LoHoRavens: A Long-Horizon Language-Conditioned Benchmark for Robotic Tabletop Manipulation
+LoHoRavens: A Long-Horizon Language-Conditioned Benchmark for Robotic Tabletop Rearrangement
+ Haihui Ye3,
+ Lütfi Kerem Şenel1,4, + Zhenshan Bing3, +
+ + Barbara Plank1,4, + Hinrich Schütze1,4 - @@ -291,62 +306,6 @@
We learn one multi-task policy for 9 real-world tasks including folding cloths, sweeping beans etc. with just 179 image-action training pairs.
--> -Abstract
-- The convergence of embodied agents and large language models (LLMs) has brought significant advancements to embodied instruction following. - Particularly, the strong reasoning capabilities of LLMs make it possible for robots to perform long-horizon tasks without expensive annotated demonstrations. - However, public benchmarks for testing the long-horizon reasoning capabilities of language-conditioned robots in various scenarios are still missing. - To fill this gap, this work focuses on the tabletop - manipulation task and releases a simulation benchmark, - LoHoRavens, which covers various long-horizon - reasoning aspects spanning color, size, space, arithmetics - and reference. - Furthermore, there is a key modality bridging problem for - long-horizon manipulation tasks with LLMs: how to - incorporate the observation feedback during robot execution - for the LLM's closed-loop planning, which is however less studied by prior work. - We investigate two methods of bridging the modality gap: caption generation and learnable interface for incorporating explicit and implicit observation feedback to the LLM, respectively. - These methods serve as the two baselines for our proposed benchmark. - Experiments show that both methods struggle to solve some tasks, indicating long-horizon manipulation tasks are still challenging for current popular models. - We expect the proposed public benchmark and baselines can help the community develop better models for long-horizon tabletop manipulation tasks. -
- -
-
-
- Video
-Video
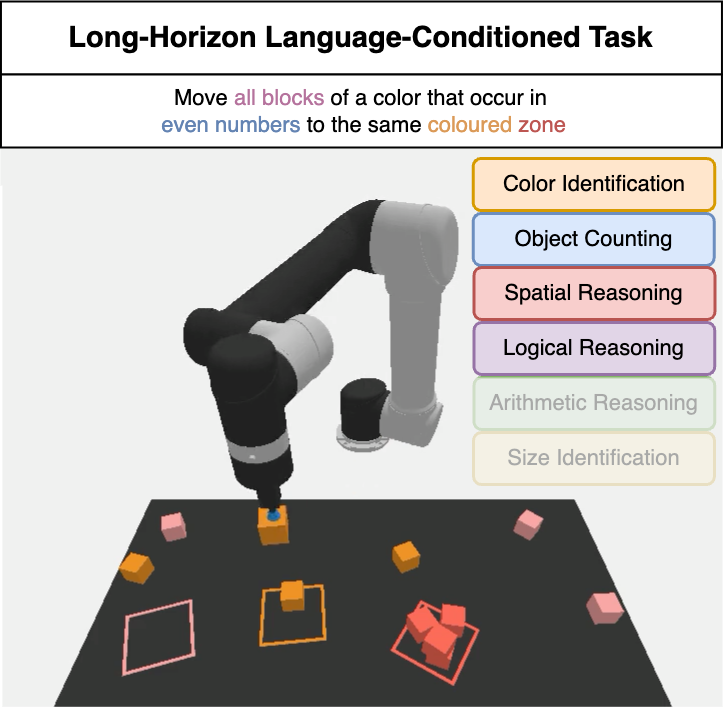
LoHoRavens Benchmark
+LoHoRavens Benchmark Examples
LoHoRavens Benchmark
We learn one multi-task policy for 9 real-world tasks including folding cloths, sweeping beans etc. with just 179 image-action training pairs. --> -Baselines
-Baselines
+ -Explicit feedback: Caption generation
- -
- Imitation Learning based model (IL)
+- Inner Monologue demonstrated that human-provided language feedback can significantly improve high-level instruction completion on robotic manipulation tasks. - But human-written language feedback is too expensive to scale. We therefore explore a caption generation based model as an automatic way to generate language feedback without training. + We use the same architecture and training recipe as CLIPort for the imitation learning baseline. + Using multi-task training, the CLIPort model is trained with the train sets of all 20 seen tasks along with the three pick-and-place primitives for 100K steps. + Because the vanilla CLIPort does not know when to stop execution, following Inner Monologue and CaP, we use an oracle termination variant that uses the oracle information from the simulator to detect the success rate and stop the execution process.
