You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
# CANedge InfluxDB Writer - Push CAN Bus Data to InfluxDB
2
2
3
-
This project lets you DBC decode CAN data from your CANedge- and push the data into an InfluxDB database. From here, the data can be displayed via your own customized, open source Grafana dashboard.
3
+
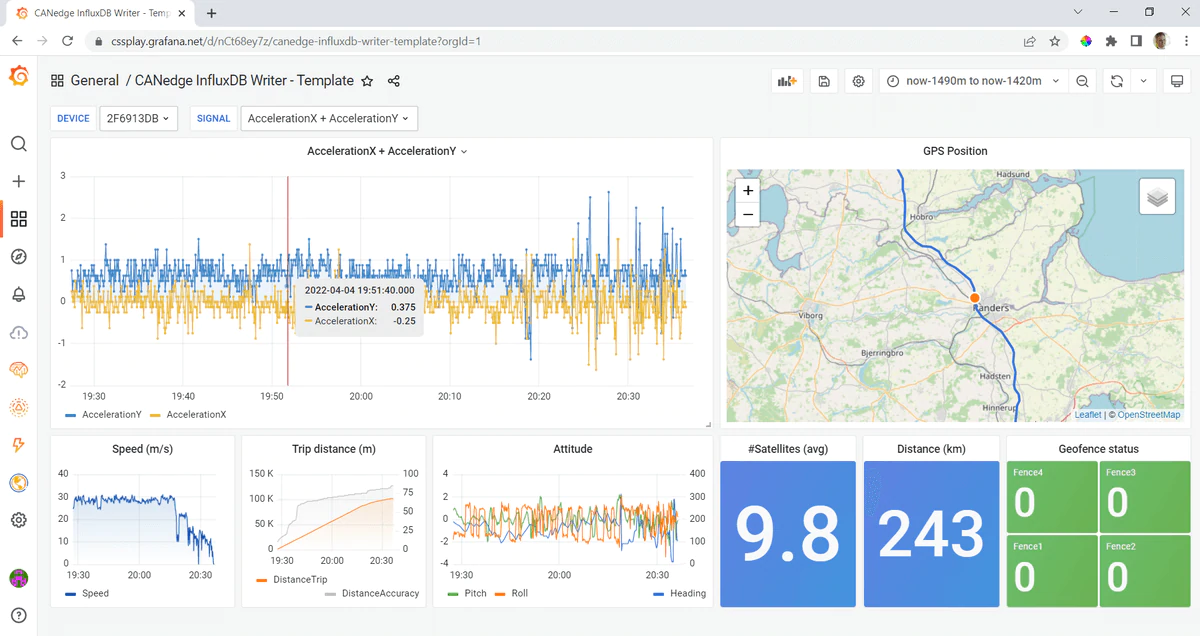
This project lets you DBC decode CAN data from your [CANedge](https://www.csselectronics.com/pages/can-bus-hardware-products) CAN/LIN data logger - and push the data into an InfluxDB database. From here, the data can be visualized in your own customized, open source Grafana dashboards.
4
4
5
5
For the full step-by-step guide to setting up your dashboard, see the [CANedge intro](https://canlogger.csselectronics.com/canedge-getting-started/log-file-tools/browser-dashboards).
6
6
7
+
7
8
8
9
## Backend vs. Writer
9
10
We provide two options for integrating your CANedge data with Grafana dashboards:
@@ -22,89 +23,109 @@ For details incl. 'pros & cons', see our [intro to telematics dashboards](https:
22
23
- fetch data from hardcoded time period - or automate with dynamic periods
23
24
- DBC-decode data and optionally extract specific signals
24
25
- optionally resample data to specific frequency
26
+
- optionally process multi-frame CAN data (ISO TP), incl. UDS, J1939, NMEA 2000
25
27
- write the data to your own InfluxDB time series database
26
28
```
27
-
---
29
+
----
28
30
29
31
## Installation
30
-
We recommend to install Python 3.7 for Windows ([32 bit](https://www.python.org/ftp/python/3.7.9/python-3.7.9.exe)/[64 bit](https://www.python.org/ftp/python/3.7.9/python-3.7.9-amd64.exe)) or [Linux](https://www.python.org/downloads/release/python-379/). Once installed, download and unzip the repository, then navigate to the folder with the `requirements.txt` file.
31
32
32
-
In your explorer path, write `cmd` and hit enter to open your command prompt.
33
+
In this section we detail how to deploy the app on a PC.
33
34
34
-
Next, enter the below and hit enter to install script dependencies:
35
-
36
-
``pip install -r requirements.txt``
37
-
38
-
**Tip:** Watch [this video walkthrough](https://canlogger1000.csselectronics.com/img/dashboard-writer-get-started.mp4) of the above.
