|
| 1 | +# 目标检测与跟踪 |
| 2 | + |
| 3 | +## 概述 |
| 4 | + |
| 5 | +主流的目标检测算法主要分为两个类型: |
| 6 | + |
| 7 | +1. two-stage 方法,如 **R-CNN** 系算法,其主要思路是先通过启发式方法(selective search)或者 CNN 网络(RPN)产生一系列稀疏的候选框,然后对这些候选框进行分类与回归,two-stage 方法的优势是准确度高; |
| 8 | +2. one-stage 方法,如 **Yolo 和 SSD**,其主要思路是均匀地在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,然后利用 CNN 提取特征后直接进行分类与回归,整个过程只需要一步,所以其优势是速度快,但是均匀的密集采样的一个重要缺点是训练比较困难,这主要是因为正样本与负样本(背景)极其不均衡,导致模型准确度稍低。不同算法的性能下图所示,可以看到两类方法在准确度和速度上的差异。 |
| 9 | + |
| 10 | +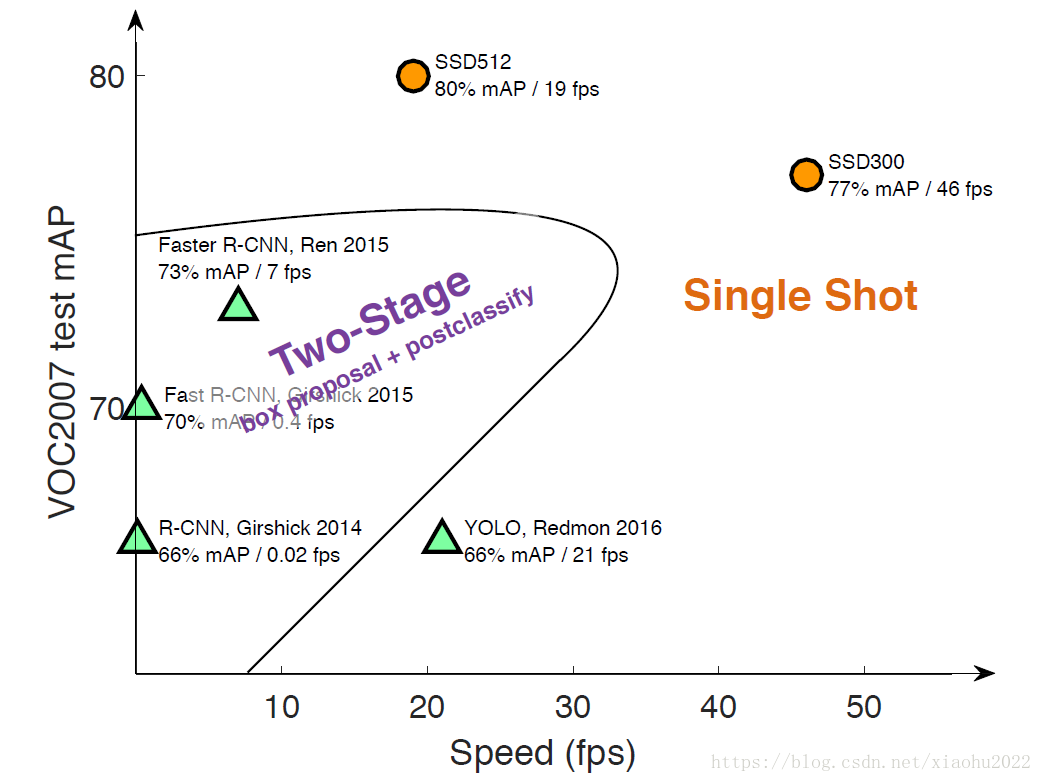 |
| 11 | + |
| 12 | +从上图可以看到,SSD 算法在准确度和速度(除了 SSD512)上都比 Yolo 要好很多。 |
| 13 | + |
| 14 | +## YOLO 算法的优缺点 |
| 15 | + |
| 16 | +### 优点 |
| 17 | + |
| 18 | +1. **速度快**,基本 YOLO 模型达到 45FPS,Fast YOLO 模型达到 45FPS。 |
| 19 | + |
| 20 | +2. YOLO 使用图像的全局信息做预测,因而对背景的误识别率比 Fast R-CNN 低。 |
| 21 | + |
| 22 | +3. YOLO 学习到的特征更加通用,在艺术品的检测上准确率高于 DPM 和 R-CNN。 |
| 23 | + |
| 24 | +## 缺点 |
| 25 | + |
| 26 | +1. YOLO 虽然能够达到实时的效果,但是其**mAP** 与刚面提到的 state of art 的结果有很大的差距。 |
| 27 | +2. 每个网格只预测一个物体,容易造成漏检 |
| 28 | +3. YOLO **对于物体的尺度相对比较敏感**,对于尺度变化较大的物体泛化能力较差 |
| 29 | + |
| 30 | +## SSD 介绍 |
| 31 | + |
| 32 | +SSD(Single Shot MultiBox Detecto) 方法是基于一个前馈的卷积网络,该网络产生一个固定大小的包围框集合,并对这些框中存在的对象类别进行评分,然后利用非极大值抑制方法产生最后的检测结果。前期的网络层基于一些用来进行高质量图片分类的标准结构,我们称之为基础网络。然后我们在其中加入了一些辅助结构来产生检测结果。从图 1 可以看到,SSD 算法在准确度和速度(除了 SSD512)上都比 Yolo 要好很多。 |
| 33 | + |
| 34 | +## 优缺点 |
| 35 | + |
| 36 | +优点:能通过在不同层级选用不同尺寸、不同比例的 anchor,能够找到与 ground truth 匹配最好的 anchor 来进行训练,从而使整个结构的精确度更高。 |
| 37 | + |
| 38 | +缺点是**对小尺寸的目标识别仍比较差**,还达不到 Faster R-CNN 的水准。这主要是因为小尺寸的目标多用较低层级的 anchor 来训练(因为小尺寸目标在较低层级 IOU 较大),较低层级的特征非线性程度不够,无法训练到足够的精确度。 |
| 39 | + |
| 40 | +### SSD 性能评估 |
| 41 | + |
| 42 | +#### SSD 在不同数据集上的性能 |
| 43 | + |
| 44 | +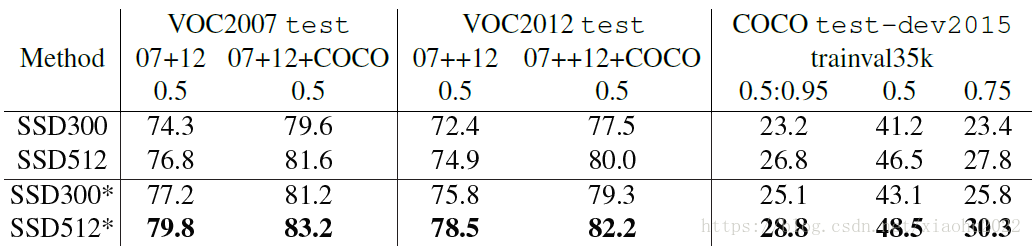 |