++
+
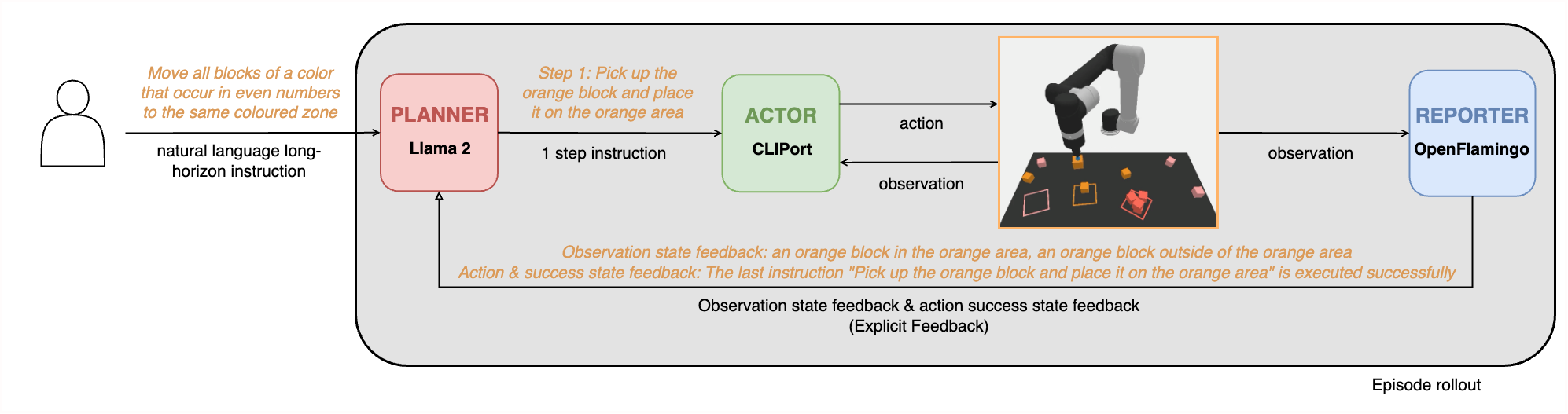
Planner-Actor-Reporter based model (PAR)
+
+ - As shown in the above figure, we use Llama 2 and the trained pick-and-place CLIPort primitive as the Planner and Actor, respectively. - For the Reporter, - we use the VLM OpenFlamingo with few-shot prompting to generate the following two types of feedback: - Observation state feedback - which is the information about the objects on the table and their potential changes, - and - Action success state feedback - which is the description whether the last instruction is executed successfully or not. + The Planner-Actor-Reporter paradigm is frequently used in robotics. + Usually, LLMs serve as the Planner due to their impressive planning and reasoning capabilities, + and humans or VLMs play the role of Reporter to provide necessary language feedback for the Planner's planning. + The Actor is the agent that interacts with the environment.
