|
| 1 | +## XCiT: Cross-Covariance Image Transformers ([arxiv](https://arxiv.org/abs/2106.09681)) |
| 2 | + |
| 3 | +## Introduction |
| 4 | + |
| 5 | +Following tremendous success in natural language processing, transformers have recently shown much promise for computer vision. The self-attention operation underlying transformers yields global interactions between all tokens, i.e. words or image patches, and enables flexible modelling of image data beyond the local interactions of convolutions. This flexibility, however, comes with a quadratic complexity in time and memory, hindering application to long sequences and high-resolution images. We propose a *transposed* version of self-attention that operates across feature channels rather than tokens, where the interactions are based on the cross-covariance matrix between keys and queries. The resulting cross-covariance attention (XCA) has linear complexity in the number of tokens, and allows efficient processing of high-resolution images. Our cross-covariance image transformer (XCiT) – built upon XCA – combines the accuracy of conventional transformers with the scalability of convolutional architectures. We validate the effectiveness and generality of XCiT by reporting excellent results on multiple vision benchmarks, includ- ing (self-supervised) image classification on ImageNet-1k, object detection and instance segmentation on COCO, and semantic segmentation on ADE20k. |
| 6 | + |
| 7 | +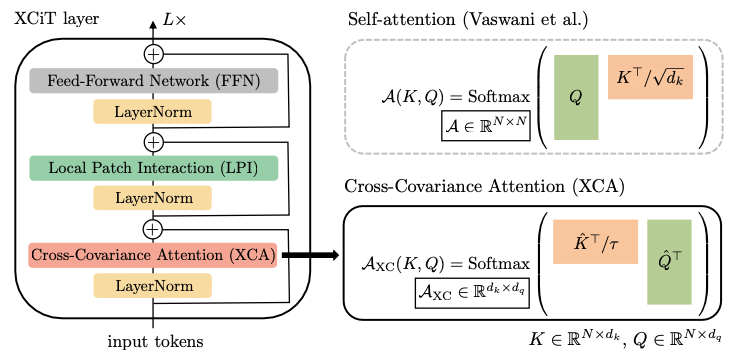 |
| 8 | + |
| 9 | +## Getting Started |
| 10 | + |
| 11 | +#### Train with single gpu |
| 12 | +```bash |
| 13 | +python tools/train.py -c configs/xcit/${XCIT_ARCH}.yaml |
| 14 | +``` |
| 15 | +#### Train with multiple gpus |
| 16 | + |
| 17 | +```bash |
| 18 | +python -m paddle.distributed.launch --gpus="0,1,2,3,4,5,6,7" tools/train.py -c configs/xcit/${XCIT_ARCH}.yaml |
| 19 | +``` |
| 20 | +#### Evaluate |
| 21 | + |
| 22 | +```bash |
| 23 | +python tools/train.py -c configs/xcit/${XCIT_ARCH}.yaml --load ${XCIT_WEGHT_FILE} --evaluate-only |
| 24 | +``` |
| 25 | + |
| 26 | +#### Knowledge distillation |
| 27 | + |
| 28 | +For knowledge distillation, you only need to replace `${XCIT_ARCH}.yaml` to corresponding distillation config file, `${XCIT_ARCH}_dist.yaml`, at above commands. We provide pretrained weights of Teacher model `RegNetY_160`, which can be downloaded [here](https://passl.bj.bcebos.com/vision_transformers/pvt_v2/regnety_160.pdparams). |
| 29 | + |
| 30 | +Checkpoints saved in distillation training include both Teacher's and Student's weights. You can extract the weights of Student by following command. |
| 31 | +```bash |
| 32 | +python tools/extract_weight.py ${DISTILLATION_WEIGHTS_FILE} --prefix Student --remove_prefix --output ${STUDENT_WEIGHTS_FILE} |
| 33 | +``` |
| 34 | + |
| 35 | + |
| 36 | +## Model Zoo |
| 37 | + |
| 38 | +The results are evaluated on ImageNet2012 validation set |
| 39 | +| Arch | Weight | Top-1 Acc | Top-5 Acc | Crop ratio | # Params | |
| 40 | +| ------------------ | ------------------------------------------------------------ | --------- | --------- | ---------- | -------- | |
| 41 | +| xcit_nano_12_p8_224 | [pretrain 1k](https://passl.bj.bcebos.com/vision_transformers/pvt_v2/xcit_nano_12_p8_224.pdparams) | 73.90 | 92.13 | 1.0 | 3.05M | |
| 42 | +| xcit_tiny_12_p8_224 | [pretrain 1k](https://passl.bj.bcebos.com/vision_transformers/pvt_v2/xcit_tiny_12_p8_224.pdparams) | 79.68 | 95.04 | 1.0 | 6.71M | |