| 45 | + |
| 46 | +#### SSD 与其他算法的对比结果 |
| 47 | + |
| 48 | + |
| 49 | + |
| 50 | +## 对比 |
| 51 | + |
| 52 | +SSD 在 Yolo 的基础上主要改进了三点: |
| 53 | + |
| 54 | +- 多尺度特征图 |
| 55 | +- 利用卷积进行检测 |
| 56 | +- 设置先验框 |
| 57 | + 这使得 SSD 在准确度上比 Yolo 更好. |
| 58 | + |
| 59 | +# Opencv 人脸检测 |
| 60 | + |
| 61 | +## Haar 特征级联表 |
| 62 | + |
| 63 | +OpenCV 在物体检测上使用的是 **haar 特征的级联表**,这个级联表中包含的是 **boost 的分类器**。首先,人们采用样本的 haar 特征进行分类器的训练,从而得到一个级联的 boost 分类器。 |
| 64 | + |
| 65 | +**Haar 分类器算法的要点如下**: |
| 66 | + |
| 67 | +1. 使用 Haar-like 特征做检测。 |
| 68 | + |
| 69 | +2. 使用积分图(Integral Image)对 Haar-like 特征求值进行加速。 |
| 70 | + |
| 71 | +3. 使用 AdaBoost 算法训练区分人脸和非人脸的强分类器。 |
| 72 | + |
| 73 | +4. 使用筛选式级联把强分类器级联到一起,提高准确率。 |
| 74 | + |
| 75 | +**级联分类器**是由若干个简单分类器级联成的一个大的分类器,被检测的窗口依次通过每一个分类器,可以通过所有分类器的窗口即可判定为目标区域。同时,为了考虑效率问题,可以将最严格的分类器放在整个级联分类器的最顶端,减少匹配次数。 |
| 76 | +人脸的 Haar 特征分类器就是一个 XML 文件,该文件中会描述人脸的 Haar 特征值。 |
| 77 | + |
| 78 | +## AdaBost 算法 |
| 79 | + |
| 80 | +AdaBost 算法是对传统 Boosting 算法的一大提升。AdaBoost 是自适应 Boosting 算法,利用 AdaBoost 算法可以选择更好的矩阵特征组合,即分类器,分类器将矩阵组合以二叉决策树的形式存储起来。 |
| 81 | + |
| 82 | +## Opencv 人脸检测步骤 |
| 83 | + |
| 84 | +- SSD 算法检测到人物轮廓,将此部分区域作为输入值 |
| 85 | +- 彩色图片转化为灰度图片 |
| 86 | +- 进行灰度图直方图均衡化操作 |
| 87 | +- 检测人脸 |
| 88 | + |
| 89 | +## 运行效果图 |
| 90 | + |
| 91 | +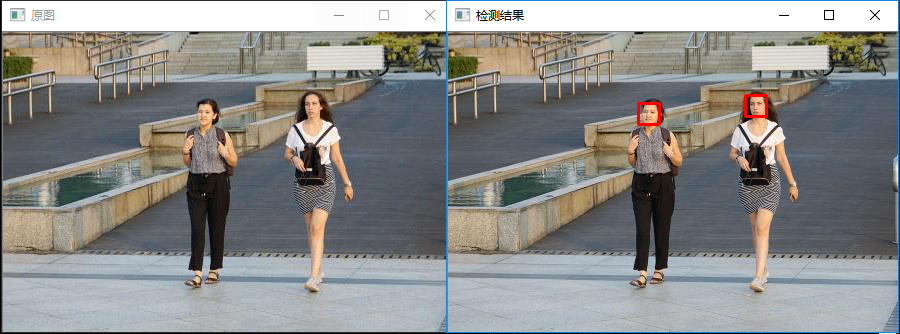 |
| 92 | + |
| 93 | +目标跟踪: |
| 94 | + |
| 95 | +# 实时目标跟踪 |
| 96 | + |
| 97 | +## KNN 背景分割器 |
| 98 | + |
| 99 | +OpenCV 提供了一类背景分割器 BackgroundSubtractor ,是专门用来视频分析的,会对视频中的每一帧进行“学习”,比较,计算阴影,排除检测图像的阴影区域,按照时间推移的方法提高运动分析的结果。而且 BackgroundSubtractor 不仅可以用于背景分割,而且还可以提高背景检测的效果。在 opencv 中有三种分割器:KNN,MOG2,GMG。本次设计采用 KNN 进行动态物体背景检测。 |
| 100 | + |
| 101 | +**KNN 动态目标检测流程**: |
| 102 | + |
| 103 | +``` |
| 104 | +1. 定义1个KNN背景分割器对象 |
| 105 | +2. 定义视频对象 |
