 9. Lineart 生成线稿
+- LineArtExample
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 10. Lineart Anime 生成线稿
+- LineArtAnimeExample
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 11. Content Shuffle
+- ContentShuffleExample
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/controlnet_sdks/lineart_coarse_sdk/README.md b/7_aigc/controlnet_sdks/lineart_coarse_sdk/README.md
new file mode 100644
index 00000000..6ed834c6
--- /dev/null
+++ b/7_aigc/controlnet_sdks/lineart_coarse_sdk/README.md
@@ -0,0 +1,123 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+### 图像生成预处理
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. Canny 边缘检测
+- CannyExample
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 2. MLSD 线条检测
+- MlsdExample
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 3. Scribble 涂鸦
+- HedScribbleExample
+- PidiNetScribbleGPUExample
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4. SoftEdge 边缘检测
+- HED - HedScribbleExample
+- HED Safe - HedScribbleExample
+- PidiNet - PidiNetGPUExample
+- PidiNet Safe - PidiNetGPUExample
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 5. OpenPose 姿态检测
+- PoseExample
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 6. Segmentation 语义分割
+- SegUperNetExample
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 7. Depth 深度检测
+- Midas - MidasDepthEstimationExample
+- DPT - DptDepthEstimationExample
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 8. Normal Map 法线贴图
+- NormalBaeExample
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 9. Lineart 生成线稿
+- LineArtExample
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 10. Lineart Anime 生成线稿
+- LineArtAnimeExample
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 11. Content Shuffle
+- ContentShuffleExample
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/controlnet_sdks/lineart_sdk/README.md b/7_aigc/controlnet_sdks/lineart_sdk/README.md
new file mode 100644
index 00000000..6ed834c6
--- /dev/null
+++ b/7_aigc/controlnet_sdks/lineart_sdk/README.md
@@ -0,0 +1,123 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+### 图像生成预处理
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. Canny 边缘检测
+- CannyExample
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 2. MLSD 线条检测
+- MlsdExample
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 3. Scribble 涂鸦
+- HedScribbleExample
+- PidiNetScribbleGPUExample
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4. SoftEdge 边缘检测
+- HED - HedScribbleExample
+- HED Safe - HedScribbleExample
+- PidiNet - PidiNetGPUExample
+- PidiNet Safe - PidiNetGPUExample
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 5. OpenPose 姿态检测
+- PoseExample
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 6. Segmentation 语义分割
+- SegUperNetExample
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 7. Depth 深度检测
+- Midas - MidasDepthEstimationExample
+- DPT - DptDepthEstimationExample
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 8. Normal Map 法线贴图
+- NormalBaeExample
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 9. Lineart 生成线稿
+- LineArtExample
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 10. Lineart Anime 生成线稿
+- LineArtAnimeExample
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 11. Content Shuffle
+- ContentShuffleExample
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/controlnet_sdks/mlsd_sdk/README.md b/7_aigc/controlnet_sdks/mlsd_sdk/README.md
new file mode 100644
index 00000000..6ed834c6
--- /dev/null
+++ b/7_aigc/controlnet_sdks/mlsd_sdk/README.md
@@ -0,0 +1,123 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+### 图像生成预处理
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. Canny 边缘检测
+- CannyExample
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 2. MLSD 线条检测
+- MlsdExample
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 3. Scribble 涂鸦
+- HedScribbleExample
+- PidiNetScribbleGPUExample
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4. SoftEdge 边缘检测
+- HED - HedScribbleExample
+- HED Safe - HedScribbleExample
+- PidiNet - PidiNetGPUExample
+- PidiNet Safe - PidiNetGPUExample
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 5. OpenPose 姿态检测
+- PoseExample
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 6. Segmentation 语义分割
+- SegUperNetExample
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 7. Depth 深度检测
+- Midas - MidasDepthEstimationExample
+- DPT - DptDepthEstimationExample
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 8. Normal Map 法线贴图
+- NormalBaeExample
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 9. Lineart 生成线稿
+- LineArtExample
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 10. Lineart Anime 生成线稿
+- LineArtAnimeExample
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 11. Content Shuffle
+- ContentShuffleExample
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/controlnet_sdks/normal_bae_sdk/README.md b/7_aigc/controlnet_sdks/normal_bae_sdk/README.md
new file mode 100644
index 00000000..6ed834c6
--- /dev/null
+++ b/7_aigc/controlnet_sdks/normal_bae_sdk/README.md
@@ -0,0 +1,123 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+### 图像生成预处理
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. Canny 边缘检测
+- CannyExample
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 2. MLSD 线条检测
+- MlsdExample
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 3. Scribble 涂鸦
+- HedScribbleExample
+- PidiNetScribbleGPUExample
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4. SoftEdge 边缘检测
+- HED - HedScribbleExample
+- HED Safe - HedScribbleExample
+- PidiNet - PidiNetGPUExample
+- PidiNet Safe - PidiNetGPUExample
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 5. OpenPose 姿态检测
+- PoseExample
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 6. Segmentation 语义分割
+- SegUperNetExample
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 7. Depth 深度检测
+- Midas - MidasDepthEstimationExample
+- DPT - DptDepthEstimationExample
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 8. Normal Map 法线贴图
+- NormalBaeExample
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 9. Lineart 生成线稿
+- LineArtExample
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 10. Lineart Anime 生成线稿
+- LineArtAnimeExample
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 11. Content Shuffle
+- ContentShuffleExample
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/controlnet_sdks/pose_sdk/README.md b/7_aigc/controlnet_sdks/pose_sdk/README.md
new file mode 100644
index 00000000..6ed834c6
--- /dev/null
+++ b/7_aigc/controlnet_sdks/pose_sdk/README.md
@@ -0,0 +1,123 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+### 图像生成预处理
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. Canny 边缘检测
+- CannyExample
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 2. MLSD 线条检测
+- MlsdExample
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 3. Scribble 涂鸦
+- HedScribbleExample
+- PidiNetScribbleGPUExample
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4. SoftEdge 边缘检测
+- HED - HedScribbleExample
+- HED Safe - HedScribbleExample
+- PidiNet - PidiNetGPUExample
+- PidiNet Safe - PidiNetGPUExample
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 5. OpenPose 姿态检测
+- PoseExample
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 6. Segmentation 语义分割
+- SegUperNetExample
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 7. Depth 深度检测
+- Midas - MidasDepthEstimationExample
+- DPT - DptDepthEstimationExample
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 8. Normal Map 法线贴图
+- NormalBaeExample
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 9. Lineart 生成线稿
+- LineArtExample
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 10. Lineart Anime 生成线稿
+- LineArtAnimeExample
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 11. Content Shuffle
+- ContentShuffleExample
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/controlnet_sdks/scribble_hed_sdk/README.md b/7_aigc/controlnet_sdks/scribble_hed_sdk/README.md
new file mode 100644
index 00000000..6ed834c6
--- /dev/null
+++ b/7_aigc/controlnet_sdks/scribble_hed_sdk/README.md
@@ -0,0 +1,123 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+### 图像生成预处理
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. Canny 边缘检测
+- CannyExample
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 2. MLSD 线条检测
+- MlsdExample
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 3. Scribble 涂鸦
+- HedScribbleExample
+- PidiNetScribbleGPUExample
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4. SoftEdge 边缘检测
+- HED - HedScribbleExample
+- HED Safe - HedScribbleExample
+- PidiNet - PidiNetGPUExample
+- PidiNet Safe - PidiNetGPUExample
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 5. OpenPose 姿态检测
+- PoseExample
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 6. Segmentation 语义分割
+- SegUperNetExample
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 7. Depth 深度检测
+- Midas - MidasDepthEstimationExample
+- DPT - DptDepthEstimationExample
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 8. Normal Map 法线贴图
+- NormalBaeExample
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 9. Lineart 生成线稿
+- LineArtExample
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 10. Lineart Anime 生成线稿
+- LineArtAnimeExample
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 11. Content Shuffle
+- ContentShuffleExample
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/controlnet_sdks/scribble_pidinet_sdk/README.md b/7_aigc/controlnet_sdks/scribble_pidinet_sdk/README.md
new file mode 100644
index 00000000..6ed834c6
--- /dev/null
+++ b/7_aigc/controlnet_sdks/scribble_pidinet_sdk/README.md
@@ -0,0 +1,123 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+### 图像生成预处理
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. Canny 边缘检测
+- CannyExample
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 2. MLSD 线条检测
+- MlsdExample
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 3. Scribble 涂鸦
+- HedScribbleExample
+- PidiNetScribbleGPUExample
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4. SoftEdge 边缘检测
+- HED - HedScribbleExample
+- HED Safe - HedScribbleExample
+- PidiNet - PidiNetGPUExample
+- PidiNet Safe - PidiNetGPUExample