- When a step's action has executed, there will be a top-down RGB image rendered by the simulator. - The VLM as the Reporter module will generate the caption feedback based on the current image or the whole image history. - This caption feedback is sent to the LLM for its next-step planning. - The Planner-Actor-Reporter closed-loop process will be - iteratively executed until the high-level goal is achieved - or the maximum number of trial steps has been exceeded. + As shown in the above figure, we use Llama 3 8B and the trained pick-and-place CLIPort primitive as the Planner and Actor, respectively. + For the Reporter, we use the VLM CogVLM2. + Theoretically, any type of feedback from the environment + and the robot can be considered to inform the LLM planner + as long as it can be stated verbally. However, considering the + LoHoRavens simulated environment and the VLMs we use, + we just prompt the VLMs to generate the following types of + feedback:
+ +-
+
- Observation state feedback: + Besides the human instruction at the beginning, the Planner needs to have the + information about the objects on the table for the planning. + Furthermore, if the states of the objects change, the VLM + Reporter should describe the changes to the LLM Planner. +
- Action success state feedback: + The robot Actor + may fail to complete the instruction given by the LLM + Planner. This kind of success state information (or rather + failure information) should be conveyed to the Planner. The + VLM Reporter will indicate in its description whether the + last instruction is executed successfully or not. +
Explicit feedback: Caption generation
- -
Implicit feedback: Learnable interface
-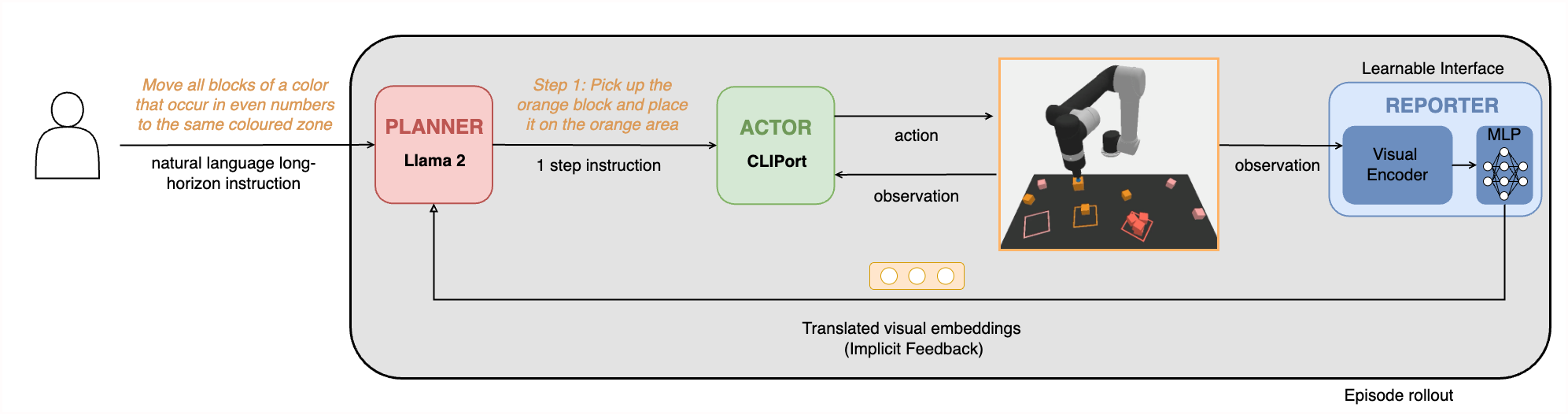 -
- - Explicitly converting an image to language captions - is straightforward and simple. However, - it typically causes information loss and exaggerates bias present in training data. - On the other hand, training an end-to-end multimodal LLM would be too expensive. - Thus another common solution used in many VLMs is to use a learnable interface such as a - projection-based interface or a group of - learnable query tokens to connect - vision and language modalities while freezing parameters of - the LLM and the visual encoder. -
-- We use LLaVA for this second baseline. - LLaVA uses the simple projection-based scheme as the learnable interface between the vision model and the pretrained LLM. - As shown in the above figure, the pretrained CLIP visual encoder ViT-L/14 encodes the observation image to visual embeddings. - A single-layer MLP as the learnable interface then translates the visual embeddings to the LLM's token embedding space. - The LLM will generate the next-step plan conditioned on the language instruction prompts and the translated visual embeddings. - LLaVA uses LLaMA as the LLM. -
-- To fine-tune LLaVA, for each step of the task instances in the train set, we use the oracle program of the simulator to generate the image before the step and the language instruction for the step as the pair of train data. - For the inference process, LLaVA receives the generated - images after each step's execution - (just as the caption generation based model does). - LLaVA then outputs the next-step language instruction to CLIPort for execution. -
- - -More baselines are being added ...
