-
Notifications
You must be signed in to change notification settings - Fork 95
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
added rough draft of first RNN content
- Loading branch information
1 parent
e00c0b5
commit a94d7f8
Showing
5 changed files
with
891 additions
and
475 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,178 @@ | ||
| { | ||
| "cells": [ | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "# Intro to Recurrent Neural Networks\n", | ||
| "\n", | ||
| "Recurrent Neural Networks (RNN) are another specialization within the neural network family designed to work specifically with sequence data. The most common types of data to use with RNN's are time series data and textual data (natural language, programming languages, log files, and so on).\n", | ||
| "\n", | ||
| "Sequence data, and especially variable length sequence data, presents significant challenges for other models in the neural network family (and many other kinds of models) for a few reasons including:\n", | ||
| "\n", | ||
| "### Most models, ANN's included, require a fixed input size.\n", | ||
| "\n", | ||
| "This is fine for some problems, looking at a fixed-size time window for weather prediction is perfectly reasonable. But it's a non-starter for problems like machine translation where arbitrary text documents (from single sentences to complete books) must be handled for the system to be worth anything. \n", | ||
| "\n", | ||
| "Earlier models working with sequence data often involved a preprocessing step that smashes variable length data into a fixed length feature vector. One of the simplest examples of this tactic is called the \"Bag of Words\" where a textual input is reduced to the number of times any given word appears in that data-point. The result of a \"Bag of Words\" transformation is a vector where each position represents one of the words in the entire corpus vocabulary, the integer value in that position represents how many times that word occurs in the data-point. \n", | ||
| "\n", | ||
| "This enconding for text is problimatic and limiting. For example, \"live to work\" and \"work to live\" will result in the same \"bag of words\" encoding although all English speakers recognize the sentences are opposites of each other. \n", | ||
| "\n", | ||
| "One dimenstional CNN's can be used to solve this problem to some extent, although they are somewhat limited by the kernel size with respect to how far backwards in the sequence they can look at once. \n", | ||
| "\n", | ||
| "### Most models, including ANN's requre a fixed output size.\n", | ||
| "\n", | ||
| "Similar to the above many sequence tasks (such as machine translation) require arbitrary length output, which is a non-starter for both ANNs and CNNs.\n", | ||
| "\n", | ||
| "## RNNs Solve These Problems By Maintaining Internal State\n", | ||
| "\n", | ||
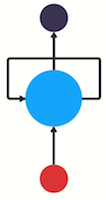
| "The core idea of an RNN makes a lot of people raise their eyebrows at first, but it is actually quite simple. In addition to the weights and biases used in a traditional ANN, the RNN introduces a \"state vector\" which is internal to the recurrent nodes. This is sometimes drawn in a confusing way such as this illustration from [one of the readings](https://towardsdatascience.com/illustrated-guide-to-recurrent-neural-networks-79e5eb8049c9):\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "The idea is that this node is passing some information *to itself* across a series of sequental calls, one for each data point in the sequence (this could be time steps in a time series, words in a sentence, or characters in a string of text). \n", | ||
| "\n", | ||
| "This is true, but I think it's easier to imagine the state vector as a piece of memory internal to the node which is updated (even during inference) for each piece of data in the input sequence:\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "X0 is the first input of the sequence (e.g. first word, first time step, or first character), y0 is the cell's output, and the state vector, like the weights matrix, is internal to the cell. However, unlike the weights, the state vector changes during forward passes instead of just during back-propagation. So, when we move on to the second piece of data in the sequence we have something like this:\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "The forward pass on datapoint X0 modified the internal state vector, so this is often drawn with an arrow connecting the whole cell to itself in a subsequent timestep, such as this drawing, from [another one of the readings](https://karpathy.github.io/2015/05/21/rnn-effectiveness/):\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "The hidden state vector contains all the information that the network has accumulated about the sequence so far. Similar to a markov chain, RNN's implicitly assume that this vector is rich enough to capture all the relevant information about what has been processed earlier in the sequence (for examples, which words have already been seen).\n", | ||
| "\n", | ||
| "The forward pass for a vanilla RNN works like this (assuming an activation function of tanh):\n", | ||
| "\n", | ||
| "```\n", | ||
| "# Hidden state is updated:\n", | ||
| "# W_hh (the weights for the hidden state vector)\n", | ||
| "# W_xh (the weights for x)\n", | ||
| "# self.h (the actual hidden state)\n", | ||
| "self.h = np.tanh(np.dot(self.W_hh, self.h) + np.dot(self.W_xh, x))\n", | ||
| "\n", | ||
| "# Compute the output\n", | ||
| "# self.W_xy (the weights for the output)\n", | ||