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 5. OpenPose 姿态检测
+- PoseExample
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 6. Segmentation 语义分割
+- SegUperNetExample
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 7. Depth 深度检测
+- Midas - MidasDepthEstimationExample
+- DPT - DptDepthEstimationExample
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 8. Normal Map 法线贴图
+- NormalBaeExample
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 9. Lineart 生成线稿
+- LineArtExample
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 10. Lineart Anime 生成线稿
+- LineArtAnimeExample
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 11. Content Shuffle
+- ContentShuffleExample
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/controlnet_sdks/softedge_hed_sdk/README.md b/7_aigc/controlnet_sdks/softedge_hed_sdk/README.md
new file mode 100644
index 00000000..6ed834c6
--- /dev/null
+++ b/7_aigc/controlnet_sdks/softedge_hed_sdk/README.md
@@ -0,0 +1,123 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+### 图像生成预处理
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. Canny 边缘检测
+- CannyExample
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 2. MLSD 线条检测
+- MlsdExample
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 3. Scribble 涂鸦
+- HedScribbleExample
+- PidiNetScribbleGPUExample
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4. SoftEdge 边缘检测
+- HED - HedScribbleExample
+- HED Safe - HedScribbleExample
+- PidiNet - PidiNetGPUExample
+- PidiNet Safe - PidiNetGPUExample
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 5. OpenPose 姿态检测
+- PoseExample
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 6. Segmentation 语义分割
+- SegUperNetExample
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 7. Depth 深度检测
+- Midas - MidasDepthEstimationExample
+- DPT - DptDepthEstimationExample
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 8. Normal Map 法线贴图
+- NormalBaeExample
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 9. Lineart 生成线稿
+- LineArtExample
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 10. Lineart Anime 生成线稿
+- LineArtAnimeExample
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 11. Content Shuffle
+- ContentShuffleExample
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/controlnet_sdks/softedge_pidinet_sdk/README.md b/7_aigc/controlnet_sdks/softedge_pidinet_sdk/README.md
new file mode 100644
index 00000000..6ed834c6
--- /dev/null
+++ b/7_aigc/controlnet_sdks/softedge_pidinet_sdk/README.md
@@ -0,0 +1,123 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+### 图像生成预处理
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. Canny 边缘检测
+- CannyExample
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 2. MLSD 线条检测
+- MlsdExample
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 3. Scribble 涂鸦
+- HedScribbleExample
+- PidiNetScribbleGPUExample
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4. SoftEdge 边缘检测
+- HED - HedScribbleExample
+- HED Safe - HedScribbleExample
+- PidiNet - PidiNetGPUExample
+- PidiNet Safe - PidiNetGPUExample
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 5. OpenPose 姿态检测
+- PoseExample
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 6. Segmentation 语义分割
+- SegUperNetExample
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 7. Depth 深度检测
+- Midas - MidasDepthEstimationExample
+- DPT - DptDepthEstimationExample
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 8. Normal Map 法线贴图
+- NormalBaeExample
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 9. Lineart 生成线稿
+- LineArtExample
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 10. Lineart Anime 生成线稿
+- LineArtAnimeExample
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 11. Content Shuffle
+- ContentShuffleExample
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/java_stable_diffusion_sdks/README.md b/7_aigc/java_stable_diffusion_sdks/README.md
new file mode 100644
index 00000000..3acbdb4d
--- /dev/null
+++ b/7_aigc/java_stable_diffusion_sdks/README.md
@@ -0,0 +1,168 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+### 下载模型,放置于各自项目的models目录
+- 链接: https://pan.baidu.com/s/1sQu1mVR6pPqyBL8nil89tg?pwd=g287
+
+#### 图像生成提示词参考
+- https://arthub.ai/
+
+#### 作品欣赏
+
+
+
+
+#### 测试环境和数据
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. 文生图:输入提示词(仅支持英文),生成图片(仅支持英文)
+- GPU版本 StableDiffusionGPU.java
+- CPU版本 StableDiffusionCPU.java
+#### 文生图测试
+- 提示词 prompt: a photo of an astronaut riding a horse on mars
+- 生成图片效果:
+
+
+
+
+### 2. 图生图:根据图片及提示词(仅支持英文)生成图片
+- CPU版本 Image2ImageCpu.java
+- GPU版本 Image2ImageGpu.java
+
+### 3. Lora 文生图
+- CPU版本 LoraTxt2ImageCpu.java
+
+### 4. Controlnet 图像生成
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 4.1. Canny 边缘检测
+- CPU版本 ControlNetCannyCpu.java
+- GPU版本 ControlNetCannyGpu.java
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 4.2. MLSD 线条检测
+- CPU版本 ControlNetMlsdCpu.java
+- GPU版本 ControlNetMlsdGpu.java
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4.3. Scribble 涂鸦
+- CPU版本 ControlNetScribbleHedCpu.java,ControlNetScribblePidiNetCpu.java
+- GPU版本 ControlNetScribbleHedGpu.java,ControlNetScribblePidiNetGpu.java
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_scribble
+
+
+
+
+
+#### 4.4. SoftEdge 边缘检测
+- HED Safe
+- PidiNet
+- PidiNet Safe
+- CPU版本 ControlNetSoftEdgeCpu
+- GPU版本 ControlNetSoftEdgeGpu
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 4.5. OpenPose 姿态检测
+- CPU版本 ControlNetPoseCpu.java
+- GPU版本 ControlNetPoseGpu.java
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 4.6. Segmentation 语义分割
+- CPU版本 ControlNetSegCpu.java
+- GPU版本 ControlNetSegGpu.java
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 4.7. Depth 深度检测
+- Midas
+- CPU版本 ControlNetDepthDptCpu.java
+- GPU版本 ControlNetDepthDptGpu.java
+- DPT
+- CPU版本 ControlNetDepthMidasCpu.java
+- GPU版本 ControlNetDepthMidasGpu.java
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 4.8. Normal Map 法线贴图
+- CPU版本 ControlNetNormalbaeCpu.java
+- GPU版本 ControlNetNormalbaeGpu.java
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 4.9. Lineart 生成线稿
+- CPU版本 ControlNetLineArtCpu.java
+- GPU版本 ControlNetLineArtGpu.java
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 4.10. Lineart Anime 生成线稿
+- CPU版本 ControlNetLineArtAnimeCpu.java
+- GPU版本 ControlNetLineArtAnimeGpu.java
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 4.11. Content Shuffle
+- CPU版本 ControlNetShuffleCpu.java
+- GPU版本 ControlNetShuffleGpu.java
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/java_stable_diffusion_sdks/controlnet_canny_sdk/README.md b/7_aigc/java_stable_diffusion_sdks/controlnet_canny_sdk/README.md
new file mode 100644
index 00000000..65bb713d
--- /dev/null
+++ b/7_aigc/java_stable_diffusion_sdks/controlnet_canny_sdk/README.md
@@ -0,0 +1,165 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+#### 图像生成提示词参考
+- https://arthub.ai/
+
+#### 作品欣赏
+
+
+
+
+#### 测试环境和数据
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. 文生图:输入提示词(仅支持英文),生成图片(仅支持英文)
+- GPU版本 StableDiffusionGPU.java
+- CPU版本 StableDiffusionCPU.java
+#### 文生图测试
+- 提示词 prompt: a photo of an astronaut riding a horse on mars
+- 生成图片效果:
+
+
+
+
+### 2. 图生图:根据图片及提示词(仅支持英文)生成图片
+- CPU版本 Image2ImageCpu.java
+- GPU版本 Image2ImageGpu.java
+
+### 3. Lora 文生图
+- CPU版本 LoraTxt2ImageCpu.java
+
+### 4. Controlnet 图像生成
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 4.1. Canny 边缘检测
+- CPU版本 ControlNetCannyCpu.java
+- GPU版本 ControlNetCannyGpu.java
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 4.2. MLSD 线条检测
+- CPU版本 ControlNetMlsdCpu.java
+- GPU版本 ControlNetMlsdGpu.java
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4.3. Scribble 涂鸦
+- CPU版本 ControlNetScribbleHedCpu.java,ControlNetScribblePidiNetCpu.java
+- GPU版本 ControlNetScribbleHedGpu.java,ControlNetScribblePidiNetGpu.java
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_scribble
+
+
+
+
+
+#### 4.4. SoftEdge 边缘检测
+- HED Safe
+- PidiNet
+- PidiNet Safe
+- CPU版本 ControlNetSoftEdgeCpu
+- GPU版本 ControlNetSoftEdgeGpu
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 4.5. OpenPose 姿态检测
+- CPU版本 ControlNetPoseCpu.java
+- GPU版本 ControlNetPoseGpu.java
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 4.6. Segmentation 语义分割
+- CPU版本 ControlNetSegCpu.java
+- GPU版本 ControlNetSegGpu.java
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 4.7. Depth 深度检测
+- Midas
+- CPU版本 ControlNetDepthDptCpu.java
+- GPU版本 ControlNetDepthDptGpu.java
+- DPT
+- CPU版本 ControlNetDepthMidasCpu.java
+- GPU版本 ControlNetDepthMidasGpu.java
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 4.8. Normal Map 法线贴图
+- CPU版本 ControlNetNormalbaeCpu.java
+- GPU版本 ControlNetNormalbaeGpu.java
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 4.9. Lineart 生成线稿
+- CPU版本 ControlNetLineArtCpu.java
+- GPU版本 ControlNetLineArtGpu.java
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 4.10. Lineart Anime 生成线稿
+- CPU版本 ControlNetLineArtAnimeCpu.java
+- GPU版本 ControlNetLineArtAnimeGpu.java
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 4.11. Content Shuffle
+- CPU版本 ControlNetShuffleCpu.java
+- GPU版本 ControlNetShuffleGpu.java
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/java_stable_diffusion_sdks/controlnet_depth_sdk/README.md b/7_aigc/java_stable_diffusion_sdks/controlnet_depth_sdk/README.md
new file mode 100644
index 00000000..65bb713d
--- /dev/null
+++ b/7_aigc/java_stable_diffusion_sdks/controlnet_depth_sdk/README.md
@@ -0,0 +1,165 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+#### 图像生成提示词参考
+- https://arthub.ai/
+
+#### 作品欣赏
+
+
+
+
+#### 测试环境和数据
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. 文生图:输入提示词(仅支持英文),生成图片(仅支持英文)
+- GPU版本 StableDiffusionGPU.java
+- CPU版本 StableDiffusionCPU.java
+#### 文生图测试
+- 提示词 prompt: a photo of an astronaut riding a horse on mars
+- 生成图片效果:
+
+
+
+
+### 2. 图生图:根据图片及提示词(仅支持英文)生成图片
+- CPU版本 Image2ImageCpu.java
+- GPU版本 Image2ImageGpu.java
+
+### 3. Lora 文生图
+- CPU版本 LoraTxt2ImageCpu.java
+
+### 4. Controlnet 图像生成
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 4.1. Canny 边缘检测
+- CPU版本 ControlNetCannyCpu.java
+- GPU版本 ControlNetCannyGpu.java
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 4.2. MLSD 线条检测
+- CPU版本 ControlNetMlsdCpu.java
+- GPU版本 ControlNetMlsdGpu.java