35
+
Note: We recommend to test the deployment with our sample data as the first step.
39
36
37
+
----
40
38
41
-
---
42
-
## Test the script
39
+
### 1: Deploy the integration locally on your PC
43
40
44
-
### 1: Test script with sample data
45
-
1. Download this repository incl. the J1939 data and demo DBC
46
-
2. In `inputs.py` add your InfluxDB details, then run `python main.py` via the command line
41
+
#### Install dependencies & write sample data to InfluxDB Cloud
47
42
48
-
*Note: If you use a free InfluxDB Cloud user, the sample data will be removed after a period (as it is >30 days old).*
43
+
- Install Python 3.7 for Windows ([32 bit](https://www.python.org/ftp/python/3.7.9/python-3.7.9.exe)/[64 bit](https://www.python.org/ftp/python/3.7.9/python-3.7.9-amd64.exe)) or [Linux](https://www.python.org/downloads/release/python-379/) (_enable 'Add to PATH'_)
44
+
- Download this project as a zip via the green button and unzip it
45
+
- Open the folder with the `requirements.txt` file
46
+
- Open `inputs.py` with a text editor and add your InfluxDB Cloud details
47
+
- Open your [command prompt](https://www.youtube.com/watch?v=bgSSJQolR0E&t=47s) and enter below
49
48
50
-
### 2: Modify script with your own details
51
-
1. Local disk: Add your own data next to the scripts as per the SD structure:
52
-
`LOG/<device_ID>/<session>/<split>.MF4`
53
-
2. S3 server: Add your S3 server details in `inputs.py` and set `s3 = True`
54
-
3. In `inputs.py` update the DBC path list and the device list to match yours
55
-
4. Optionally modify the signal filters or resampling frequency
56
-
5. On the 1st run, the script will process data starting from `default_start` (you may want to modify this)
There are multiple ways to automate the script execution.
61
+
#### Set up Grafana Cloud
62
62
63
-
### Use task scheduler
64
-
One approach is via periodic execution, triggered e.g. by Windows Task Scheduler or Linux cron jobs. By default, the script is 'dynamic' meaning that it will only process log files that have not yet been added to the InfluxDB database. The script achieves this by fetching the 'most recent' timestamp (across signals) for each device in InfluxDB. The script will then only fetch log files that contain newer data vs. this timestamp.
63
+
- In `Configuration/Plugins` install `TrackMap`
64
+
- In `Dashboards/Browse` click `Import` and load the `dashboard-template-sample-data.json` from this repo
65
65
66
-
If no timestamps are found in InfluxDB for a device, `default_start` is used. Same goes if `dynamic = False` is used. If the script is e.g. temporarily unable to connect to InfluxDB, no log files will be listed for processing.
66
+
You should now see the sample data visualized in Grafana.
67
67
68
-
For details on setting up task scheduler, see the CANedge Intro guide for browser dashboards.
68
+
Note: To activate your virtual environment use `env\Scripts\activate` (Linux: `source env/bin/activate`)
69
69
70
-
### Set up AWS Lambda function
71
-
Antoher approach is to use event based triggers, e.g. via AWS Lambda functions. We provide a detailed description of setting up AWS Lambda functions in the `aws_lambda_example/` sub folder.
70
+
----
72
71
73
-
---
74
-
## Other practical information
72
+
### 3: Load your own data & DBC files
75
73
76
-
### Regarding encrypted log files
77
-
If you need to handle encrypted log files, you can provide a passwords dictionary object with similar structure as the `passwords.json` file used in the CANedge MF4 converters. The object can be provided e.g. as below (or via environmental variables):
74
+
#### Load from local disk
75
+
- Replace the sample `LOG/` folder with your own `LOG/` folder
76
+
- Verify that your data is structured as on the CANedge SD card i.e. `[device_id]/[session]/[split].MF4`
77
+
- Add your DBC file(s) to the `dbc_files` folder
78
+
- Update `devices` and `dbc_paths` in `inputs.py` to reflect your added log and DBC files
79
+
- Set `days_offset = None` to ensure your data is written at the correct date
80
+
- Verify that your venv is active and run the script via `python main.py`
78
81
79
-
```
80
-
pw = {"default": "password"} # hardcoded
81
-
pw = json.load(open("passwords.json")) # from local JSON file
82
-
```
82
+
#### Load from S3
83
+
- Add your DBC file(s) to the `dbc_files` folder
84
+
- Update `dbc_paths` in `inputs.py` to reflect your added log and DBC files
85
+
- Update `devices` in `inputs.py` to reflect your S3 structure i.e. `["bucket/device_id"]`
86
+
- Set `days_offset = None` to ensure your data is written at the correct date
87
+
- Update the S3 details in `inputs.py` with your S3 server and set `s3 = True`
83
88
84
-
### Change timestamps
85
-
If you wish to test the script using old data, you can change the timestamps so that the data is 'rebaselined' to today, minus an offset number of days. This is useful e.g. if you want to use the InfluxDB Cloud Starter, which will delete data that is older than 30 days. To rebaseline your data to start today minus 2 days, simply add `days_offset=2` in the `ProcessData` initialization.