| "y = np.dot(self.W_hy, self.h)\n", | ||
| "\n", | ||
| "return y\n", | ||
| "```\n", | ||
| "\n", | ||
| "The output y can be passed to other neural network layers as usual, and the hidden state is carried over across the current sequence (but is reinitialized for each new sequence, usually to zero!) \n", | ||
| "\n", | ||
| "**Note** that there are 3 sets of weights:\n", | ||
| "\n", | ||
| "* One that learns to transform the hidden state each timestep,\n", | ||
| "* One that learns to transform to the X input data at each timestep,\n", | ||
| "* One that learns to create the output based on the hidden state at each timestep.\n", | ||
| "\n", | ||
| "## Backpropagation Over Time\n", | ||
| "\n", | ||
| "To understand how backpropagation works with these models, it's best to think about \"unrolling\" the model as we saw in the diagram above:\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "For each output, we compute a loss and the gradients flow backwards through the entire \"unrolled\" network. This has a few implications:\n", | ||
| "\n", | ||
| "* The shared weight matricies are updated multiple times per backprop step. \n", | ||
| " * This exacerbates the exploding and vanishing gradient problems.\n", | ||
| "* It makes the model memory intensive during training, since the hidden states at each timestep have to be retained during training (but not during inference).\n", | ||
| "* Training is typically slow, since both during the forward passes and backpropagation there are dependencies over time — e.g. you must finish calculating the values for x0 before computing the values for x1, meaning we cannot leverage parallelism and GPU hardware nearly as well as we could with CNNs and ANNs.\n", | ||
| "\n", | ||
| "\n", | ||
| "## Finally, Embedding Layers\n", | ||
| "\n", | ||
| "Embeddings a kind of an alternative to one-hot encoding for categorical data. Their function is simple: Embedding layers act as a lookup table mapping a word from our vocabulary into a dense vector representing that word. \n", | ||
| "\n", | ||
| "These mappings are also learned during the training process, and internally use update rules very similar to a Dense layer. The main difference is that embedding layers map a single integer representing the word to a vector (as opposed to using a vector for the input as a Dense layer expects). This difference saves computational time, but learns through backpropagation just like a Dense layer would. \n", | ||
| "\n", | ||
| "Sometimes we'd use a pre-trained network to create the word embeddings, and sometimes we'll train our own embedding layer as part of the network. \n", | ||
| "\n", | ||
| "Regardless, the result is a lookup that maps words to vectors and (if it works as expected) words that are closely related in the dataset result in vectors that are near each other in vector space. When it REALLY works, these embedding vectors can be thought of as a rich set of features extracted from the word. \n", | ||
| "\n", | ||
| "\n", | ||
| "## Okay, Lets Build our First RNN:" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "code", | ||
| "execution_count": 1, | ||
| "metadata": {}, | ||
| "outputs": [ | ||
| { | ||
| "name": "stdout", | ||
| "output_type": "stream", | ||
| "text": [ | ||
| "Model: \"sequential\"\n", | ||
| "_________________________________________________________________\n", | ||
| "Layer (type) Output Shape Param # \n", | ||
| "=================================================================\n", | ||
| "embedding (Embedding) (None, None, 64) 64000 \n", | ||
| "_________________________________________________________________\n", | ||
| "simple_rnn (SimpleRNN) (None, 128) 24704 \n", | ||
| "_________________________________________________________________\n", | ||
| "dense (Dense) (None, 10) 1290 \n", | ||
| "=================================================================\n", | ||
| "Total params: 89,994\n", | ||
| "Trainable params: 89,994\n", | ||
| "Non-trainable params: 0\n", | ||
| "_________________________________________________________________\n" | ||
| ] | ||
| } | ||
| ], | ||
| "source": [ | ||
| "import numpy as np\n", | ||
| "import tensorflow as tf\n", | ||
| "from tensorflow import keras\n", | ||
| "from tensorflow.keras import layers\n", | ||
| "\n", | ||
| "model = keras.Sequential()\n", | ||
| "# Add an Embedding layer expecting input vocab of size 1000, and\n", | ||
| "# output embedding dimension of size 64.\n", | ||
| "model.add(layers.Embedding(input_dim=1000, output_dim=64))\n", | ||
| "\n", | ||
| "# Add a LSTM layer with 128 internal units.\n", | ||
| "model.add(layers.SimpleRNN(128)) # Default activation is Tanh\n", | ||
| "\n", | ||
| "# Add a Dense layer with 10 units.\n", | ||
| "model.add(layers.Dense(10))\n", | ||
| "\n", | ||
| "model.summary()\n" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "code", | ||
| "execution_count": null, | ||
| "metadata": {}, | ||
| "outputs": [], | ||
| "source": [] | ||
| } | ||
| ], | ||
| "metadata": { | ||
| "kernelspec": { | ||
| "display_name": "Python 3", | ||
| "language": "python", | ||
| "name": "python3" | ||
| }, | ||
| "language_info": { | ||
| "codemirror_mode": { | ||
| "name": "ipython", | ||
| "version": 3 | ||
| }, | ||
| "file_extension": ".py", | ||
| "mimetype": "text/x-python", | ||
| "name": "python", | ||
| "nbconvert_exporter": "python", | ||
| "pygments_lexer": "ipython3", | ||
| "version": "3.8.5" | ||
| } | ||
| }, | ||
| "nbformat": 4, | ||
| "nbformat_minor": 4 | ||
| } |
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.