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4.3. Scribble 涂鸦
+- CPU版本 ControlNetScribbleHedCpu.java,ControlNetScribblePidiNetCpu.java
+- GPU版本 ControlNetScribbleHedGpu.java,ControlNetScribblePidiNetGpu.java
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_scribble
+
+
+
+
+
+#### 4.4. SoftEdge 边缘检测
+- HED Safe
+- PidiNet
+- PidiNet Safe
+- CPU版本 ControlNetSoftEdgeCpu
+- GPU版本 ControlNetSoftEdgeGpu
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 4.5. OpenPose 姿态检测
+- CPU版本 ControlNetPoseCpu.java
+- GPU版本 ControlNetPoseGpu.java
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 4.6. Segmentation 语义分割
+- CPU版本 ControlNetSegCpu.java
+- GPU版本 ControlNetSegGpu.java
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 4.7. Depth 深度检测
+- Midas
+- CPU版本 ControlNetDepthDptCpu.java
+- GPU版本 ControlNetDepthDptGpu.java
+- DPT
+- CPU版本 ControlNetDepthMidasCpu.java
+- GPU版本 ControlNetDepthMidasGpu.java
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 4.8. Normal Map 法线贴图
+- CPU版本 ControlNetNormalbaeCpu.java
+- GPU版本 ControlNetNormalbaeGpu.java
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 4.9. Lineart 生成线稿
+- CPU版本 ControlNetLineArtCpu.java
+- GPU版本 ControlNetLineArtGpu.java
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 4.10. Lineart Anime 生成线稿
+- CPU版本 ControlNetLineArtAnimeCpu.java
+- GPU版本 ControlNetLineArtAnimeGpu.java
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 4.11. Content Shuffle
+- CPU版本 ControlNetShuffleCpu.java
+- GPU版本 ControlNetShuffleGpu.java
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/java_stable_diffusion_sdks/controlnet_inpaint_sdk/README.md b/7_aigc/java_stable_diffusion_sdks/controlnet_inpaint_sdk/README.md
new file mode 100644
index 00000000..65bb713d
--- /dev/null
+++ b/7_aigc/java_stable_diffusion_sdks/controlnet_inpaint_sdk/README.md
@@ -0,0 +1,165 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+#### 图像生成提示词参考
+- https://arthub.ai/
+
+#### 作品欣赏
+
+
+
+
+#### 测试环境和数据
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. 文生图:输入提示词(仅支持英文),生成图片(仅支持英文)
+- GPU版本 StableDiffusionGPU.java
+- CPU版本 StableDiffusionCPU.java
+#### 文生图测试
+- 提示词 prompt: a photo of an astronaut riding a horse on mars
+- 生成图片效果:
+
+
+
+
+### 2. 图生图:根据图片及提示词(仅支持英文)生成图片
+- CPU版本 Image2ImageCpu.java
+- GPU版本 Image2ImageGpu.java
+
+### 3. Lora 文生图
+- CPU版本 LoraTxt2ImageCpu.java
+
+### 4. Controlnet 图像生成
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 4.1. Canny 边缘检测
+- CPU版本 ControlNetCannyCpu.java
+- GPU版本 ControlNetCannyGpu.java
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 4.2. MLSD 线条检测
+- CPU版本 ControlNetMlsdCpu.java
+- GPU版本 ControlNetMlsdGpu.java
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4.3. Scribble 涂鸦
+- CPU版本 ControlNetScribbleHedCpu.java,ControlNetScribblePidiNetCpu.java
+- GPU版本 ControlNetScribbleHedGpu.java,ControlNetScribblePidiNetGpu.java
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_scribble
+
+
+
+
+
+#### 4.4. SoftEdge 边缘检测
+- HED Safe
+- PidiNet
+- PidiNet Safe
+- CPU版本 ControlNetSoftEdgeCpu
+- GPU版本 ControlNetSoftEdgeGpu
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 4.5. OpenPose 姿态检测
+- CPU版本 ControlNetPoseCpu.java
+- GPU版本 ControlNetPoseGpu.java
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 4.6. Segmentation 语义分割
+- CPU版本 ControlNetSegCpu.java
+- GPU版本 ControlNetSegGpu.java
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 4.7. Depth 深度检测
+- Midas
+- CPU版本 ControlNetDepthDptCpu.java
+- GPU版本 ControlNetDepthDptGpu.java
+- DPT
+- CPU版本 ControlNetDepthMidasCpu.java
+- GPU版本 ControlNetDepthMidasGpu.java
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 4.8. Normal Map 法线贴图
+- CPU版本 ControlNetNormalbaeCpu.java
+- GPU版本 ControlNetNormalbaeGpu.java
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 4.9. Lineart 生成线稿
+- CPU版本 ControlNetLineArtCpu.java
+- GPU版本 ControlNetLineArtGpu.java
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 4.10. Lineart Anime 生成线稿
+- CPU版本 ControlNetLineArtAnimeCpu.java
+- GPU版本 ControlNetLineArtAnimeGpu.java
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 4.11. Content Shuffle
+- CPU版本 ControlNetShuffleCpu.java
+- GPU版本 ControlNetShuffleGpu.java
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/java_stable_diffusion_sdks/controlnet_lineart_anime_sdk/README.md b/7_aigc/java_stable_diffusion_sdks/controlnet_lineart_anime_sdk/README.md
new file mode 100644
index 00000000..65bb713d
--- /dev/null
+++ b/7_aigc/java_stable_diffusion_sdks/controlnet_lineart_anime_sdk/README.md
@@ -0,0 +1,165 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+#### 图像生成提示词参考
+- https://arthub.ai/
+
+#### 作品欣赏
+
+
+
+
+#### 测试环境和数据
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. 文生图:输入提示词(仅支持英文),生成图片(仅支持英文)
+- GPU版本 StableDiffusionGPU.java
+- CPU版本 StableDiffusionCPU.java
+#### 文生图测试
+- 提示词 prompt: a photo of an astronaut riding a horse on mars
+- 生成图片效果:
+
+
+
+
+### 2. 图生图:根据图片及提示词(仅支持英文)生成图片
+- CPU版本 Image2ImageCpu.java
+- GPU版本 Image2ImageGpu.java
+
+### 3. Lora 文生图
+- CPU版本 LoraTxt2ImageCpu.java
+
+### 4. Controlnet 图像生成
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 4.1. Canny 边缘检测
+- CPU版本 ControlNetCannyCpu.java
+- GPU版本 ControlNetCannyGpu.java
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 4.2. MLSD 线条检测
+- CPU版本 ControlNetMlsdCpu.java
+- GPU版本 ControlNetMlsdGpu.java
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4.3. Scribble 涂鸦
+- CPU版本 ControlNetScribbleHedCpu.java,ControlNetScribblePidiNetCpu.java
+- GPU版本 ControlNetScribbleHedGpu.java,ControlNetScribblePidiNetGpu.java
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_scribble
+
+
+
+
+
+#### 4.4. SoftEdge 边缘检测
+- HED Safe
+- PidiNet
+- PidiNet Safe
+- CPU版本 ControlNetSoftEdgeCpu
+- GPU版本 ControlNetSoftEdgeGpu
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 4.5. OpenPose 姿态检测
+- CPU版本 ControlNetPoseCpu.java
+- GPU版本 ControlNetPoseGpu.java
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 4.6. Segmentation 语义分割
+- CPU版本 ControlNetSegCpu.java
+- GPU版本 ControlNetSegGpu.java
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 4.7. Depth 深度检测
+- Midas
+- CPU版本 ControlNetDepthDptCpu.java
+- GPU版本 ControlNetDepthDptGpu.java
+- DPT
+- CPU版本 ControlNetDepthMidasCpu.java
+- GPU版本 ControlNetDepthMidasGpu.java
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 4.8. Normal Map 法线贴图
+- CPU版本 ControlNetNormalbaeCpu.java
+- GPU版本 ControlNetNormalbaeGpu.java
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 4.9. Lineart 生成线稿
+- CPU版本 ControlNetLineArtCpu.java
+- GPU版本 ControlNetLineArtGpu.java
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 4.10. Lineart Anime 生成线稿
+- CPU版本 ControlNetLineArtAnimeCpu.java
+- GPU版本 ControlNetLineArtAnimeGpu.java
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 4.11. Content Shuffle
+- CPU版本 ControlNetShuffleCpu.java
+- GPU版本 ControlNetShuffleGpu.java
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/java_stable_diffusion_sdks/controlnet_lineart_coarse_sdk/README.md b/7_aigc/java_stable_diffusion_sdks/controlnet_lineart_coarse_sdk/README.md
new file mode 100644
index 00000000..65bb713d
--- /dev/null
+++ b/7_aigc/java_stable_diffusion_sdks/controlnet_lineart_coarse_sdk/README.md
@@ -0,0 +1,165 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+#### 图像生成提示词参考
+- https://arthub.ai/
+
+#### 作品欣赏
+
+
+
+
+#### 测试环境和数据
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. 文生图:输入提示词(仅支持英文),生成图片(仅支持英文)
+- GPU版本 StableDiffusionGPU.java
+- CPU版本 StableDiffusionCPU.java
+#### 文生图测试
+- 提示词 prompt: a photo of an astronaut riding a horse on mars
+- 生成图片效果:
+
+
+
+
+### 2. 图生图:根据图片及提示词(仅支持英文)生成图片
+- CPU版本 Image2ImageCpu.java
+- GPU版本 Image2ImageGpu.java
+
+### 3. Lora 文生图
+- CPU版本 LoraTxt2ImageCpu.java
+
+### 4. Controlnet 图像生成
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 4.1. Canny 边缘检测
+- CPU版本 ControlNetCannyCpu.java
+- GPU版本 ControlNetCannyGpu.java
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 4.2. MLSD 线条检测
+- CPU版本 ControlNetMlsdCpu.java
+- GPU版本 ControlNetMlsdGpu.java
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4.3. Scribble 涂鸦
+- CPU版本 ControlNetScribbleHedCpu.java,ControlNetScribblePidiNetCpu.java
+- GPU版本 ControlNetScribbleHedGpu.java,ControlNetScribblePidiNetGpu.java
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_scribble
+
+
+
+
+
+#### 4.4. SoftEdge 边缘检测
+- HED Safe
+- PidiNet
+- PidiNet Safe
+- CPU版本 ControlNetSoftEdgeCpu
+- GPU版本 ControlNetSoftEdgeGpu
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 4.5. OpenPose 姿态检测
+- CPU版本 ControlNetPoseCpu.java
+- GPU版本 ControlNetPoseGpu.java
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 4.6. Segmentation 语义分割
+- CPU版本 ControlNetSegCpu.java
+- GPU版本 ControlNetSegGpu.java
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 4.7. Depth 深度检测
+- Midas
+- CPU版本 ControlNetDepthDptCpu.java
+- GPU版本 ControlNetDepthDptGpu.java
+- DPT
+- CPU版本 ControlNetDepthMidasCpu.java
+- GPU版本 ControlNetDepthMidasGpu.java
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 4.8. Normal Map 法线贴图
+- CPU版本 ControlNetNormalbaeCpu.java
+- GPU版本 ControlNetNormalbaeGpu.java
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 4.9. Lineart 生成线稿
+- CPU版本 ControlNetLineArtCpu.java
+- GPU版本 ControlNetLineArtGpu.java
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 4.10. Lineart Anime 生成线稿
+- CPU版本 ControlNetLineArtAnimeCpu.java
+- GPU版本 ControlNetLineArtAnimeGpu.java
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 4.11. Content Shuffle
+- CPU版本 ControlNetShuffleCpu.java
+- GPU版本 ControlNetShuffleGpu.java
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/java_stable_diffusion_sdks/controlnet_lineart_sdk/README.md b/7_aigc/java_stable_diffusion_sdks/controlnet_lineart_sdk/README.md
new file mode 100644
index 00000000..65bb713d
--- /dev/null
+++ b/7_aigc/java_stable_diffusion_sdks/controlnet_lineart_sdk/README.md
@@ -0,0 +1,165 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+#### 图像生成提示词参考
+- https://arthub.ai/
+
+#### 作品欣赏
+
+
+
+
+#### 测试环境和数据
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. 文生图:输入提示词(仅支持英文),生成图片(仅支持英文)
+- GPU版本 StableDiffusionGPU.java
+- CPU版本 StableDiffusionCPU.java
+#### 文生图测试
+- 提示词 prompt: a photo of an astronaut riding a horse on mars