| 43 | +| xcit_tiny_24_p8_224 | [pretrain 1k](https://passl.bj.bcebos.com/vision_transformers/pvt_v2/xcit_tiny_24_p8_224.pdparams) | 81.87 | 95.97 | 1.0 | 12.11M | |
| 44 | +| xcit_small_12_p8_224 | [pretrain 1k](https://passl.bj.bcebos.com/vision_transformers/pvt_v2/xcit_small_12_p8_224.pdparams) | 83.36 | 96.51 | 1.0 | 26.21M | |
| 45 | +| xcit_small_24_p8_224 | [pretrain 1k](https://passl.bj.bcebos.com/vision_transformers/pvt_v2/xcit_small_24_p8_224.pdparams) | 83.82 | 96.65 | 1.0 | 47.63M | |
| 46 | +| xcit_medium_24_p8_224 | [pretrain 1k](https://passl.bj.bcebos.com/vision_transformers/pvt_v2/xcit_medium_24_p8_224.pdparams ) | 83.73 | 96.39 | 1.0 | 84.32M | |
| 47 | +| xcit_large_24_p8_224 | [pretrain 1k](https://passl.bj.bcebos.com/vision_transformers/pvt_v2/xcit_large_24_p8_224.pdparams) | 84.42 | 96.65 | 1.0 | 188.93M | |
| 48 | +| xcit_nano_12_p16_224 | [pretrain 1k](https://passl.bj.bcebos.com/vision_transformers/pvt_v2/xcit_nano_12_p16_224.pdparams) | 70.01 | 89.82 | 1.0 | 3.05M | |
| 49 | +| xcit_tiny_12_p16_224 | [pretrain 1k](https://passl.bj.bcebos.com/vision_transformers/pvt_v2/xcit_tiny_12_p16_224.pdparams) | 77.15 | 93.72 | 1.0 | 6.72M | |
| 50 | +| xcit_tiny_24_p16_224 | [pretrain 1k](https://passl.bj.bcebos.com/vision_transformers/pvt_v2/xcit_tiny_24_p16_224.pdparams) | 79.42 | 94.86 | 1.0 | 12.12M | |
| 51 | +| xcit_small_12_p16_224 | [pretrain 1k](https://passl.bj.bcebos.com/vision_transformers/pvt_v2/xcit_small_12_p16_224.pdparams) | 81.89 | 95.83 | 1.0 | 26.25M | |
| 52 | +| xcit_small_24_p16_224 | [pretrain 1k](https://passl.bj.bcebos.com/vision_transformers/pvt_v2/xcit_small_24_p16_224.pdparams) | 82.51 | 95.97 | 1.0 | 47.67M | |
| 53 | +| xcit_medium_24_p16_224 | [pretrain 1k](https://passl.bj.bcebos.com/vision_transformers/pvt_v2/xcit_medium_24_p16_224.pdparams) | 82.67 | 95.91 | 1.0 | 84.40M | |
| 54 | +| xcit_large_24_p16_224 | [pretrain 1k](https://passl.bj.bcebos.com/vision_transformers/pvt_v2/xcit_large_24_p16_224.pdparams) | 82.89 | 95.89 | 1.0 | 189.10M | |
| 55 | + |
| 56 | + |
| 57 | +## Usage |
| 58 | + |
| 59 | +```python |
| 60 | +from passl.modeling.backbones import build_backbone |
| 61 | +from passl.modeling.heads import build_head |
| 62 | +from passl.utils.config import get_config |
| 63 | + |
| 64 | + |
| 65 | +class Model(nn.Layer): |
| 66 | + def __init__(self, cfg_file): |
| 67 | + super().__init__() |
| 68 | + cfg = get_config(cfg_file) |
| 69 | + self.backbone = build_backbone(cfg.model.architecture) |
| 70 | + self.head = build_head(cfg.model.head) |
| 71 | + |
| 72 | + def forward(self, x): |
| 73 | + |
| 74 | + x = self.backbone(x) |
| 75 | + x = self.head(x) |
| 76 | + return x |
| 77 | + |
| 78 | + |
| 79 | +cfg_file = "configs/xcit/xcit_nano_12_p8_224.yaml" |
| 80 | +m = Model(cfg_file) |
| 81 | +``` |
| 82 | + |
| 83 | +## Reference |
| 84 | + |
| 85 | +``` |
| 86 | +@article{xcit, |
| 87 | + title={{XCiT}: Cross-Covariance Image Transformers}, |
| 88 | + author={Alaaeldin El-Nouby and Hugo Touvron and Mathilde Caron and Piotr Bojanowski and Matthijs Douze and Armand Joulin and Ivan Laptev and Natalia Neverova and Gabriel Synnaeve and Jakob Verbeek and Hervé Jegou}, |
| 89 | + year={2021}, |
| 90 | + eprint={2106.09681}, |
| 91 | + archivePrefix={arXiv}, |
| 92 | + primaryClass={cs.CV} |
| 93 | +} |
| 94 | +``` |
0 commit comments