| 106 | +
|
| 107 | +while True: |
| 108 | + 3. 一帧帧读取视频 |
| 109 | + 4. 计算前景掩码 |
| 110 | + 5.二值化操作 |
| 111 | + 6.膨胀操作 |
| 112 | + 7.查找轮廓 |
| 113 | + 8.轮廓筛选 |
| 114 | + 9.画出轮廓(在原图像) |
| 115 | + 10.显示图像帧 |
| 116 | +``` |
| 117 | + |
| 118 | +动态检测效果图: |
| 119 | + |
| 120 | + |
| 121 | +## 跟踪算法 |
| 122 | + |
| 123 | +opencv 中总共有 8 种目标跟踪算法,分别是`BOOSTING、MIL、KCF、TLD、MEDIANFLOW、GOTURN、CSRT`和`MOSSE`。 |
| 124 | + |
| 125 | +[Adrian Rosebrock 的 OpenCV Object Tracking 原文](https://www.pyimagesearch.com/2018/07/30/opencv-object-tracking/) |
| 126 | + |
| 127 | +简要分析: |
| 128 | + |
| 129 | +1. BOOSTING Tracker |
| 130 | + 该算法是基于机器学习汇总我的 Haar 级联(Adaboost)算法,是一种较为**落后**的一种方法,**比较慢**,性能也不是很好,主要用来做算法的比较和基准。(>opencv3.0.0) |
| 131 | + |
| 132 | +2. MIL Tracker |
| 133 | + **比 boosting 具有更好的准确率**,但是存在报错的几率。(>opencv3.0.0) |
| 134 | + |
| 135 | +3. KCF Tracker |
| 136 | + 核相关滤波算法,**比上述两种都要快**,但是偶然因素下存在失效。(>opencv3.1.0) |
| 137 | + |
| 138 | +4. CSRT Tracker |
| 139 | + 判别相关滤波算法,具有通道和空间可靠性,**比 KCF 准确率更高,但是相对慢**。(>opencv3.4.2) |
| 140 | + |
| 141 | +5. MedianFlow Tracker |
| 142 | + 失效性能良好,然后如果目标变动过大,**移动过快,容易丢失目标**。(>opencv3.0.0) |
| 143 | + |
| 144 | +6. TLD Tracker |
| 145 | + 有一定的假正率,不推荐使用该种 OpenCV 目标跟踪方法。 |
| 146 | + |
| 147 | +7. MOSSE Tracker |
| 148 | + **非常非常快**,但是准确率没有 CSRT 和 KCF 高,如果对帧率要求很高,这是可行的方法。 |
| 149 | + |
| 150 | +8. GOTURN Tracker |
| 151 | + 这种**唯一一个使用深度学习的 OpenCV 的方法**。需要额外的模型文件 caffe 网络结构文件 caffemode+prototext,并且基于 caffe 框架。 |
| 152 | + |
| 153 | +## 效果图 |
| 154 | + |
| 155 | + |
| 156 | + |
| 157 | +### 使用建议 |
| 158 | + |
| 159 | +- 使用 CSRT 当需要非常高的跟踪**准确率**,并且可以容忍慢一些的帧率,但是更**耗时**一点 |
| 160 | + |
| 161 | +- 使用 KCF,当需要**较快的 FPS**,但同时能够容忍轻微弱的准确率。 |
| 162 | + |
| 163 | +- 使用 MOSSE,当需要**非常高的 FPS**场景时。 |
0 commit comments