+- 生成图片效果:
+
+
+
+
+### 2. 图生图:根据图片及提示词(仅支持英文)生成图片
+- CPU版本 Image2ImageCpu.java
+- GPU版本 Image2ImageGpu.java
+
+### 3. Lora 文生图
+- CPU版本 LoraTxt2ImageCpu.java
+
+### 4. Controlnet 图像生成
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 4.1. Canny 边缘检测
+- CPU版本 ControlNetCannyCpu.java
+- GPU版本 ControlNetCannyGpu.java
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 4.2. MLSD 线条检测
+- CPU版本 ControlNetMlsdCpu.java
+- GPU版本 ControlNetMlsdGpu.java
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4.3. Scribble 涂鸦
+- CPU版本 ControlNetScribbleHedCpu.java,ControlNetScribblePidiNetCpu.java
+- GPU版本 ControlNetScribbleHedGpu.java,ControlNetScribblePidiNetGpu.java
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_scribble
+
+
+
+
+
+#### 4.4. SoftEdge 边缘检测
+- HED Safe
+- PidiNet
+- PidiNet Safe
+- CPU版本 ControlNetSoftEdgeCpu
+- GPU版本 ControlNetSoftEdgeGpu
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 4.5. OpenPose 姿态检测
+- CPU版本 ControlNetPoseCpu.java
+- GPU版本 ControlNetPoseGpu.java
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 4.6. Segmentation 语义分割
+- CPU版本 ControlNetSegCpu.java
+- GPU版本 ControlNetSegGpu.java
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 4.7. Depth 深度检测
+- Midas
+- CPU版本 ControlNetDepthDptCpu.java
+- GPU版本 ControlNetDepthDptGpu.java
+- DPT
+- CPU版本 ControlNetDepthMidasCpu.java
+- GPU版本 ControlNetDepthMidasGpu.java
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 4.8. Normal Map 法线贴图
+- CPU版本 ControlNetNormalbaeCpu.java
+- GPU版本 ControlNetNormalbaeGpu.java
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 4.9. Lineart 生成线稿
+- CPU版本 ControlNetLineArtCpu.java
+- GPU版本 ControlNetLineArtGpu.java
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 4.10. Lineart Anime 生成线稿
+- CPU版本 ControlNetLineArtAnimeCpu.java
+- GPU版本 ControlNetLineArtAnimeGpu.java
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 4.11. Content Shuffle
+- CPU版本 ControlNetShuffleCpu.java
+- GPU版本 ControlNetShuffleGpu.java
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/java_stable_diffusion_sdks/controlnet_normal_sdk/README.md b/7_aigc/java_stable_diffusion_sdks/controlnet_normal_sdk/README.md
new file mode 100644
index 00000000..65bb713d
--- /dev/null
+++ b/7_aigc/java_stable_diffusion_sdks/controlnet_normal_sdk/README.md
@@ -0,0 +1,165 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+#### 图像生成提示词参考
+- https://arthub.ai/
+
+#### 作品欣赏
+
+
+
+
+#### 测试环境和数据
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. 文生图:输入提示词(仅支持英文),生成图片(仅支持英文)
+- GPU版本 StableDiffusionGPU.java
+- CPU版本 StableDiffusionCPU.java
+#### 文生图测试
+- 提示词 prompt: a photo of an astronaut riding a horse on mars
+- 生成图片效果:
+
+
+
+
+### 2. 图生图:根据图片及提示词(仅支持英文)生成图片
+- CPU版本 Image2ImageCpu.java
+- GPU版本 Image2ImageGpu.java
+
+### 3. Lora 文生图
+- CPU版本 LoraTxt2ImageCpu.java
+
+### 4. Controlnet 图像生成
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 4.1. Canny 边缘检测
+- CPU版本 ControlNetCannyCpu.java
+- GPU版本 ControlNetCannyGpu.java
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 4.2. MLSD 线条检测
+- CPU版本 ControlNetMlsdCpu.java
+- GPU版本 ControlNetMlsdGpu.java
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4.3. Scribble 涂鸦
+- CPU版本 ControlNetScribbleHedCpu.java,ControlNetScribblePidiNetCpu.java
+- GPU版本 ControlNetScribbleHedGpu.java,ControlNetScribblePidiNetGpu.java
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_scribble
+
+
+
+
+
+#### 4.4. SoftEdge 边缘检测
+- HED Safe
+- PidiNet
+- PidiNet Safe
+- CPU版本 ControlNetSoftEdgeCpu
+- GPU版本 ControlNetSoftEdgeGpu
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 4.5. OpenPose 姿态检测
+- CPU版本 ControlNetPoseCpu.java
+- GPU版本 ControlNetPoseGpu.java
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 4.6. Segmentation 语义分割
+- CPU版本 ControlNetSegCpu.java
+- GPU版本 ControlNetSegGpu.java
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 4.7. Depth 深度检测
+- Midas
+- CPU版本 ControlNetDepthDptCpu.java
+- GPU版本 ControlNetDepthDptGpu.java
+- DPT
+- CPU版本 ControlNetDepthMidasCpu.java
+- GPU版本 ControlNetDepthMidasGpu.java
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 4.8. Normal Map 法线贴图
+- CPU版本 ControlNetNormalbaeCpu.java
+- GPU版本 ControlNetNormalbaeGpu.java
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 4.9. Lineart 生成线稿
+- CPU版本 ControlNetLineArtCpu.java
+- GPU版本 ControlNetLineArtGpu.java
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 4.10. Lineart Anime 生成线稿
+- CPU版本 ControlNetLineArtAnimeCpu.java
+- GPU版本 ControlNetLineArtAnimeGpu.java
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 4.11. Content Shuffle
+- CPU版本 ControlNetShuffleCpu.java
+- GPU版本 ControlNetShuffleGpu.java
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/java_stable_diffusion_sdks/controlnet_p2p_sdk/README.md b/7_aigc/java_stable_diffusion_sdks/controlnet_p2p_sdk/README.md
new file mode 100644
index 00000000..65bb713d
--- /dev/null
+++ b/7_aigc/java_stable_diffusion_sdks/controlnet_p2p_sdk/README.md
@@ -0,0 +1,165 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+#### 图像生成提示词参考
+- https://arthub.ai/
+
+#### 作品欣赏
+
+
+
+
+#### 测试环境和数据
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. 文生图:输入提示词(仅支持英文),生成图片(仅支持英文)
+- GPU版本 StableDiffusionGPU.java
+- CPU版本 StableDiffusionCPU.java
+#### 文生图测试
+- 提示词 prompt: a photo of an astronaut riding a horse on mars
+- 生成图片效果:
+
+
+
+
+### 2. 图生图:根据图片及提示词(仅支持英文)生成图片
+- CPU版本 Image2ImageCpu.java
+- GPU版本 Image2ImageGpu.java
+
+### 3. Lora 文生图
+- CPU版本 LoraTxt2ImageCpu.java
+
+### 4. Controlnet 图像生成
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 4.1. Canny 边缘检测
+- CPU版本 ControlNetCannyCpu.java
+- GPU版本 ControlNetCannyGpu.java
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 4.2. MLSD 线条检测
+- CPU版本 ControlNetMlsdCpu.java
+- GPU版本 ControlNetMlsdGpu.java
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4.3. Scribble 涂鸦
+- CPU版本 ControlNetScribbleHedCpu.java,ControlNetScribblePidiNetCpu.java
+- GPU版本 ControlNetScribbleHedGpu.java,ControlNetScribblePidiNetGpu.java
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_scribble
+
+
+
+
+
+#### 4.4. SoftEdge 边缘检测
+- HED Safe
+- PidiNet
+- PidiNet Safe
+- CPU版本 ControlNetSoftEdgeCpu
+- GPU版本 ControlNetSoftEdgeGpu
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 4.5. OpenPose 姿态检测
+- CPU版本 ControlNetPoseCpu.java
+- GPU版本 ControlNetPoseGpu.java
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 4.6. Segmentation 语义分割
+- CPU版本 ControlNetSegCpu.java
+- GPU版本 ControlNetSegGpu.java
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 4.7. Depth 深度检测
+- Midas
+- CPU版本 ControlNetDepthDptCpu.java
+- GPU版本 ControlNetDepthDptGpu.java
+- DPT
+- CPU版本 ControlNetDepthMidasCpu.java
+- GPU版本 ControlNetDepthMidasGpu.java
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 4.8. Normal Map 法线贴图
+- CPU版本 ControlNetNormalbaeCpu.java
+- GPU版本 ControlNetNormalbaeGpu.java
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 4.9. Lineart 生成线稿
+- CPU版本 ControlNetLineArtCpu.java
+- GPU版本 ControlNetLineArtGpu.java
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 4.10. Lineart Anime 生成线稿
+- CPU版本 ControlNetLineArtAnimeCpu.java
+- GPU版本 ControlNetLineArtAnimeGpu.java
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 4.11. Content Shuffle
+- CPU版本 ControlNetShuffleCpu.java
+- GPU版本 ControlNetShuffleGpu.java
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/java_stable_diffusion_sdks/controlnet_pose_sdk/README.md b/7_aigc/java_stable_diffusion_sdks/controlnet_pose_sdk/README.md
new file mode 100644
index 00000000..65bb713d
--- /dev/null
+++ b/7_aigc/java_stable_diffusion_sdks/controlnet_pose_sdk/README.md
@@ -0,0 +1,165 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+#### 图像生成提示词参考
+- https://arthub.ai/
+
+#### 作品欣赏
+
+
+
+
+#### 测试环境和数据
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. 文生图:输入提示词(仅支持英文),生成图片(仅支持英文)
+- GPU版本 StableDiffusionGPU.java
+- CPU版本 StableDiffusionCPU.java
+#### 文生图测试
+- 提示词 prompt: a photo of an astronaut riding a horse on mars
+- 生成图片效果:
+
+
+
+
+### 2. 图生图:根据图片及提示词(仅支持英文)生成图片
+- CPU版本 Image2ImageCpu.java
+- GPU版本 Image2ImageGpu.java
+
+### 3. Lora 文生图
+- CPU版本 LoraTxt2ImageCpu.java
+
+### 4. Controlnet 图像生成
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 4.1. Canny 边缘检测
+- CPU版本 ControlNetCannyCpu.java
+- GPU版本 ControlNetCannyGpu.java
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 4.2. MLSD 线条检测
+- CPU版本 ControlNetMlsdCpu.java
+- GPU版本 ControlNetMlsdGpu.java
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4.3. Scribble 涂鸦
+- CPU版本 ControlNetScribbleHedCpu.java,ControlNetScribblePidiNetCpu.java
+- GPU版本 ControlNetScribbleHedGpu.java,ControlNetScribblePidiNetGpu.java
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_scribble
+
+
+
+
+
+#### 4.4. SoftEdge 边缘检测
+- HED Safe
+- PidiNet
+- PidiNet Safe
+- CPU版本 ControlNetSoftEdgeCpu
+- GPU版本 ControlNetSoftEdgeGpu
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 4.5. OpenPose 姿态检测
+- CPU版本 ControlNetPoseCpu.java
+- GPU版本 ControlNetPoseGpu.java
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 4.6. Segmentation 语义分割
+- CPU版本 ControlNetSegCpu.java
+- GPU版本 ControlNetSegGpu.java
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 4.7. Depth 深度检测
+- Midas
+- CPU版本 ControlNetDepthDptCpu.java
+- GPU版本 ControlNetDepthDptGpu.java
+- DPT
+- CPU版本 ControlNetDepthMidasCpu.java
+- GPU版本 ControlNetDepthMidasGpu.java
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 4.8. Normal Map 法线贴图
+- CPU版本 ControlNetNormalbaeCpu.java
+- GPU版本 ControlNetNormalbaeGpu.java
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 4.9. Lineart 生成线稿
+- CPU版本 ControlNetLineArtCpu.java
+- GPU版本 ControlNetLineArtGpu.java
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 4.10. Lineart Anime 生成线稿
+- CPU版本 ControlNetLineArtAnimeCpu.java
+- GPU版本 ControlNetLineArtAnimeGpu.java
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 4.11. Content Shuffle
+- CPU版本 ControlNetShuffleCpu.java
+- GPU版本 ControlNetShuffleGpu.java
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/java_stable_diffusion_sdks/controlnet_scribble_sdk/README.md b/7_aigc/java_stable_diffusion_sdks/controlnet_scribble_sdk/README.md
new file mode 100644
index 00000000..65bb713d
--- /dev/null
+++ b/7_aigc/java_stable_diffusion_sdks/controlnet_scribble_sdk/README.md