89
+
Note: You may want to modify other variables like adding signal filters, changing the resampling or modifying the default start date.
86
90
87
-
### Change verbosity
88
-
By default, summary information is printed as part of the processing. You can parse `verbose=False` as an input argument in `list_log_files`, `SetupInflux` and `ProcessData` to avoid this.
91
+
#### Import simplified dashboard template
92
+
- To get started, import the `dashboard-template-simple.json` to visualize your own data
93
+
- After this, you can optionally start customizing your panels as explained in the CANedge Intro
89
94
90
-
### Delete data from InfluxDB
91
-
If you need to delete data in InfluxDB that you e.g. uploaded as part of a test, you can use the `delete_influx(name)` function from the `SetupInflux` class. Call it by parsing the name of the 'measurement' to delete (i.e. the device ID):
95
+
----
92
96
93
-
``influx.delete_influx("958D2219")``
97
+
### 4: Move to a production setup
94
98
95
-
### Multiple channels
96
-
If your log files contain data from two CAN channels, you may need to adjust the script in case you have duplicate signal names across both channels. For example, if you're extracting the signal `EngineSpeed` from both channels.
99
+
#### Automation
100
+
There are multiple ways to automate the script execution.
101
+
102
+
##### Use task scheduler
103
+
One approach is via periodic execution, triggered e.g. by Windows Task Scheduler or Linux cron jobs. By default, the script is 'dynamic' meaning that it will only process log files that have not yet been added to the InfluxDB database. The script achieves this by fetching the 'most recent' timestamp (across signals) for each device in InfluxDB. The script will then only fetch log files that contain newer data vs. this timestamp.
104
+
105
+
If no timestamps are found in InfluxDB for a device, `default_start` is used. Same goes if `dynamic = False` is used. If the script is e.g. temporarily unable to connect to InfluxDB, no log files will be listed for processing.
106
+
107
+
For details on setting up task scheduler, see the CANedge Intro guide for browser dashboards.
97
108
98
-
###Advanced processing (custom signals, transport protocol decoding, ...)
99
-
If you need to perform more advanced data processing, you may find useful functions and examples in the api-examples library under `data-processing/`.
109
+
#### Set up an AWS Lambda function
110
+
Another approach is to use event based triggers, e.g. via AWS Lambda functions. We provide a detailed description of setting up AWS Lambda functions in the `aws_lambda_example/` folder. This is recommended if you're uploading data from multiple CANedge2 devices to an S3 server.
100
111
101
-
In particular, see the guide in that repository for including transport protocol handling for UDS, J1939 or NMEA 2000 fast packets.
112
+
----
113
+
114
+
## Other information
102
115
103
-
---
116
+
#### Delete data from InfluxDB
117
+
If you need to delete data in InfluxDB that you e.g. uploaded as part of a test, you can use the `delete_influx(name)` function from the `SetupInflux` class. Call it by parsing the name of the 'measurement' to delete (i.e. the device ID): `influx.delete_influx("958D2219")`
118
+
119
+
#### Multiple channels
120
+
If your log files contain data from two CAN channels, you may need to adjust the script in case you have duplicate signal names across both channels. For example, if you're extracting the signal `EngineSpeed` from both channels.
104
121
105
-
### Add InfluxDB tags
122
+
#### Multi-frame data (ISO TP)
123
+
You can easily process multi-frame data by setting the `tp_type` variable to `"j1939"`, `"uds"` or `"nmea"` and adding the relevant DBC file. For example, you can test this for the sample data by adding the DBC `"dbc_files/nissan_uds.dbc"` and setting `tp_type = "uds"`.
124
+
125
+
#### Add InfluxDB tags
106
126
You can add tags to your data when using InfluxDB. This effectively adds additional dimensions to your data that you can e.g. use to color timeseries based on events or to further segment your queries when visualizing the data. The `utils_db.py` contains a basic example via the `add_signal_tags` functions that you can use as outset for building your own logic.
107
127
108
-
---
109
-
### Regarding InfluxDB and S3 usage costs
128
+
----
129
+
130
+
#### Regarding InfluxDB and S3 usage costs
110
131
Note that if you use the paid InfluxDB cloud and a paid S3 server, we recommend that you monitor usage during your tests early on to ensure that no unexpected cost developments occur.
0 commit comments