- - -
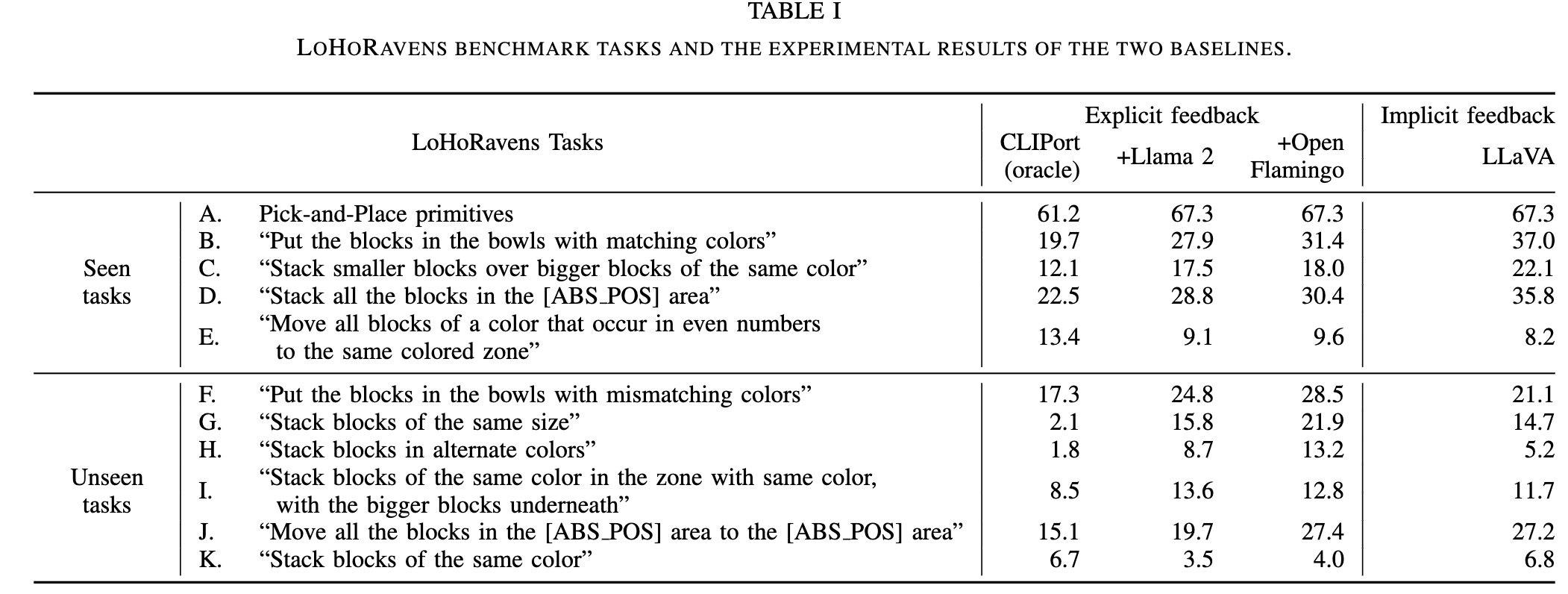
Results
- -
-
-
+
-
-
-
+ 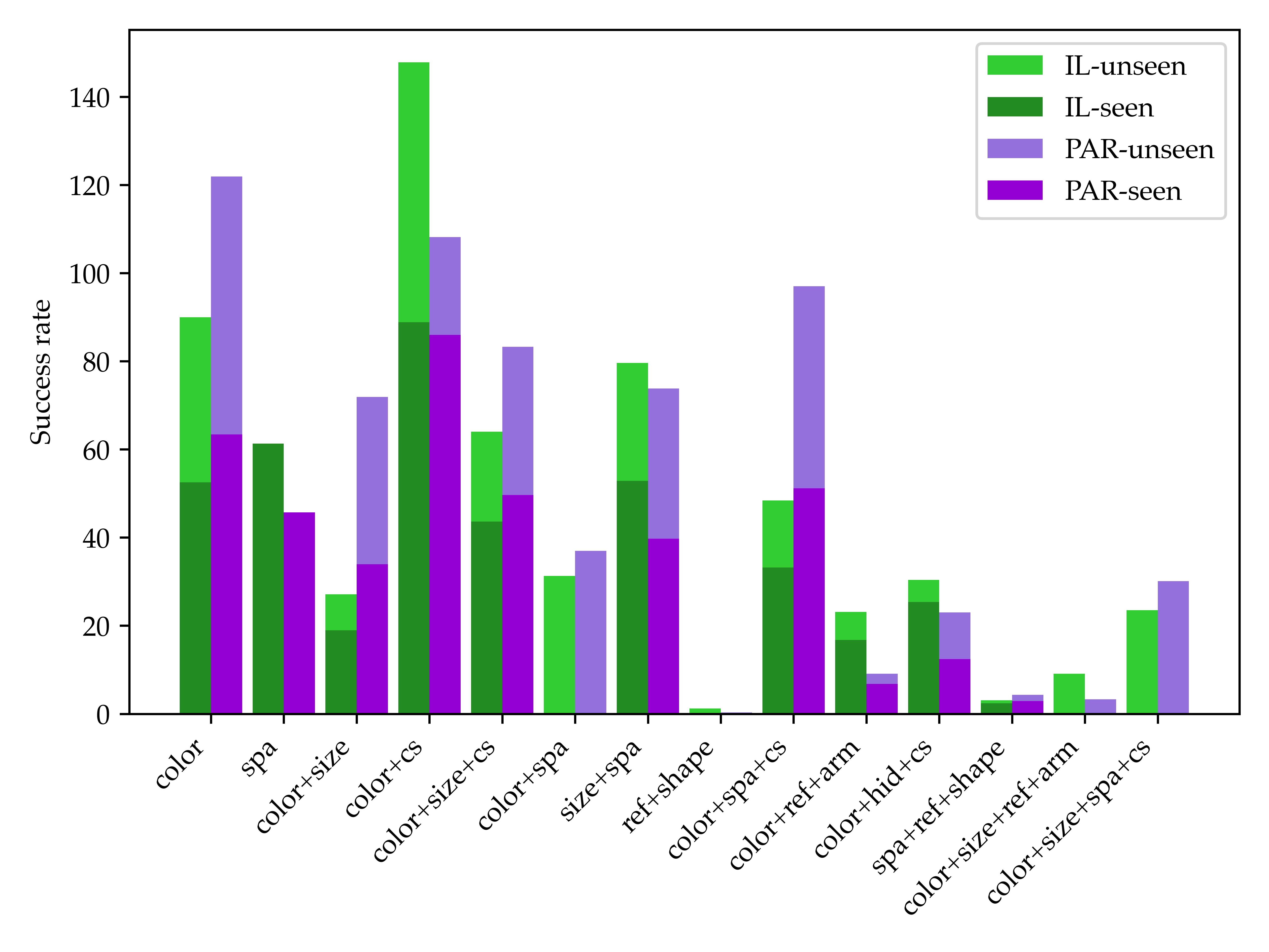 +
+ + As we can see from the above figure, the overall tendency is that the models' performance drops as the number of combinations of reasoning increases. + This observation fits with our intuition that + the more reasoning capabilities the tasks require, + the harder the tasks become. + But there are still some exceptions violating this rule. + Unexpectedly, the IL baseline performs better on the tasks requiring "color+size" capabilities than on the tasks requiring + "color+size+commonsense" capabilities. + We speculate the reason is that "color+size+commonsense" tasks typically use commonsense to filter the objects needed to manipulate, thus this kind of task usually requires fewer steps to complete. +
+ ++ Another interesting finding is that the two baselines perform differently regarding different reasoning capabilities. + On the seen tasks requiring spatial reasoning capability, + the IL model usually performs better. + It is probably because current LLMs and VLMs do not have + good spatial understanding. + In contrast, the PAR model usually outperforms the IL model on tasks requiring commonsense. + Another observation is that the PAR model cannot deal with tasks requiring reference since LLMs cannot indicate the objects accurately if there is more than one object with the same size and color. + This also prevents the PAR model from solving the tasks + requiring arithmetic reasoning since these tasks usually + comprise multiple objects of the same kind. +
++ The experiments also show that some tasks are extremely hard for both models. + For tasks that contain hidden objects, + both models struggle to reason to remove the top object that blocks the bottom target objects. + Moreover, they + are almost completely unable to solve shape construction tasks. + To summarize, LoHoRavens is a good resource to benchmark methods for robotic manipulation. + It is also a challenging benchmark that can facilitate future work on developing more advanced models on long-horizon robotic tasks. +
+ +