@@ -0,0 +1,165 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+#### 图像生成提示词参考
+- https://arthub.ai/
+
+#### 作品欣赏
+
+
+
+
+#### 测试环境和数据
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. 文生图:输入提示词(仅支持英文),生成图片(仅支持英文)
+- GPU版本 StableDiffusionGPU.java
+- CPU版本 StableDiffusionCPU.java
+#### 文生图测试
+- 提示词 prompt: a photo of an astronaut riding a horse on mars
+- 生成图片效果:
+
+
+
+
+### 2. 图生图:根据图片及提示词(仅支持英文)生成图片
+- CPU版本 Image2ImageCpu.java
+- GPU版本 Image2ImageGpu.java
+
+### 3. Lora 文生图
+- CPU版本 LoraTxt2ImageCpu.java
+
+### 4. Controlnet 图像生成
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 4.1. Canny 边缘检测
+- CPU版本 ControlNetCannyCpu.java
+- GPU版本 ControlNetCannyGpu.java
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 4.2. MLSD 线条检测
+- CPU版本 ControlNetMlsdCpu.java
+- GPU版本 ControlNetMlsdGpu.java
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4.3. Scribble 涂鸦
+- CPU版本 ControlNetScribbleHedCpu.java,ControlNetScribblePidiNetCpu.java
+- GPU版本 ControlNetScribbleHedGpu.java,ControlNetScribblePidiNetGpu.java
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_scribble
+
+
+
+
+
+#### 4.4. SoftEdge 边缘检测
+- HED Safe
+- PidiNet
+- PidiNet Safe
+- CPU版本 ControlNetSoftEdgeCpu
+- GPU版本 ControlNetSoftEdgeGpu
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 4.5. OpenPose 姿态检测
+- CPU版本 ControlNetPoseCpu.java
+- GPU版本 ControlNetPoseGpu.java
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 4.6. Segmentation 语义分割
+- CPU版本 ControlNetSegCpu.java
+- GPU版本 ControlNetSegGpu.java
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 4.7. Depth 深度检测
+- Midas
+- CPU版本 ControlNetDepthDptCpu.java
+- GPU版本 ControlNetDepthDptGpu.java
+- DPT
+- CPU版本 ControlNetDepthMidasCpu.java
+- GPU版本 ControlNetDepthMidasGpu.java
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 4.8. Normal Map 法线贴图
+- CPU版本 ControlNetNormalbaeCpu.java
+- GPU版本 ControlNetNormalbaeGpu.java
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 4.9. Lineart 生成线稿
+- CPU版本 ControlNetLineArtCpu.java
+- GPU版本 ControlNetLineArtGpu.java
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 4.10. Lineart Anime 生成线稿
+- CPU版本 ControlNetLineArtAnimeCpu.java
+- GPU版本 ControlNetLineArtAnimeGpu.java
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 4.11. Content Shuffle
+- CPU版本 ControlNetShuffleCpu.java
+- GPU版本 ControlNetShuffleGpu.java
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/java_stable_diffusion_sdks/controlnet_seg_sdk/README.md b/7_aigc/java_stable_diffusion_sdks/controlnet_seg_sdk/README.md
new file mode 100644
index 00000000..65bb713d
--- /dev/null
+++ b/7_aigc/java_stable_diffusion_sdks/controlnet_seg_sdk/README.md
@@ -0,0 +1,165 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+#### 图像生成提示词参考
+- https://arthub.ai/
+
+#### 作品欣赏
+
+
+
+
+#### 测试环境和数据
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. 文生图:输入提示词(仅支持英文),生成图片(仅支持英文)
+- GPU版本 StableDiffusionGPU.java
+- CPU版本 StableDiffusionCPU.java
+#### 文生图测试
+- 提示词 prompt: a photo of an astronaut riding a horse on mars
+- 生成图片效果:
+
+
+
+
+### 2. 图生图:根据图片及提示词(仅支持英文)生成图片
+- CPU版本 Image2ImageCpu.java
+- GPU版本 Image2ImageGpu.java
+
+### 3. Lora 文生图
+- CPU版本 LoraTxt2ImageCpu.java
+
+### 4. Controlnet 图像生成
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 4.1. Canny 边缘检测
+- CPU版本 ControlNetCannyCpu.java
+- GPU版本 ControlNetCannyGpu.java
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 4.2. MLSD 线条检测
+- CPU版本 ControlNetMlsdCpu.java
+- GPU版本 ControlNetMlsdGpu.java
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4.3. Scribble 涂鸦
+- CPU版本 ControlNetScribbleHedCpu.java,ControlNetScribblePidiNetCpu.java
+- GPU版本 ControlNetScribbleHedGpu.java,ControlNetScribblePidiNetGpu.java
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_scribble
+
+
+
+
+
+#### 4.4. SoftEdge 边缘检测
+- HED Safe
+- PidiNet
+- PidiNet Safe
+- CPU版本 ControlNetSoftEdgeCpu
+- GPU版本 ControlNetSoftEdgeGpu
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 4.5. OpenPose 姿态检测
+- CPU版本 ControlNetPoseCpu.java
+- GPU版本 ControlNetPoseGpu.java
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 4.6. Segmentation 语义分割
+- CPU版本 ControlNetSegCpu.java
+- GPU版本 ControlNetSegGpu.java
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 4.7. Depth 深度检测
+- Midas
+- CPU版本 ControlNetDepthDptCpu.java
+- GPU版本 ControlNetDepthDptGpu.java
+- DPT
+- CPU版本 ControlNetDepthMidasCpu.java
+- GPU版本 ControlNetDepthMidasGpu.java
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 4.8. Normal Map 法线贴图
+- CPU版本 ControlNetNormalbaeCpu.java
+- GPU版本 ControlNetNormalbaeGpu.java
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 4.9. Lineart 生成线稿
+- CPU版本 ControlNetLineArtCpu.java
+- GPU版本 ControlNetLineArtGpu.java
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 4.10. Lineart Anime 生成线稿
+- CPU版本 ControlNetLineArtAnimeCpu.java
+- GPU版本 ControlNetLineArtAnimeGpu.java
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 4.11. Content Shuffle
+- CPU版本 ControlNetShuffleCpu.java
+- GPU版本 ControlNetShuffleGpu.java
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/java_stable_diffusion_sdks/controlnet_shuffle_sdk/README.md b/7_aigc/java_stable_diffusion_sdks/controlnet_shuffle_sdk/README.md
new file mode 100644
index 00000000..65bb713d
--- /dev/null
+++ b/7_aigc/java_stable_diffusion_sdks/controlnet_shuffle_sdk/README.md
@@ -0,0 +1,165 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+#### 图像生成提示词参考
+- https://arthub.ai/
+
+#### 作品欣赏
+
+
+
+
+#### 测试环境和数据
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. 文生图:输入提示词(仅支持英文),生成图片(仅支持英文)
+- GPU版本 StableDiffusionGPU.java
+- CPU版本 StableDiffusionCPU.java
+#### 文生图测试
+- 提示词 prompt: a photo of an astronaut riding a horse on mars
+- 生成图片效果:
+
+
+
+
+### 2. 图生图:根据图片及提示词(仅支持英文)生成图片
+- CPU版本 Image2ImageCpu.java
+- GPU版本 Image2ImageGpu.java
+
+### 3. Lora 文生图
+- CPU版本 LoraTxt2ImageCpu.java
+
+### 4. Controlnet 图像生成
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 4.1. Canny 边缘检测
+- CPU版本 ControlNetCannyCpu.java
+- GPU版本 ControlNetCannyGpu.java
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 4.2. MLSD 线条检测
+- CPU版本 ControlNetMlsdCpu.java
+- GPU版本 ControlNetMlsdGpu.java
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4.3. Scribble 涂鸦
+- CPU版本 ControlNetScribbleHedCpu.java,ControlNetScribblePidiNetCpu.java
+- GPU版本 ControlNetScribbleHedGpu.java,ControlNetScribblePidiNetGpu.java
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_scribble
+
+
+
+
+
+#### 4.4. SoftEdge 边缘检测
+- HED Safe
+- PidiNet
+- PidiNet Safe
+- CPU版本 ControlNetSoftEdgeCpu
+- GPU版本 ControlNetSoftEdgeGpu
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 4.5. OpenPose 姿态检测
+- CPU版本 ControlNetPoseCpu.java
+- GPU版本 ControlNetPoseGpu.java
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 4.6. Segmentation 语义分割
+- CPU版本 ControlNetSegCpu.java
+- GPU版本 ControlNetSegGpu.java
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 4.7. Depth 深度检测
+- Midas
+- CPU版本 ControlNetDepthDptCpu.java
+- GPU版本 ControlNetDepthDptGpu.java
+- DPT
+- CPU版本 ControlNetDepthMidasCpu.java
+- GPU版本 ControlNetDepthMidasGpu.java
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 4.8. Normal Map 法线贴图
+- CPU版本 ControlNetNormalbaeCpu.java
+- GPU版本 ControlNetNormalbaeGpu.java
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 4.9. Lineart 生成线稿
+- CPU版本 ControlNetLineArtCpu.java
+- GPU版本 ControlNetLineArtGpu.java
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 4.10. Lineart Anime 生成线稿
+- CPU版本 ControlNetLineArtAnimeCpu.java
+- GPU版本 ControlNetLineArtAnimeGpu.java
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 4.11. Content Shuffle
+- CPU版本 ControlNetShuffleCpu.java
+- GPU版本 ControlNetShuffleGpu.java
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/java_stable_diffusion_sdks/controlnet_softedge_sdk/README.md b/7_aigc/java_stable_diffusion_sdks/controlnet_softedge_sdk/README.md
new file mode 100644
index 00000000..65bb713d
--- /dev/null
+++ b/7_aigc/java_stable_diffusion_sdks/controlnet_softedge_sdk/README.md
@@ -0,0 +1,165 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+#### 图像生成提示词参考
+- https://arthub.ai/
+
+#### 作品欣赏
+
+
+
+
+#### 测试环境和数据
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. 文生图:输入提示词(仅支持英文),生成图片(仅支持英文)
+- GPU版本 StableDiffusionGPU.java
+- CPU版本 StableDiffusionCPU.java
+#### 文生图测试
+- 提示词 prompt: a photo of an astronaut riding a horse on mars
+- 生成图片效果:
+
+
+
+
+### 2. 图生图:根据图片及提示词(仅支持英文)生成图片
+- CPU版本 Image2ImageCpu.java
+- GPU版本 Image2ImageGpu.java
+
+### 3. Lora 文生图
+- CPU版本 LoraTxt2ImageCpu.java
+
+### 4. Controlnet 图像生成
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 4.1. Canny 边缘检测
+- CPU版本 ControlNetCannyCpu.java
+- GPU版本 ControlNetCannyGpu.java
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 4.2. MLSD 线条检测
+- CPU版本 ControlNetMlsdCpu.java
+- GPU版本 ControlNetMlsdGpu.java
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4.3. Scribble 涂鸦
+- CPU版本 ControlNetScribbleHedCpu.java,ControlNetScribblePidiNetCpu.java
+- GPU版本 ControlNetScribbleHedGpu.java,ControlNetScribblePidiNetGpu.java
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_scribble
+
+
+
+
+
+#### 4.4. SoftEdge 边缘检测
+- HED Safe
+- PidiNet
+- PidiNet Safe
+- CPU版本 ControlNetSoftEdgeCpu
+- GPU版本 ControlNetSoftEdgeGpu
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 4.5. OpenPose 姿态检测
+- CPU版本 ControlNetPoseCpu.java
+- GPU版本 ControlNetPoseGpu.java
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 4.6. Segmentation 语义分割
+- CPU版本 ControlNetSegCpu.java
+- GPU版本 ControlNetSegGpu.java
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 4.7. Depth 深度检测
+- Midas
+- CPU版本 ControlNetDepthDptCpu.java
+- GPU版本 ControlNetDepthDptGpu.java
+- DPT
+- CPU版本 ControlNetDepthMidasCpu.java
+- GPU版本 ControlNetDepthMidasGpu.java
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 4.8. Normal Map 法线贴图
+- CPU版本 ControlNetNormalbaeCpu.java
+- GPU版本 ControlNetNormalbaeGpu.java
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 4.9. Lineart 生成线稿
+- CPU版本 ControlNetLineArtCpu.java
+- GPU版本 ControlNetLineArtGpu.java
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 4.10. Lineart Anime 生成线稿
+- CPU版本 ControlNetLineArtAnimeCpu.java
+- GPU版本 ControlNetLineArtAnimeGpu.java
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 4.11. Content Shuffle
+- CPU版本 ControlNetShuffleCpu.java
+- GPU版本 ControlNetShuffleGpu.java
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/java_stable_diffusion_sdks/image2image_sdk/README.md b/7_aigc/java_stable_diffusion_sdks/image2image_sdk/README.md
new file mode 100644
index 00000000..65bb713d
--- /dev/null
+++ b/7_aigc/java_stable_diffusion_sdks/image2image_sdk/README.md
@@ -0,0 +1,165 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+#### 图像生成提示词参考
+- https://arthub.ai/
+
+#### 作品欣赏
+
+
+
+
+#### 测试环境和数据
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. 文生图:输入提示词(仅支持英文),生成图片(仅支持英文)
+- GPU版本 StableDiffusionGPU.java
+- CPU版本 StableDiffusionCPU.java
+#### 文生图测试
+- 提示词 prompt: a photo of an astronaut riding a horse on mars
+- 生成图片效果:
+
+
+
+
+### 2. 图生图:根据图片及提示词(仅支持英文)生成图片
+- CPU版本 Image2ImageCpu.java
+- GPU版本 Image2ImageGpu.java
+
+### 3. Lora 文生图
+- CPU版本 LoraTxt2ImageCpu.java
+
+### 4. Controlnet 图像生成
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 4.1. Canny 边缘检测
+- CPU版本 ControlNetCannyCpu.java
+- GPU版本 ControlNetCannyGpu.java
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 4.2. MLSD 线条检测
+- CPU版本 ControlNetMlsdCpu.java
+- GPU版本 ControlNetMlsdGpu.java
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4.3. Scribble 涂鸦
+- CPU版本 ControlNetScribbleHedCpu.java,ControlNetScribblePidiNetCpu.java
+- GPU版本 ControlNetScribbleHedGpu.java,ControlNetScribblePidiNetGpu.java
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_scribble
+
+
+
+
+
+#### 4.4. SoftEdge 边缘检测
+- HED Safe
+- PidiNet
+- PidiNet Safe
+- CPU版本 ControlNetSoftEdgeCpu
+- GPU版本 ControlNetSoftEdgeGpu
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 4.5. OpenPose 姿态检测
+- CPU版本 ControlNetPoseCpu.java
+- GPU版本 ControlNetPoseGpu.java
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 4.6. Segmentation 语义分割
+- CPU版本 ControlNetSegCpu.java
+- GPU版本 ControlNetSegGpu.java
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 4.7. Depth 深度检测
+- Midas
+- CPU版本 ControlNetDepthDptCpu.java
+- GPU版本 ControlNetDepthDptGpu.java
+- DPT
+- CPU版本 ControlNetDepthMidasCpu.java
+- GPU版本 ControlNetDepthMidasGpu.java
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 4.8. Normal Map 法线贴图
+- CPU版本 ControlNetNormalbaeCpu.java
+- GPU版本 ControlNetNormalbaeGpu.java
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 4.9. Lineart 生成线稿
+- CPU版本 ControlNetLineArtCpu.java
+- GPU版本 ControlNetLineArtGpu.java
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 4.10. Lineart Anime 生成线稿
+- CPU版本 ControlNetLineArtAnimeCpu.java
+- GPU版本 ControlNetLineArtAnimeGpu.java
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 4.11. Content Shuffle
+- CPU版本 ControlNetShuffleCpu.java
+- GPU版本 ControlNetShuffleGpu.java
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/java_stable_diffusion_sdks/lora_sdk/README.md b/7_aigc/java_stable_diffusion_sdks/lora_sdk/README.md
new file mode 100644
index 00000000..65bb713d
--- /dev/null
+++ b/7_aigc/java_stable_diffusion_sdks/lora_sdk/README.md
@@ -0,0 +1,165 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+#### 图像生成提示词参考
+- https://arthub.ai/
+
+#### 作品欣赏
+
+
+
+
+#### 测试环境和数据
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. 文生图:输入提示词(仅支持英文),生成图片(仅支持英文)
+- GPU版本 StableDiffusionGPU.java
+- CPU版本 StableDiffusionCPU.java
+#### 文生图测试
+- 提示词 prompt: a photo of an astronaut riding a horse on mars
+- 生成图片效果:
+
+
+
+
+### 2. 图生图:根据图片及提示词(仅支持英文)生成图片
+- CPU版本 Image2ImageCpu.java
+- GPU版本 Image2ImageGpu.java
+
+### 3. Lora 文生图
+- CPU版本 LoraTxt2ImageCpu.java
+
+### 4. Controlnet 图像生成
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 4.1. Canny 边缘检测
+- CPU版本 ControlNetCannyCpu.java
+- GPU版本 ControlNetCannyGpu.java
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 4.2. MLSD 线条检测
+- CPU版本 ControlNetMlsdCpu.java
+- GPU版本 ControlNetMlsdGpu.java
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4.3. Scribble 涂鸦
+- CPU版本 ControlNetScribbleHedCpu.java,ControlNetScribblePidiNetCpu.java
+- GPU版本 ControlNetScribbleHedGpu.java,ControlNetScribblePidiNetGpu.java
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_scribble
+
+
+
+
+
+#### 4.4. SoftEdge 边缘检测
+- HED Safe
+- PidiNet
+- PidiNet Safe
+- CPU版本 ControlNetSoftEdgeCpu
+- GPU版本 ControlNetSoftEdgeGpu
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 4.5. OpenPose 姿态检测
+- CPU版本 ControlNetPoseCpu.java
+- GPU版本 ControlNetPoseGpu.java
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 4.6. Segmentation 语义分割
+- CPU版本 ControlNetSegCpu.java
+- GPU版本 ControlNetSegGpu.java
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 4.7. Depth 深度检测
+- Midas
+- CPU版本 ControlNetDepthDptCpu.java
+- GPU版本 ControlNetDepthDptGpu.java
+- DPT
+- CPU版本 ControlNetDepthMidasCpu.java
+- GPU版本 ControlNetDepthMidasGpu.java
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 4.8. Normal Map 法线贴图
+- CPU版本 ControlNetNormalbaeCpu.java
+- GPU版本 ControlNetNormalbaeGpu.java
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 4.9. Lineart 生成线稿
+- CPU版本 ControlNetLineArtCpu.java
+- GPU版本 ControlNetLineArtGpu.java
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 4.10. Lineart Anime 生成线稿
+- CPU版本 ControlNetLineArtAnimeCpu.java
+- GPU版本 ControlNetLineArtAnimeGpu.java
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 4.11. Content Shuffle
+- CPU版本 ControlNetShuffleCpu.java
+- GPU版本 ControlNetShuffleGpu.java
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/7_aigc/java_stable_diffusion_sdks/txt2image_sdk/README.md b/7_aigc/java_stable_diffusion_sdks/txt2image_sdk/README.md
new file mode 100644
index 00000000..65bb713d
--- /dev/null
+++ b/7_aigc/java_stable_diffusion_sdks/txt2image_sdk/README.md
@@ -0,0 +1,165 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+#### 图像生成提示词参考
+- https://arthub.ai/
+
+#### 作品欣赏
+
+
+
+
+#### 测试环境和数据
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 1. 文生图:输入提示词(仅支持英文),生成图片(仅支持英文)
+- GPU版本 StableDiffusionGPU.java
+- CPU版本 StableDiffusionCPU.java
+#### 文生图测试
+- 提示词 prompt: a photo of an astronaut riding a horse on mars
+- 生成图片效果:
+
+
+
+
+### 2. 图生图:根据图片及提示词(仅支持英文)生成图片
+- CPU版本 Image2ImageCpu.java
+- GPU版本 Image2ImageGpu.java
+
+### 3. Lora 文生图
+- CPU版本 LoraTxt2ImageCpu.java
+
+### 4. Controlnet 图像生成
+- 显卡CUDA:11.7版本
+- 参考测试数据:分辨率 512*512 25步 CPU(i5处理器) 5分钟。 3060显卡20秒。
+
+#### 4.1. Canny 边缘检测
+- CPU版本 ControlNetCannyCpu.java
+- GPU版本 ControlNetCannyGpu.java
+- Canny 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。
+- 对应ControlNet模型: control_canny
+
+
+
+
+
+#### 4.2. MLSD 线条检测
+- CPU版本 ControlNetMlsdCpu.java
+- GPU版本 ControlNetMlsdGpu.java
+- MLSD 线条检测用于生成房间、直线条的建筑场景效果比较好。
+- 对应ControlNet模型: control_mlsd
+
+
+
+
+
+#### 4.3. Scribble 涂鸦
+- CPU版本 ControlNetScribbleHedCpu.java,ControlNetScribblePidiNetCpu.java
+- GPU版本 ControlNetScribbleHedGpu.java,ControlNetScribblePidiNetGpu.java
+- 不用自己画,图片自动生成类似涂鸦效果的草图线条。
+- 对应ControlNet模型: control_scribble
+
+
+
+
+
+#### 4.4. SoftEdge 边缘检测
+- HED Safe
+- PidiNet
+- PidiNet Safe
+- CPU版本 ControlNetSoftEdgeCpu
+- GPU版本 ControlNetSoftEdgeGpu
+- SoftEdge 边缘检测可保留更多柔和的边缘细节,类似手绘效果。
+- 对应ControlNet模型: control_softedge。
+
+
+
+
+
+#### 4.5. OpenPose 姿态检测
+- CPU版本 ControlNetPoseCpu.java
+- GPU版本 ControlNetPoseGpu.java
+- OpenPose 姿态检测可生成图像中角色动作姿态的骨架图(含脸部特征以及手部骨架检测),这个骨架图可用于控制生成角色的姿态动作。
+- 对应ControlNet模型: control_openpose。
+
+
+
+
+
+#### 4.6. Segmentation 语义分割
+- CPU版本 ControlNetSegCpu.java
+- GPU版本 ControlNetSegGpu.java
+- 语义分割可多通道应用,原理是用颜色把不同类型的对象分割开,让AI能正确识别对象类型和需求生成的区界。
+- 对应ControlNet模型: control_seg。
+
+
+
+
+
+#### 4.7. Depth 深度检测
+- Midas
+- CPU版本 ControlNetDepthDptCpu.java
+- GPU版本 ControlNetDepthDptGpu.java
+- DPT
+- CPU版本 ControlNetDepthMidasCpu.java
+- GPU版本 ControlNetDepthMidasGpu.java
+- 通过提取原始图片中的深度信息,生成具有原图同样深度结构的深度图,越白的越靠前,越黑的越靠后。
+- 对应ControlNet模型: control_depth。
+
+
+
+
+
+#### 4.8. Normal Map 法线贴图
+- CPU版本 ControlNetNormalbaeCpu.java
+- GPU版本 ControlNetNormalbaeGpu.java
+- 根据图片生成法线贴图,适合CG或游戏美术师。法线贴图能根据原始素材生成一张记录凹凸信息的法线贴图,便于AI给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
+- 对应ControlNet模型: control_normal。
+
+
+
+
+
+#### 4.9. Lineart 生成线稿
+- CPU版本 ControlNetLineArtCpu.java
+- GPU版本 ControlNetLineArtGpu.java
+- Lineart 边缘检测预处理器可很好识别出图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart。
+
+
+
+
+
+#### 4.10. Lineart Anime 生成线稿
+- CPU版本 ControlNetLineArtAnimeCpu.java
+- GPU版本 ControlNetLineArtAnimeGpu.java
+- Lineart Anime 边缘检测预处理器可很好识别出卡通图像内各对象的边缘轮廓,用于生成线稿。
+- 对应ControlNet模型: control_lineart_anime。
+
+
+
+
+
+#### 4.11. Content Shuffle
+- CPU版本 ControlNetShuffleCpu.java
+- GPU版本 ControlNetShuffleGpu.java
+- Content Shuffle 图片内容变换位置,打乱次序,配合模型 control_v11e_sd15_shuffle 使用。
+- 对应ControlNet模型: control_shuffle。
+
+
+
+
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
\ No newline at end of file
diff --git a/8_desktop_app/desktop_app_llm/README.md b/8_desktop_app/desktop_app_llm/README.md
new file mode 100644
index 00000000..dfec793e
--- /dev/null
+++ b/8_desktop_app/desktop_app_llm/README.md
@@ -0,0 +1,132 @@
+
+### 大模型桌面离线版App
+#### 主要特性
+- 支持中/英文
+- 模型支持chatglm2,baichuan2,llama2,alpaca2等
+- 支持4位,8位量化,16位半精度模型。
+- 支持windows及mac系统
+- 支持CPU,GPU
+
+
+#### 功能介绍
+- 选择模型,并运行
+
+
+
+
+- 创建新的对话,与模型聊天
+
+
+
+
+#### 项目构建
+```text
+# 环境搭建
+npm install
+# 开发环境运行
+npm run dev
+# mac生产环境发布
+npm run build:mac
+# windows生产环境发布
+npm run build:win
+# linux生产环境发布
+npm run build:linux
+```
+
+#### 调用llama的关键代码(根据环境修改命令)
+```text
+ let bin_path = process.env.PY_SCRIPT || "../llama_bin/main"
+
+ let proc = require('child_process').spawn(bin_path, ['-m', model_path, '-n', "256", '--repeat_penalty', "1.0", '-r', "User:", '-f', "/Users/calvin/Downloads/llm/llama_bin/chat-with-bob.txt", '-i']);
+```
+
+
+#### Llama.cpp项目构建
+```text
+下载代码:
+git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp
+
+
+GPU Build:
+复制所有文件:
+From:
+C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\extras\visual_studio_integration\MSBuildExtensions
+To:
+C:\Program Files (x86)\Microsoft Visual Studio\2019\BuildTools\MSBuild\Microsoft\VC\v160\BuildCustomizations
+
+cd D:\githubs\llama.cpp\
+mkdir build
+cd build
+cmake -DLLAMA_CUBLAS=ON -DBUILD_SHARED_LIBS=ON ..
+cmake --build . --config Release
+
+CPU Build:
+cd D:\githubs\llama.cpp\
+mkdir build2
+cd build2
+cmake -DLLAMA_CUBLAS=OFF -DBUILD_SHARED_LIBS=ON ..
+cmake --build . --config Release
+
+```
+
+#### Llama.cpp模型转换参考例子
+```text
+# install Python dependencies
+python3 -m pip install -r requirements.txt
+
+模型量化:
+python3 convert.py /root/autodl-tmp/Chinese-LLaMA-2-7B/ --outfile models/llama2_7b_f16.gguf --outtype f16
+
+ ./quantize ./models/llama2_7b_f16.gguf ./models/llama2_7b_q4_0.bin q4_0
+
+Linux 运行:
+cd /root/autodl-tmp/llama.cpp
+./main -m ./models/llama2_7b_q4_0.bin -p "古希腊历史简介"
+
+Mac 运行:
+cd /Users/calvin/aias_projects/llama.cpp/
+./build/bin/main -m /Users/calvin/Downloads/llama2_7b_q4_0.bin -p "古希腊历史简介"
+
+交互模式运行:(-i flag)
+./build/bin/main -m /Users/calvin/Downloads/llama2_7b_q4_0.bin -i
+
+```
+
+
+#### windows环境参考命令配置
+```text
+ // let jar_path = process.env.PY_SCRIPT;
+ let jar_path = "D:\\easy_AI_apps\\3_ocr\\backends_ocr\\ocr_sdk\\target\\ocr-sdk-0.20.0.jar";
+
+ if(jar_path && (fs.existsSync(jar_path))){
+ proc = require('child_process').spawn('java' , ['-Dfile.encoding=utf-8', '-jar' , jar_path , '-i' , input_path , '-o' , out_path ]);
+ }
+ else{
+ const path = require('path');
+ let java_path = path.join(path.dirname(__dirname), 'core','jdk-11.0.16.1','bin','java.exe');
+ let jar_path = path.join(path.dirname(__dirname), 'core' , 'ocr-sdk-0.20.0.jar' );
+ // let proc = require('child_process').spawn( bin_path , ['-i' , input_path , '-o' , out_path ]);
+ proc = require('child_process').spawn(java_path, ['-Dfile.encoding=utf-8', '-jar' , jar_path , '-i' , input_path , '-o' , out_path ]);
+ }
+
+```
+
+
+#### windows环境进程无法正常关闭问题
+```text
+app.on('window-all-closed', () => {
+ require('child_process').exec('taskkill /F /IM electron.exe /T')
+ require('child_process').exec('taskkill /F /IM 文字识别.exe /T')
+ // console.log('window-all-closed')
+ // if(java_process){
+ // console.log('kill java process')
+ // is_app_closing = true;
+ // java_process.kill('SIGKILL')
+ // // process.exit(java_process.pid)
+ // app.quit()
+ // // app.exit();
+ // }
+
+})
+
+```
\ No newline at end of file
diff --git a/8_desktop_app/desktop_app_ocr/README.md b/8_desktop_app/desktop_app_ocr/README.md
new file mode 100644
index 00000000..da203540
--- /dev/null
+++ b/8_desktop_app/desktop_app_ocr/README.md
@@ -0,0 +1,143 @@
+# OCR 文字识别桌面app
+## 介绍
+使用Electron构建UI界面,ocr识别使用paddle开源ocr模型,模型推理框架使用amazon djl推理引擎。
+
+### 功能清单
+- 图片文字识别
+- 支持windows, linux, mac 一键安装
+
+

+
+
+
+## 项目配置
+### 1. OCR SDK
+### 1.1. 更新模型路径(替换成你的本地路径,或者参考其它的模型加载方式)
+```
+ String detModelUri ="E:\\desktop_app\\ocr\\models\\ch_PP-OCRv3_det_infer_onnx.zip";
+ String recModelUri ="E:\\desktop_app\\ocr\\models\\ch_PP-OCRv3_rec_infer_onnx.zip";
+```
+
+### 1.2. java 命令行调试
+```
+java -Dfile.encoding=utf-8 -jar ocr-sdk-0.22.1.jar -i "E:\\Data_OCR\\ticket_new.png" -o "E:\\Data_OCR\\"
+```
+
+### 1.3. 如何通过url在线加载模型?
+```
+# 文档:
+http://aias.top/AIAS/guides/load_model.html
+
+# 使用 optModelUrls 在线加载url模型
+ Criteria
criteria =
+ Criteria.builder()
+ .optEngine("OnnxRuntime")
+ .optModelName("inference")
+ .setTypes(Image.class, NDList.class)
+ .optModelUrls("https://aias-home.oss-cn-beijing.aliyuncs.com/models/ocr_models/ch_PP-OCRv3_det_infer_onnx.zip")
+ .optTranslator(new OCRDetectionTranslator(new ConcurrentHashMap()))
+ .optProgress(new ProgressBar())
+ .build();
+
+```
+
+
+### 2. OCR Electron 前端App
+
+### 2.1. 项目初始化
+```
+npm install
+
+```
+
+### 2.2. 开发环境
+```
+ npm run electron:serve
+```
+
+### 2.3. 生产环境发布
+```
+npm run electron:build
+```
+
+### 2.4. 如何配置启动java的命令行?
+```
+native_functions.js:
+
+ //1. 开发环境:配置 jar_path
+ let jar_path = "D:\\easy_AI_apps\\3_ocr\\backends_ocr\\ocr_sdk\\target\\ocr-sdk-0.22.1.jar";
+
+ if(jar_path && (fs.existsSync(jar_path))){
+ proc = require('child_process').spawn('java' , ['-Dfile.encoding=utf-8', '-jar' , jar_path , '-i' , input_path , '-o' , out_path ]);
+ }
+
+ //2. 生产环境:配置 java_path, jar_path, 如果环境中有java可以不使用 spawn(java_path...,直接使用 spawn('java' ....
+ else{
+ const path = require('path');
+ let java_path = path.join(path.dirname(__dirname), 'core','jdk-11.0.16.1','bin','java.exe');
+ let jar_path = path.join(path.dirname(__dirname), 'core' , 'ocr-sdk-0.22.1.jar' );
+ // let proc = require('child_process').spawn( bin_path , ['-i' , input_path , '-o' , out_path ]);
+ proc = require('child_process').spawn(java_path, ['-Dfile.encoding=utf-8', '-jar' , jar_path , '-i' , input_path , '-o' , out_path ]);
+ }
+```
+
+### 2.5. jar包该放在哪里?- 更新 native_functions.js
+```
+native_functions.js:
+
+ //1. 开发环境:调试的时候,直接hardcode jar的路径
+ let jar_path = "F:\dev\easy_AI_apps_win\3_ocr_desktop_app\backends_ocr\\ocr_sdk\\target\\ocr-sdk-0.20.0.jar";
+
+ if(jar_path && (fs.existsSync(jar_path))){
+ proc = require('child_process').spawn('java' , ['-Dfile.encoding=utf-8', '-jar' , jar_path , '-i' , input_path , '-o' , out_path ]);
+ }
+
+ //2. 生产环境:自动根据 vue.config.js里面的配置复制打包
+ else{
+ const path = require('path');
+ let java_path = path.join(path.dirname(__dirname), 'core','jdk-11.0.16.1','bin','java.exe');
+ let jar_path = path.join(path.dirname(__dirname), 'core' , 'ocr-sdk-0.20.0.jar' );
+ // let proc = require('child_process').spawn( bin_path , ['-i' , input_path , '-o' , out_path ]);
+ proc = require('child_process').spawn(java_path, ['-Dfile.encoding=utf-8', '-jar' , jar_path , '-i' , input_path , '-o' , out_path ]);
+ }
+```
+
+### 2.6. vue.config.js 如何配置?
+```
+1. mac, linux 环境配置: // "from": "../backends/ocr/"
+2. windows环境配置: "from": "E:\\ocr\\"
+------------------
+E:\ocr 的目录
+2023/01/11 19:35 .
+2023/08/15 19:45 ..
+2023/01/11 19:29 jdk-11.0.16.1
+2023/01/11 19:35 977,666,281 ocr-sdk-0.20.0.jar
+------------------
+
+ builderOptions: {
+ productName:"文字识别",//项目名 这也是生成的exe文件的前缀名
+ appId: 'top.aias.ocr',
+ copyright:"All rights reserved by aias.top",//版权 信息
+ afterSign: "./afterSignHook.js",
+ "extraResources": [{
+ "from": "E:\\ocr\\" , // 将需要打包的文件,放在from指定的目录下
+ "to": "core", //安装时候复制文件的目标目录
+ "filter": [
+ "**/*"
+ ]
+ }],
+```
+
+### 2.7. 如何启用web开发者工具?- background.js
+```
+ if (process.env.WEBPACK_DEV_SERVER_URL) {
+ // Load the url of the dev server if in development mode
+ await win.loadURL(process.env.WEBPACK_DEV_SERVER_URL)
+
+ // 打开下面这行的注释
+ // if (!process.env.IS_TEST) win.webContents.openDevTools()
+ } else {
+ createProtocol('app')
+ // Load the index.html when not in development
+ win.loadURL('app://./index.html')
+```
\ No newline at end of file
diff --git a/8_desktop_app/desktop_app_ocr/ocr_sdk/README.md b/8_desktop_app/desktop_app_ocr/ocr_sdk/README.md
new file mode 100644
index 00000000..59268e29
--- /dev/null
+++ b/8_desktop_app/desktop_app_ocr/ocr_sdk/README.md
@@ -0,0 +1,68 @@
+### 官网:
+[官网链接](https://www.aias.top/)
+
+#### 下载模型,放置于models目录
+- 链接:https://pan.baidu.com/s/1GSdLe3jxPzzn-5GzUfze9A?pwd=2g6f
+
+
+## 文字识别(OCR)工具箱
+文字识别(OCR)目前在多个行业中得到了广泛应用,比如金融行业的单据识别输入,餐饮行业中的发票识别,
+交通领域的车票识别,企业中各种表单识别,以及日常工作生活中常用的身份证,驾驶证,护照识别等等。
+OCR(文字识别)是目前常用的一种AI能力。
+
+### OCR工具箱功能:
+#### 文字识别SDK (原生支持旋转倾斜文本, 如果需要,图像预处理SDK可以作为辅助)
+##### 1. 文本检测 - OcrV3DetExample
+- 中文文本检测
+- 英文文本检测
+- 多语言文本检测
+
+
+##### 2. 文本识别 - OcrV3RecExample
+支持的语言模型:
+- 中文简体
+- 中文繁体
+- 英文
+- 韩语
+- 日语
+- 阿拉伯
+- 梵文
+- 泰米尔语
+- 泰卢固语
+- 卡纳达文
+- 斯拉夫
+
+
+
+
+
+
+##### 3. 多线程文本识别 - OcrV3MultiThreadRecExample
+CPU:2.3 GHz 四核 Intel Core i5
+同样图片单线程运行时间:1172 ms
+多线程运行时间:707 ms
+图片检测框较多时,多线程可以显著提升识别速度。
+
+
+### 开源算法
+#### 1. sdk使用的开源算法
+- [PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)
+
+#### 2. 模型如何导出 ?
+(readme.md 里提供了推理模型的下载链接)
+- [export_model](https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.5/tools/export_model.py)
+- [how_to_create_paddlepaddle_model](http://docs.djl.ai/docs/paddlepaddle/how_to_create_paddlepaddle_model_zh.html)
+
+
+
+#### 帮助文档:
+- https://aias.top/guides.html
+- 1.性能优化常见问题:
+- https://aias.top/AIAS/guides/performance.html
+- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/engine_config.html
+- 3.模型加载方式(在线自动加载,及本地配置):
+- https://aias.top/AIAS/guides/load_model.html
+- 4.Windows环境常见问题:
+- https://aias.top/AIAS/guides/windows.html
+
diff --git a/8_desktop_app/desktop_app_upscale/README.md b/8_desktop_app/desktop_app_upscale/README.md
new file mode 100644
index 00000000..d4cf9bbe
--- /dev/null
+++ b/8_desktop_app/desktop_app_upscale/README.md
@@ -0,0 +1,152 @@
+# 图像高清放大桌面App
+## 介绍
+使用Electron构建UI界面,使用realesrgan模型,模型推理框架使用vulkan。
+
+### 功能清单
+- 单张图片分辨率放大
+- 批量图片分辨率放大
+- 支持 windows, macos, ubuntu
+
+

+
 +
+  +
+  +
+ 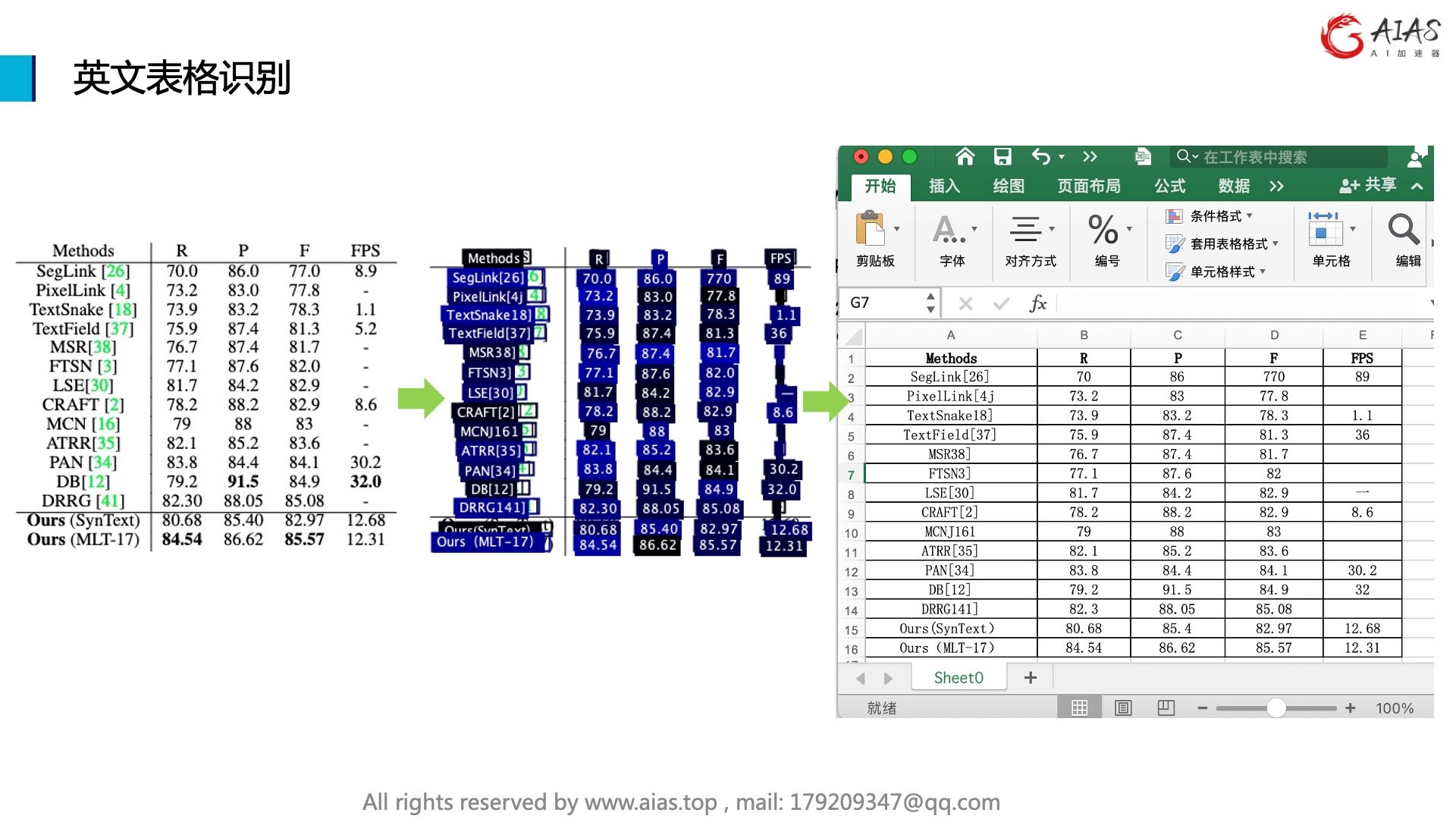 +
+  +
+  +
+ 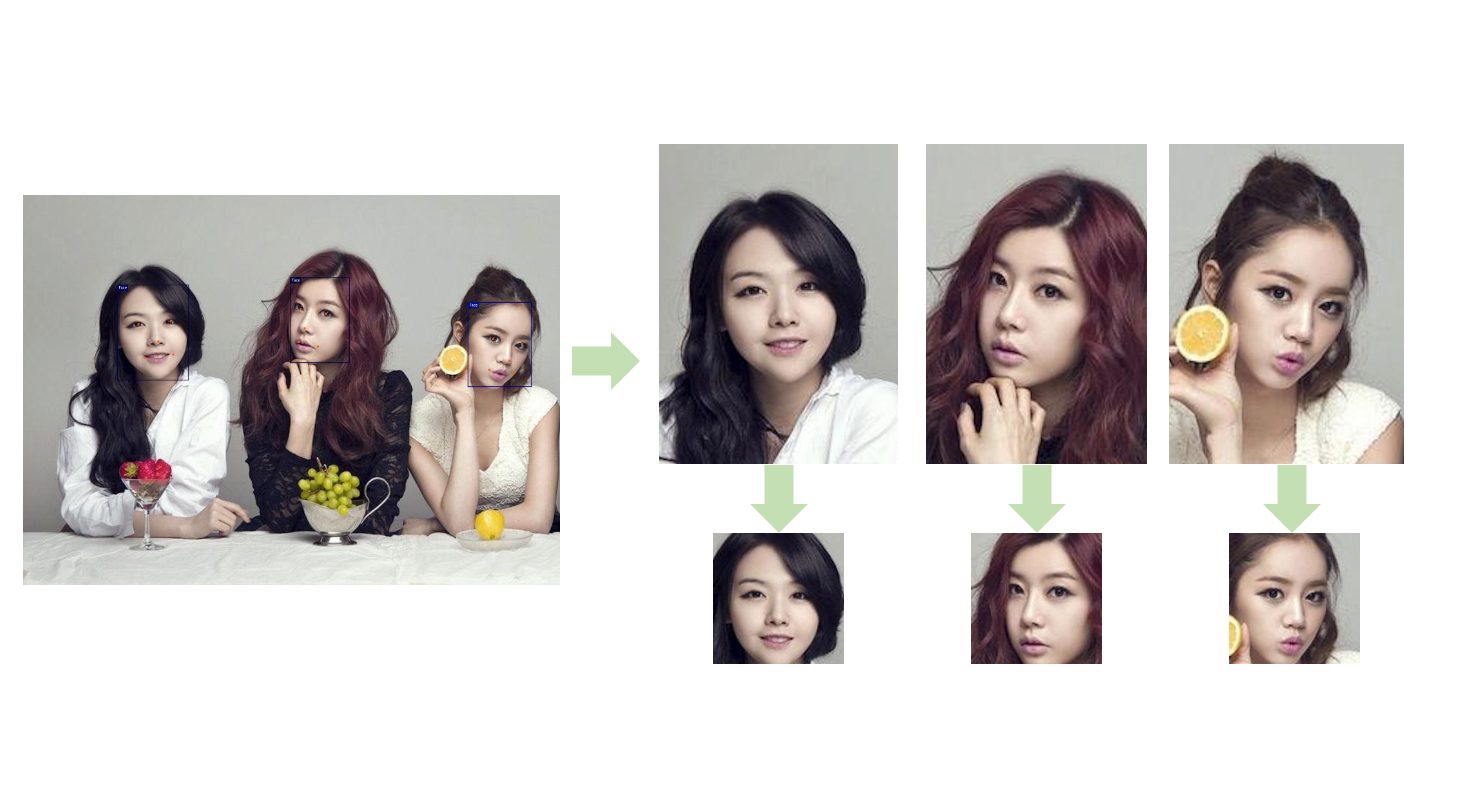 +
+  +
+  +
+ 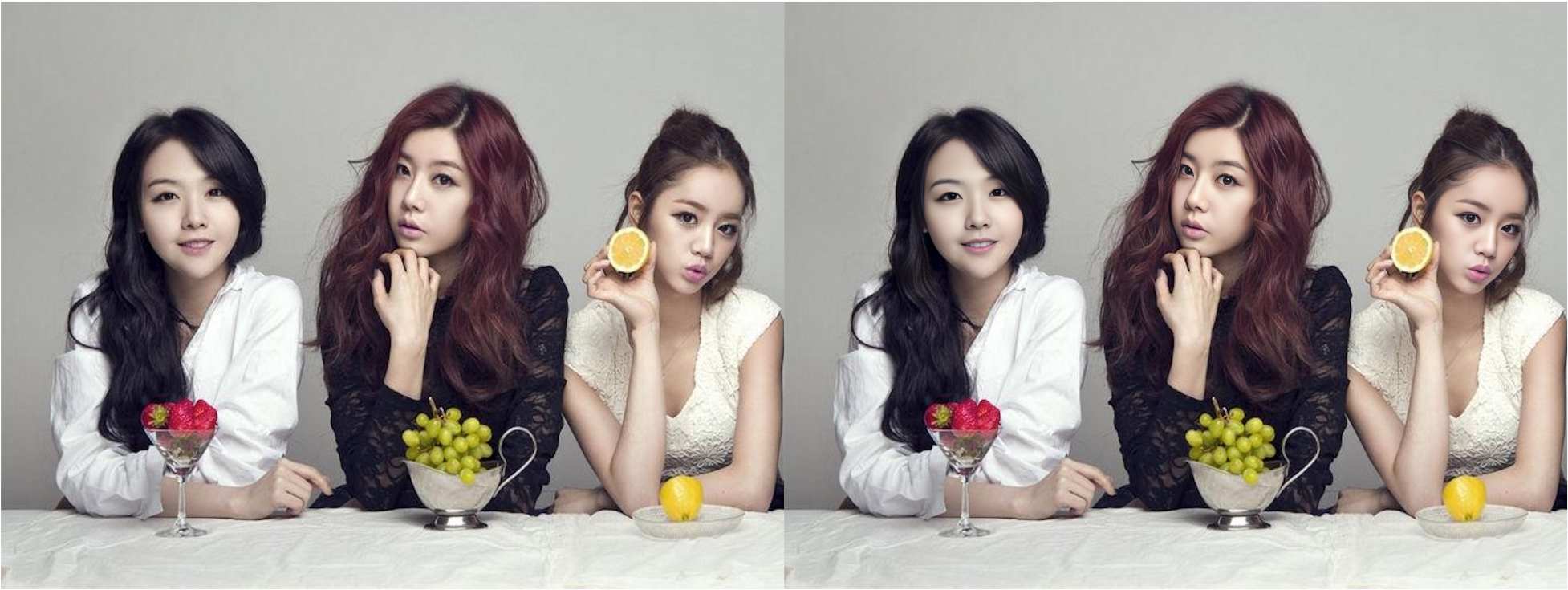 +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+ 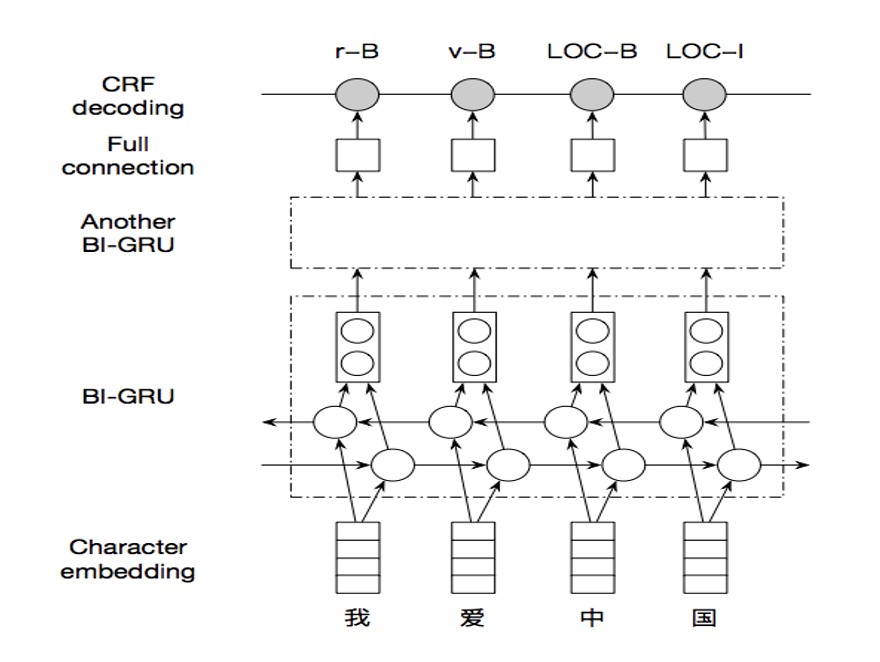 +
+